
Tabla de contenidos
- Prólogo
- Conceptos básicos de TDD
-
TDD clásica
- 4 Las leyes de TDD
- 5 Fizz Buzz
-
6 Resolviendo la kata Fizz Buzz
- Enunciado de la kata
- Lenguaje y enfoque
- Definir la clase
-
Definir el método
generate -
Definir un comportamiento para
generate - Generar una lista de números
- Seguimos generando números
- El test que no falla
- Aprendiendo a decir “Fizz”
- Decir “Fizz” cuando toca
- Aprendiendo a decir “Buzz”
- Decir “Buzz” cuando toca
- Aprender a decir “FizzBuzz”
- Decir “FizzBuzz” cuando toca
- Finalizando
- Qué hemos aprendido con esta kata
- 7 Elección de los ejemplos y criterio de finalización
- 8 Evolución del comportamiento mediante tests
- 9 Prime Factors
-
10 Resolviendo la kata Prime Factors
- Enunciado de la kata
- Lenguaje y enfoque
- Definir la función
- Definir la signatura de la función
- Obteniendo más información sobre el problema
- Introduciendo un test que no falla
- Cuestionando nuestro algoritmo
- Descubriendo los múltiplos de 2
- Introduciendo más factores
- Nuevos divisores
- El camino más corto no siempre es el más rápido
- Introduciendo nuevos factores, segundo intento
- Más de dos factores
- ¿Tenemos criterios para elegir buenos ejemplos?
- Qué hemos aprendido con esta kata
- 11 La elección del primer test
- 12 NIF
-
13 Resolviendo la Kata NIF
- Enunciado de la kata
- Lenguaje y enfoque
- Creando la función constructora
- Implementar la primera validación
- Un test para dominarlos a todos
- Completar la validación de la longitud y empezar a examinar la estructura
-
Unificar la validación por longitud del
string - Avanzando en la estructura
- Invertir la condicional
- El final de la estructura
- Compactando el algoritmo
- Terminando la validación estructural
- Compactando la validación
- Seamos optimistas
- Cambiando la interfaz pública
- Ahora sí
- Avanzando el algoritmo
- Más refactor
- Validando más letras de control
- Un refactor para más simplicidad
- Dar soporte a NIE
- Qué hemos aprendido con esta kata
- Referencias
- 14 La fase de refactor
- 15 Bowling game
-
16 Resolviendo la kata Bowling Game
- Enunciado de la kata
- Lenguaje y enfoque
- Iniciando el juego
- Lancemos la bola
- Hora de refactorizar
- Contando los puntos
- El peor lanzador del mundo
- Organizando el código
- Enseñando a contar a nuestro juego
- Un paso atrás para llegar más lejos
- Recuperando un test anulado
- Poniéndonos más cómodas
- Cómo manejar un spare
- Introduciendo el concepto de frame
- Seguimos manejando el spare
- Eliminando números mágicos y otros refactors
- Strike!
- Reorganizando el conocimiento del juego
- La mejor jugadora del mundo
- Qué hemos aprendido con esta kata
- 17 Greeting
-
18 Resolviendo la kata Greetings
- Enunciado de la kata
- Lenguaje y enfoque
- Saludo básico
- Saludo genérico
- Usar el parámetro
- Un saludo genérico
- Responder a gritos
- Poder saludar a dos personas
- Preparándose para varios nombres
- Un refactor antes de seguir
- Reintroduciendo un test
- Manejar un número indeterminado de nombres
- Gritar a los gritones, pero solo a ellos
- Separar nombres que contienen comas
- Escapar comas
- Qué hemos aprendido con esta kata
- Outside-in TDD
- TDD en la vida real
- Epílogo
- Notas
Prólogo
Cómo usar este libro
No hay una forma correcta, o incorrecta si vamos a eso, de leer este libro. Todo depende de tus intereses.
Para empezar, se estructura en cuatro partes principales que pueden leerse separadamente:
En la primera se introducen los conceptos básicos de TDD, así como algunas estrategias para aprender a usar e introducir esta disciplina en tu práctica.
En la segunda, se presenta una selección de katas o ejercicios de código con la que se explican en profundidad los conceptos y técnicas de Test Driven Development en su definición clásica. Van desde las que son muy conocidas hasta algunas propias.
Cada una de las katas se organiza de la siguiente forma:
- Un capítulo teórico dedicado a un aspecto destacado de TDD puesto de relieve por esa kata y sobre el que he incidido especialmente al resolverla.
- Una introducción a la kata, su origen si es conocido, su enunciado y una serie de recomendaciones o puntos de interés sobre la misma.
- Una solución desarrollada en un lenguaje de programación diferente y explicada en detalle. Hay un repositorio con soluciones a las katas en varios lenguajes.
La tercera parte introduce la metodología outside-in TDD. Outside-in TDD es una propuesta en la que se busca potenciar la fase de diseño, y que se puede aplicar al desarrollo en proyectos reales.
La cuarta parte está orientada a mostrar un ejemplo de un proyecto realista y cómo se puede incorporar TDD en las distintas etapas de desarrollo y mantenimiento, desde la creación de un producto mínimo viable (MVP) a la resolución de defectos y la incorporación de nuevas características.
Si estás buscando un manual para aprender TDD desde cero, mi recomendación sería leerlo en orden. Los ejercicios de código están dispuestos para introducir los conceptos en una progresión determinada, a la que he llegado por experiencia personal y cuando he enseñado a otras personas a usar TDD.
Al principio, puede parecerte que los ejercicios de TDD son muy triviales y poco realistas. Ten presente que el nombre de Kata no es casual. Una Kata, en artes marciales, es un ejercicio repetitivo que se ejecuta hasta automatizar sus movimientos y más allá. Si practicas algún deporte habrás realizado decenas de ejercicios destinados a ganar flexibilidad, fuerza, movilidad y automatismos, sin que tengan una aplicación directa en ese deporte concreto. Las Katas de TDD tienen esa misma función: preparan tu cerebro para automatizar ciertas rutinas, generar determinados hábitos y conseguir detectar patrones particulares en el proceso de desarrollo.
Posiblemente, el enfoque outside-in te parezca mucho más aplicable a tu trabajo diario. De hecho, es una forma de desarrollar proyectos usando TDD. Sin embargo, una base sólida en TDD clásico es fundamental para tener éxito usando este enfoque. Outside-in está muy próximo al Behavior Driven Development.
Como se ha mencionado antes, las distintas partes y ejercicios son relativamente independientes. Si ya tienes cierta experiencia con la disciplina del Test Driven Development, puedes ir directamente a los apartados o ejercicios que te interesen. Con frecuencia descubrirás algo nuevo. Una de las cosas que me he encontrado es que siempre acaba apareciendo alguna idea nueva aunque hayas realizado el mismo ejercicio decenas de veces.
Si buscas cómo introducir TDD en tu proceso de trabajo o en el de tu equipo, es posible que vayas directamente a la parte sobre TDD en la vida real. Es la que tiene, por así decir, más dependencia en conocimientos y experiencia previa. En ese caso, si consideras que te falta soltura en TDD posiblemente debas echar un vistazo a otras partes del libro.
Para alcanzar un buen nivel de desempeño en TDD deberías practicar los ejercicios muchas veces. No hablo de tres o cuatro, estoy hablando de decenas de veces, en distintos momentos de tu vida profesional e, idealmente, en distintos lenguajes. Existen varios repositorios de katas en los que encontrar ejercicios, y puedes inventar o descubrir los tuyos propios.
También es recomendable ver cómo otras personas realizan estos ejercicios. En la web están disponibles montones de ejemplos de Katas realizadas en una variedad de lenguajes de programación, y es una gran forma de contrastar tus soluciones y tu proceso.
Y, por supuesto, pero no en último lugar, una de las mejores formas de aprender es practicar con otras personas. Ya sea en proyectos de trabajo, formaciones o comunidades de práctica. Debatir en vivo las soluciones, el tamaño de los pasos, el comportamiento a testear, contribuirá a pulir y fortalecer vuestro proceso de desarrollo.
Asunciones
Para este libro se asumen algunos supuestos:
- Que tienes cierta experiencia en algún lenguaje de programación y un entorno de testing de ese lenguaje. En otras palabras: sabes escribir y ejecutar tests. No importa que tu lenguaje preferido no esté contemplado en este libro.
- Los ejemplos del libro están en varios lenguajes y en la medida de lo posible se evita usar características muy específicas. De hecho, soy novato en muchos de ellos, por lo que el código puede parecer muy simplón. Por otro lado, esto es algo deseable en TDD, como verás a lo largo del libro.
- Tienes claro que el objetivo de los ejercicios de código no es tanto resolver el problema planteado como tal, que finalmente se resuelve, sino el proceso por el que llegamos a esa solución.
- Entiendes que no existe una solución única, ni un camino preciso en la resolución de las katas. Si tu solución no coincide con la planteada en este libro, no es ningún problema.
Disclaimer
Las soluciones propuestas a las katas se proporcionan como ejemplos explicados de los procesos de razonamiento que se podrían seguir. No son soluciones ideales. Cuando realices tu versión podrías seguir un proceso completamente diferente que podría ser tan válido o más que el presentado aquí.
Por otra parte, sucesivas ejecuciones de una misma kata por la misma persona podrían llevarla a soluciones y recorridos diferentes. Ese es uno de sus beneficios: al acostumbrarnos a ciertos patrones de pensamiento y automatizarlos podemos prestar atención a más detalles cada vez y encontrar puntos de intervención más interesantes.
Igualmente, a medida que se incrementa nuestra fluidez en un lenguaje de programación, las implementaciones que logramos pueden ser mejores y más elegantes.
Al preparar las katas presentadas en este libro he realizado varias versiones, incluso en distintos lenguajes a fin de encontrar los recorridos más interesantes o incluso provocar algunos problemas que me interesaba poner de manifiesto. La solución que he decidido publicar en cada caso está cargada hacia algún punto que me interesaba acentuar del proceso de TDD por lo que podría no ser la óptima.
Es decir, en cierto modo las katas tienen trampa, se trata de forzar las cosas hasta cierto punto para lograr un objetivo didáctico.
En otro orden de cosas, he aprovechado este proyecto para forzarme a experimentar con lenguajes de programación diferentes. En algunos casos, son lenguajes nuevos para mí o con los que no estoy acostumbrado a trabajar, por lo que es posible que las implementaciones sean especialmente toscas o que no incluyan algunas de sus características más específicas y óptimas.
Conceptos básicos de TDD
En esta primera parte, introduciremos los conceptos básicos para entender qué es Test Driven Development y en qué se diferencia de otras disciplinas y metodologías que utilizan tests. También hablaremos de cómo puedes aprender TDD, ya sea individualmente o en un equipo o comunidad de práctica.
En el primer capítulo se hace una introducción general al proceso de test driven development.
El capítulo sobre conceptos básicos es un glosario de términos que usaremos a lo largo del libro.
Finalmente, el capítulo sobre coding-dojo y katas propone algunas ideas sencillas para empezar a practicar en equipo o individualmente.
1 ¿Qué es TDD y por qué debería importarme?
Test Driven Development es una metodología de desarrollo de software en la que se escriben tests para guiar la escritura del código de producción.
Los tests especifican de manera formal, ejecutable y mediante ejemplos, los comportamientos que debe realizar el software que estamos programando, definiendo pequeños objetivos que, al ser superados, nos permiten construir el software de forma progresiva, segura y estructurada.
Aunque hablemos de tests, no estamos hablando de Quality Assurance (en adelante: QA), aunque al trabajar con metodología TDD conseguimos el efecto secundario de hacernos con una suite de tests unitarios que es válida y que tiene la máxima cobertura posible. De hecho, lo normal es que una parte de los tests creados en TDD sean innecesarios para una batería comprensiva de tests de regresión, por lo que es habitual eliminarlos a medida que nuevos tests los convierten en redundantes.
Es decir: tanto TDD como QA se basan en la utilización de los tests como herramientas, pero este uso se diferencia en varios aspectos. Específicamente, en TDD:
- El test se escribe antes de que el software que ejecuta siquiera exista.
- Los tests son muy pequeños y su objetivo es forzar la escriture del código de producción mínimo necesario para que el test pase, que tiene el efecto de implementar el comportamiento definido por el test.
- Los tests guían el desarrollo del código y el proceso contribuye al diseño del sistema.
En TDD los tests se definen como especificaciones ejecutables del comportamiento de la unidad de software considerada, mientras que en QA el test es una herramienta de verificación de ese mismo comportamiento. Expresado de manera más sencilla:
- Cuando hacemos QA pretendemos comprobar que el software que hemos escrito se comporta según los requisitos definidos.
- Cuando hacemos TDD escribimos software para que cumpla los requisitos definidos, uno por uno, de modo que terminamos con un producto que los cumple.
La metodología Test Driven Development
Aunque a lo largo del libro vamos a desarrollar este apartado en profundidad presentaremos brevemente lo esencial de la metodología.
En TDD los tests se escriben en una forma que podríamos considerar como de diálogo con el código de producción. Este diálogo, las normas que lo regulan y los ciclos que esta forma de interactuar con el código genera los practicaremos con la primera kata del libro: FizzBuzz.
Básicamente se trata de:
- Escribir un test que falla
- Escribir código que haga que el test pase
- Mejorar la estructura del código (y del test)
Escribir un test que falle
Una vez que tenemos claro la pieza de software en la que vamos a trabajar y la funcionalidad que queremos implementar, lo primero es definir un primer test muy pequeño que fallará sin remedio porque ni siquiera existe un archivo que contenga el código de producción necesario para que se pueda ejecutar. Aunque es algo que trataremos en todas las katas, en la kata NIF profundizaremos en estrategias que nos servirán para decidir los primeros tests.
He aquí un ejemplo en Go:
// roman/roman_test.go
package roman
import "testing"
func TestRomanNumeralsConversion(t *testing.T) {
roman := decToRoman(1)
if roman != "I" {
t.Errorf(
"Decimal %d should convert to %s, but found %s",
1,
"I",
roman
)
}
}
Aunque podemos predecir que el test ni siquiera podrá compilarse o interpretarse, lo intentaremos ejecutar igualmente. En TDD es fundamental ver que los tests fallan, no basta con suponerlo. Nuestro trabajo es hacer que el test falle por la razón correcta y luego hacerlo pasar escribiendo código de producción.
# tddbook-go/roman [tddbook-go/roman.test]./roman_test.go:6:11: undefined: decToRomanCompilation finished with exit code 2El mensaje de error nos indicará qué es lo que tenemos que hacer a continuación. Nuestro objetivo a corto plazo es hacer desaparecer ese mensaje de error y los que puedan venir después, uno por uno.
package roman
import "testing"
func TestRomanNumeralsConversion(t *testing.T) {
roman := decToRoman(1)
if roman != "I" {
t.Errorf(
"Decimal %d should convert to %s, but found %s",
1,
"I",
roman
)
}
}
func decToRoman(decimal int) string {
}
Por ejemplo, al introducir la función decToRoman, el error cambiará. Ahora nos dice que debería devolver un valor:
# tddbook-go/roman [tddbook-go/roman.test]./roman_test.go:16:1: missing return at end of functionCompilation finished with exit code 2Podría ocurrir incluso que sea un mensaje inesperado, como que hemos querido cargar la clase Book y resulta que hemos creado un archivo brok por error. Por eso es tan importante lanzar el test y ver si falla y cómo falla exactamente.
package roman
import "testing"
func TestRomanNumeralsConversion(t *testing.T) {
roman := decToRoman(1)
if roman != "I" {
t.Errorf(
"Decimal %d should convert to %s, but found %s",
1,
"I",
roman
)
}
}
func decToroman(decimal int) string {
}
Este código da lugar al siguiente mensaje:
# tddbook-go/roman [tddbook-go/roman.test]./roman_test.go:6:11: undefined: decToRoman./roman_test.go:16:1: missing return at end of functionCompilation finished with exit code 2Este error nos indica que hemos escrito incorrectamente el nombre de la función, así que primero lo corregimos:
package roman
import "testing"
func TestRomanNumeralsConversion(t *testing.T) {
roman := decToRoman(1)
if roman != "I" {
t.Errorf(
"Decimal %d should convert to %s, but found %s",
1,
"I",
roman
)
}
}
func decToRoman(decimal int) string {
}
Y podemos continuar. Como el test dice que espera que al pasar 1 a la función nos devuelva “I”, el test fallido debería indicarnos que no coincide el resultado recibido con el esperado. Pero, de momento, el test nos está diciendo que la función no devuelve nada. Todavía es un fallo de compilación y todavía no es la razón correcta para fallar.
# tddbook-go/roman [tddbook-go/roman.test]./roman_test.go:16:1: missing return at end of functionCompilation finished with exit code 2Para conseguir que el test falle por la razón que esperamos, tenemos que hacer que la función devuelva un string, aunque sea vacío:
package roman
import "testing"
func TestRomanNumeralsConversion(t *testing.T) {
roman := decToRoman(1)
if roman != "I" {
t.Errorf(
"Decimal %d should convert to %s, but found %s",
1,
"I",
roman
)
}
}
func decToRoman(decimal int) string {
return ""
}
Y este cambio hace que el error ahora sea uno relacionado con que el test no pasa, pues no obtiene el resultado que espera. Esta es la razón correcta para fallar, la que nos forzará a escribir código de producción que haga pasar el test:
=== RUN TestRomanNumeralsConversion--- FAIL: TestRomanNumeralsConversion (0.00s) roman_test.go:9: Decimal 1 should convert to I, but found
FAILProcess finished with exit code 1Y así estaríamos listas para dar el siguiente paso:
Escribir código que haga que el test pase
Como respuesta al resultado anterior, se escribe el código de producción necesario para que el test pase, pero nada más. Siguiendo con nuestro ejemplo:
package roman
import "testing"
func TestRomanNumeralsConversion(t *testing.T) {
roman := decToRoman(1)
if roman != "I" {
t.Errorf(
"Decimal %d should convert to %s, but found %s",
1,
"I",
roman
)
}
}
func decToRoman(decimal int) string {
return "I"
}
Tras hacer pasar el primer test podemos empezar creando el archivo que contendrá la unidad bajo test. Podríamos incluso volver a lanzar el test ahora, lo cual seguramente provocará que el compilador o intérprete nos devuelva un mensaje de error distinto. Aquí ya dependemos un poco de circunstancias, como las convenciones del lenguaje en que estamos desarrollando, el IDE con el que trabajamos, etc.
En todo caso, se trata de ir dando pequeños pasos hasta que el compilador o intérprete quede conforme y pueda ejecutar el test. En principio, el test debería ejecutarse y fallar indicando que el resultado recibido de la unidad de software no coincide con el esperado.
En este punto hay que hacer una salvedad porque dependiendo del lenguaje, del framework y de algunas prácticas en testing, la forma concreta de este primer test puede ser un poco distinta. Por ejemplo, hay frameworks de test en los que basta con que la ejecución del test no arroje errores o excepciones para considerar que pasa, por lo que un test que simplemente instancia un objeto o invoca uno de sus métodos sería suficiente. En otros casos, es necesario que el test incluya una aserción y si no se hace ninguna considera que el test no pasa.
En cualquier caso, el objetivo de esta fase es lograr que el test se ejecute con éxito.
Con la kata Prime Factors estudiaremos el modo en que puede cambiar el código de producción para incorporar nueva funcionalidad.
Mejorar la estructura del código (y del test)
Cuando se ha logrado hacer pasar cada test debemos examinar el trabajo realizado hasta el momento y comprobar si es posible refactorizar tanto el código de producción como el de test. Aquí aplicamos los principios habituales: si detectamos cualquier smell, dificultad para entender lo que ocurre, duplicación de conocimiento, etc. debemos refactorizar el código para ponerlo en mejor estado antes de continuar.
En el fondo, las preguntas en este momento son:
- ¿Hay alguna manera mejor de organizar el código que he escrito?
- ¿Hay alguna manera mejor de expresar lo que este código hace y que sea más fácil de entender?
- ¿Puedo encontrar alguna regularidad y hacer que el algoritmo sea más general?
Para ello debemos mantener todos los tests que hayamos escrito pasando. Si alguno de los tests se pone en rojo tendríamos una regresión y habríamos estropeado, por así decir, la funcionalidad ya creada.
Tras el primer ciclo es normal no encontrar muchas oportunidades de refactor, pero no te fíes: siempre hay otra manera de ver y hacer las cosas. Por regla general, cuanto antes detectes oportunidades de reorganizar y limpiar el código y lo hagas, más fácil será el desarrollo.
Por ejemplo, nosotros hemos creado la función bajo test en el mismo archivo del test.
package roman
import "testing"
func TestRomanNumeralsConversion(t *testing.T) {
roman := decToRoman(1)
if roman != "I" {
t.Errorf(
"Decimal %d should convert to %s, but found %s",
1,
"I",
roman
)
}
}
func decToRoman(decimal int) string {
return "I"
}
Resulta que hay una forma mejor de organizar ese código y es crear un archivo que contenga la función. De hecho, es una práctica recomendada en casi todos los lenguajes de programación. Sin embargo, al principio nos la podemos saltar.
//roman/roman.go
package roman
func decToRoman(decimal int) string {
return "I"
}
Y, en el caso de Go, podemos convertirla en una función exportable si su nombre comienza con mayúsculas.
package roman
func DecToRoman(decimal int) string {
return "I"
}
Para profundizar en todo lo que tiene que ver con el refactor al trabajar tendremos la kata Bowling Game.
Repetir el ciclo hasta terminar
Una vez que el código de producción hace pasar el test y está lo mejor organizado posible en esa fase, es el turno de escoger otro aspecto de la funcionalidad y crear un nuevo test que falle para describirlo.
Este nuevo test falla porque el código existente no cubre la funcionalidad deseada y es necesario introducir un cambio. Por tanto, nuestra misión ahora es poner este nuevo test en verde haciendo las transformaciones necesarias en el código, las cuales serán pequeñas si hemos sabido dimensionar correctamente nuestros tests anteriores.
Tras conseguir que el nuevo test pase, buscamos las oportunidades de refactor para tener un mejor diseño del código. A medida que avancemos en el desarrollo de la pieza de software veremos que los refactors posibles van siendo más significativos.
En los primeros ciclos comenzaremos con cambios de nombres, extracción de constantes y variables, etc. Luego pasaremos a introducir métodos privados o extraer ciertos aspectos a funciones. En algún momento descubriremos la necesidad de extraer funcionalidad a clases colaboradoras, etc.
Cuando estemos satisfechas con el estado del código repetimos el ciclo mientras nos queda funcionalidad por añadir.
¿Cuándo termina el desarrollo en TDD?
La respuesta obvia podría ser: cuando toda la funcionalidad está implementada.
Pero, ¿cómo sabemos esto?
Kent Beck proponía hacer una lista con todos los aspectos que habría que conseguir para considerar completa la funcionalidad. Cada vez que se consigue alguno se tacha de la lista. A veces, al progresar en el desarrollo nos damos cuenta de la necesidad de añadir, quitar, o mover, elementos en la lista. Es una buena recomendación.
Existe una manera más formal de asegurarnos de que una funcionalidad está completa. Básicamente, consiste en no ser capaz de crear un nuevo test que falle. En efecto, si un algoritmo está completamente implementado será imposible crear un test nuevo que pueda fallar.
Qué no es Test Driven Development
El resultado o outcome de Test Driven Development no es crear un software libre de defectos, aunque se previenen muchos de ellos; ni generar una suite de tests unitarios, aunque en la práctica se obtiene una con gran cobertura que puede llegar al 100%, con la contrapartida de que puede presentar redundancia. Pero nada de esto es el objetivo de TDD, en todo caso es un efecto colateral ciertamente beneficioso.
TDD no es Quality Assurance
Aunque usamos las mismas herramientas (tests), las usamos para finalidades distintas. Los tests en TDD guían el desarrollo, estableciendo objetivos específicos para alcanzar añadiendo código o aplicando cambios en él. El resultado de TDD es una suite de tests que puede utilizarse en QA como tests de regresión, aunque es frecuente que tengamos que retocar esos tests de una manera u otra. En unos casos para eliminar tests redundantes y en otros para asegurar que las casuísticas están bien cubiertas.
En cualquier caso, TDD ayuda enormemente el proceso de QA porque previene muchos de los defectos más comunes y contribuye a construir un código bien estructurado y con bajo acoplamiento, aspectos que incrementan la fiabilidad del software, nuestra capacidad para intervenir en caso de errores e incluso la posibilidad de crear nuevos tests en un future.
TDD no reemplaza el diseño
TDD es una herramienta para contribuir al diseño de software, pero no lo reemplaza.
Cuando desarrollamos unidades pequeñas y con una funcionalidad muy bien definida, TDD nos ayuda a establecer el diseño del algoritmo gracias a la red de seguridad proporcionada por los tests que vamos creando.
Pero cuando la unidad considerada es mayor, un análisis previo que nos lleve a un “boceto” de los elementos principales de la solución nos permite tener un marco de desarrollo.
El enfoque outside-in intenta integrar el proceso de diseño en el desarrollo, usando lo que Sandro Mancuso etiqueta como Just-in-time design: partimos de una idea general de cómo se estructura y de cómo funcionará el sistema y diseñamos en el ámbito de la iteración en la que nos encontremos.
En qué nos ayuda TDD
Lo que TDD nos proporciona es una herramienta que:
- Guía el desarrollo del software de una forma sistemática y progresiva.
- Nos permite realizar afirmaciones contrastables sobre si la funcionalidad requerida ha sido implementada o no.
- Nos ayuda a evitar la necesidad de diseñar todos los detalles de implementación anticipadamente, ya que en sí misma es una herramienta de ayuda al diseño de los componentes del software.
- Nos permite posponer decisiones a varios niveles.
- Nos permite centrarnos en problemas muy concretos, avanzando en pasos pequeños y fáciles de revertir si introducimos errores.
Beneficios
Varios estudios han mostrado evidencias que apuntan a favor de que la aplicación de TDD tiene beneficios en los equipos de desarrollo. No son evidencias concluyentes, pero las investigaciones realizadas tienden a coincidir en que con TDD:
- Se escribe una mayor cantidad de tests
- El software tiene menos defectos
- La productividad no se ve disminuida, incluso puede aumentar
Es bastante difícil cuantificar el beneficio de usar TDD en cuanto a productividad o velocidad, sin embargo, subjetivamente se pueden experimentar varios beneficios.
Uno de ellos es que la metodología TDD puede bajar la carga cognitiva del desarrollo. Esto es así porque favorece dividir el problema en tareas pequeñas con un foco muy definido, lo que nos permite ahorrar la limitada capacidad de nuestra memoria de trabajo.
La evidencia anecdótica apunta a que las desarrolladoras y equipos que introducen TDD reducen los defectos, reducen el tiempo dedicado a bugs, aumentan la confianza a la hora de desplegar y la productividad no se ve afectada negativamente.
Referencias
- Test Driven Development1
- Why Test-driven Development2
- Test driven development: empirical body of evidence3
- Does Test-Driven Development Really Improve Software Design Quality4
- 6 Misconceptions about TDD – Part 1. TDD Brings Little Business Value and Isn’t Worth it5
- TDD is about design, not testing6
- Does TDD really lead to good design?7
- Using TDD to influence design8
2 Conceptos básicos
A continuación definiremos algunos conceptos que se usan a lo largo del libro. Hay que entenderlos en el contexto de Test Driven Development.
Test
Un test es una pequeña pieza de software, normalmente una función, que ejecuta otra pieza de software y verifica si produce un resultado o efecto que esperamos. Un test es básicamente un ejemplo de uso de la unidad bajo test en el que se define un escenario y se ejecuta la unidad probada para ver si el resultado es que el que hemos previsto.
Muchos lenguajes utilizan la noción de TestCase, una clase que agrupa un cierto número de tests relacionados entre sí. En ese caso, cada método es un test, aunque es frecuente llamar test al test case.
Test como especificación
Un test como especificación utiliza ejemplos de uso de la pieza de software probada para describir cómo debería funcionar. Se utilizan, sobre todo, ejemplos que sean significativos, pero no siempre se hace de manera formal.
Se opone al test como verificación, propio de la QA, en el que se prueba la pieza de software eligiendo los casos de prueba de manera sistemática para verificar que cumple lo que se espera de ella.
Test que falla
Un test que falla es una especificación que no se cumple todavía porque no se ha añadido el software de producción que permite hacerlo pasar. Típicamente, los frameworks de testing lo representan en color rojo.
Test que pasa
Un test que pasa es una especificación que ejecuta un código de producción que genera el efecto o respuesta esperado. Los frameworks de testing los suelen representar en color verde.
Tipos de tests
Unitarios
Son tests que prueban una unidad de software en aislamiento, sus dependencias se doblan para mantener controlada su influencia en el resultado.
De integración
Los tests de integración habitualmente pruebas conjuntos de unidades de software, de modo que podemos verificar su comunicación y su acción combinada.
De aceptación
Los tests de aceptación son tests de integración que prueban un sistema de software como un consumidor más del mismo. Normalmente, los escribimos en función de los intereses del negocio.
Test Case
Es una clase que agrupa varios tests.
Test Suite
Es un conjunto de test y/o test cases, que habitualmente se pueden ejecutar juntos.
Código de producción
En TDD nos referimos con el nombre de código de producción al código que escribimos para pasar los tests y que, eventualmente, acabará siendo ejecutado en un sistema en producción.
Unidad de software
Unidad de software es un concepto bastante flexible y que hay que interpretar en un contexto, pero se refiere normalmente a una pieza de software que se puede ejecutar de forma unitaria y aislada, incluso aunque esté compuesta de varios elementos.
Subject under test
La unidad de software que es ejercitada en un test. Existe una discusión sobre cuál es el alcance de una unidad. En un extremo se encuentran quienes consideran que una unidad es una función, un método o incluso una clase. Sin embargo, también podemos considerar como unidad bajo test un conjunto de funciones o clases que son testeadas a través de la interfaz pública de una de ellas.
Refactor
Refactor es un cambio en el código que no altera su comportamiento ni su interfaz. La mejor manera de asegurar esto es que exista al menos un test que ejercita el fragmento de código que se está modificando, de modo que tras cada cambio nos aseguremos de que el test sigue pasando, lo que demostraría que no ha cambiado el comportamiento aunque se haya modificado la implementación.
Algunas técnicas o patrones de refactor están descritos en recopilaciones como esta de Refactoring Guru o el libro clásico de Martin Fowler
Refactor automático
Precisamente porque algunos refactors están muy bien identificados y caracterizados ha sido posible desarrollar herramientas capaces de ejecutarlos automáticamente. Estas herramientas están disponibles en los IDE.
3 Coding-dojo y katas
Kata
En el mundo del software llamamos katas a ejercicios de diseño y programación que plantean problemas relativamente sencillos y acotados con los que practicar metodologías de desarrollo.
El término es un prestamo de la palabra japonesa que designa los ejercicios de entrenamiento característicos de las artes marciales. Se atribuye su introducción a Dave Thomas (The Pragmatic Programmer)1, refiriéndose a la realización de pequeños ejercicios de código, repetidos una y otra vez hasta alcanzar un alto grado de fluidez o automatización.
Aplicado a TDD, las katas persiguen entrenar los ciclos de test-producción-refactor y la capacidad de añadir comportamiento mediante pequeños incrementos de código. Estos ejercicios te ayudarán a dividir una funcionalidad en partes pequeñas, a escoger ejemplos, a proceder paso a paso en el proyecto, a cambiar prioridades según la información que nos proporcionan los tests, etc.
La idea es repetir una misma kata muchas veces. Además de adquirir soltura con el proceso, en cada una de las repeticiones existe la posibilidad de descubrir nuevas estrategias. Con la práctica repetida, podremos favorecer el desarrollo de ciertos hábitos y el reconocimiento de patrones, automatizando hasta cierto punto nuestro proceso de desarrollo.
Puedes ejercitarte con katas de forma individual o con otras personas. Una forma sistemática de hacerlo es mediante un Coding Dojo.
Coding-dojo
Un coding dojo es un taller en el que un grupo de personas, con independencia de su nivel de conocimiento, realiza una kata de forma colaborativa y no competitiva.
La idea de Coding Dojo o Coder’s Dojo fue presentada en la conferencia XP2005 por Laurent Bossavit y Emmanuel Gaillot.
La estructura básica de un coding-dojo es bastante sencilla:
- Presentación del problema, organización del ejercicio (5-10 min)
- Sesión de código (30-40 min)
- Puesta en común sobre el estado del ejercicio (5-10 min)
- Continua la sesión de código (30-40 min)
- Puesta en común de las soluciones alcanzadas
La sesión de código puede desarrollarse de varias formas:
- Prepared kata. Un presentador explica cómo resolver el ejercicio, pero contando con el feedback de las personas presentes. No se avanza hasta que se consigue un consenso. Es una forma muy adecuada de trabajar cuando el grupo se está iniciando y pocas personas están acostumbradas a la metodología.
- Randori kata. La kata se realiza en pairing usando algún sistema para alternar entre la conductora (al teclado) y la copiloto. Las demás presentes colaboran haciendo sugerencias.
- Hands-on workshop. Una alternativa es que las participantes formen parejas y trabajen colaborativamente en la kata. A mitad del ejercicio se hace una parada para comentar sobre lo realizado unos minutos. Al final de la sesión se presentan las distintas soluciones en el punto donde hayan llegado. Cada pareja puede elegir el lenguaje de programación preferido, por lo que es una gran oportunidad para quienes quieran iniciarse en uno nuevo. También puede ser una buena forma para quienes se inician si se forman parejas con distinto nivel de experiencia.
Consejos para realizar las katas individualmente
Al principio puede ser buena idea asistir a katas dirigidas. Básicamente, se trata de una kata que hace una persona experta en forma de live coding mientras explica o comenta con la audiencia los distintos pasos, de modo que puedes ver la dinámica en acción. Si no tienes esta posibilidad, que puede ser lo más habitual, es buena idea ver alguna kata en vídeo. En los capítulos dedicados a cada kata puedes encontrar algunos enlaces.
Ante todo, el objetivo de las katas es ejercitar la disciplina TDD, la aplicación de las tres leyes y el ciclo red-green-refactor. El código de producción es lo de menos en el sentido de que no es el objeto del aprendizaje, aunque siempre será correcto si los tests pasan. Sin embargo, cada ejecución de la kata nos puede llevar a descubrir detalles nuevos y formas diferentes de afrontar cada fase.
Es decir, las katas están diseñadas para aprender a desarrollar software usando los tests como guía y para entrenar el mindset y los procesos de razonamiento y análisis que nos ayudan en esa tarea. Por lo general, desarrollar una buena metodología TDD nos ayudará a escribir mejor software gracias a las restricciones que nos impone.
Obviamente, los primeros intentos te llevarán su tiempo, te meterás en caminos aparentemente sin retorno o te saltarás los pasos del ciclo. Cuando ocurre eso, no tienes más que retroceder o volver a empezar de cero. Se trata de ejercicios que no tienen una respuesta correcta única.
De hecho, cada lenguaje de programación, enfoque o librería de test podrían favorecer unas soluciones u otras. Puedes hacer una kata varias veces intentando asumir diferentes supuestos de partida en cada intento o aplicando distintos paradigmas o condiciones.
Si encuentras puntos en los que puedes elegir diversos cursos de acción, toma nota de ellos para repetir el ejercicio y probar más adelante otro camino a ver a dónde te dirige.
En TDD es muy importante centrarse en el aquí y el ahora que nos define cada test que no pasa y no agobiarse por alcanzar el objetivo final. Esto no quiere decir dejarlo de lado o dedicarnos a otra cosa. Simplemente, quiere decir que hay que recorrer ese camino paso a paso, y hacerlo así nos llevará a la meta casi sin darnos cuenta, con mucho menos esfuerzo y más solidez. Adquirir esta mentalidad, ocuparse solo del problema que tengo delante, nos ayudará a reducir el estrés y pensar con más claridad.
Si es posible prueba a hacer la misma kata en diferentes lenguajes, incluso en diferentes frameworks de testing. Las dos familias más conocidas son:
- xSpec, que están orientados a TDD y tienden a favorecer el testing mediante ejemplos, proporcionando sintaxis y utilidades específicas. Su hándicap es que no suelen funcionar bien para QA.
- xUnit, que son los frameworks de testing más genéricos, aunque más orientados a QA. Sin embargo, puedes usarse para TDD perfectamente.
Cómo introducir TDD en equipos de desarrollo
Introducir la metodología TDD en equipos de desarrollo es un proceso complejo. Ante todo, es importante contribuir a generar una cultura abierta a la innovación, a la calidad y al aprendizaje. Las mayores reticencias suelen venir del miedo a que el uso de TDD ralentice el desarrollo, o que al principio no se vea una aplicación directa en los problemas diarios.
Personalmente, creo que puede ser interesante utilizar canales formales e informales. He aquí algunas ideas.
- Establecer un tiempo semanal, unas dos horas, para un coding-dojo abierto a todo el equipo. Dependiendo del nivel de experiencia puede empezarse con katas dirigidas, o sesiones tipo hands-on, o el formato que nos parezca más adecuado. Lo ideal es que diversas personas lo puedan dinamizar.
- Introducir en los equipos personas con experiencia que puedan ayudar a introducir TDD en sesiones de trabajo en pairing o mob-programming, guiando a otras compañeras.
- Organizar formación específica, con ayuda externa si no se cuenta con personas con suficiente experiencia.
- Introducir, si no se tiene, un blog técnico en el que se publiquen artículos, ejercicios y ejemplos sobre el tema.
Repositorios de katas
Referencias
- The Programming Dojo7
- What is coding dojo8
- The Coder’s Dojo – A Different Way to Teach and Learn Programming - Abstract9
TDD clásica
En esta parte presentamos una serie de ejercicios de código en los que exploraremos en profundidad cómo se hace Test Driven Development.
Usaremos el estilo o aproximación clásica de la disciplina. TDD es una metodología de desarrollo de software redescubierta por Kent Beck, basándose en el modo en que se construían los primeros programas de ordenador. Entonces, se realizaban primero los cálculos a mano para tener la referencia del resultado esperado y que debía reproducirse con el ordenador. En TDD, se escribe un programa muy sencillo que comprueba que el resultado de otro programa es el que se espera. La clave está en que ese programa aún no está escrito. Es así de simple.
La metodología fue presentada por Beck en su libro TDD by example, en el cual, entre otras cosas, se enseña a construir un framework de testing mediante TDD. Posteriormente, diversos autores han contribuido a refinar y sistematizar el modelo.
4 Las leyes de TDD
Desde la introducción de la metodología TDD por Kent Beck se ha intentado definir un framework sencillo que proporcione una guía para aplicarla en la práctica.
Inicialmente, Kent Beck propuso dos reglas muy básicas:
- No escribir una línea de código sin antes tener un test automático que falle.
- Eliminar la duplicación.
Es decir, para poder escribir código de producción, primero debemos tener un test que no pase y que requiera que escribamos ese código, precisamente porque eso es lo necesario para que el test pase.
Una vez que lo hemos escrito y viendo que el test pasa, nuestro esfuerzo se centra en revisar el código escrito y eliminar en lo posible la duplicación. Esto es muy genérico, porque, por una parte, se refiere al refactoring y, por otra parte, al acoplamiento entre el test y el código de producción. Y al ser tan genérico resulta difícil bajarlo en acciones prácticas.
Además, estas reglas no nos dicen nada acerca de cuan grandes son los saltos de código implicados en cada ciclo. Beck sugiere en su libro que los pasos o baby steps pueden ser tan pequeños o tan grandes como nos resulten útiles. En general, recomienda usar pasos pequeños cuando tenemos inseguridad o poco conocimiento del algoritmo, mientras que permite pasos más grandes si por experiencia y conocimientos tenemos claro qué hacer a continuación.
Con el tiempo, y a partir de la metodología aprendida del propio Beck, Robert C. Martin estableció las “tres leyes”, que no solo definen el ciclo de acciones en TDD, sino que también proporcionan criterios sobre cómo de grandes deberían ser los pasos en cada ciclo:
- No se permite escribir ningún código de producción a menos que haga pasar un test unitario que falle
- No se permite escribir más de un test unitario que sea suficiente para fallar; y los errores de compilación son fallos.
- No se permite escribir más código de producción del que sea necesario para hacer pasar un test unitario que falle
Las tres leyes son lo que hace diferente TDD de simplemente escribir tests antes que el código.
Estas leyes imponen una serie de restricciones cuyo objetivo es forzarnos a seguir un determinado orden y ritmo de trabajo. Definen una serie de condiciones que, si se cumplen, generan un ciclo y guían nuestra toma de decisiones. Entender cómo funcionan, nos ayudará a aprovechar al máximo la capacidad de TDD para ayudarnos a generar código de calidad y que podamos mantener.
Estas leyes se tienen que cumplir todas a la vez porque funcionan juntas.
Las leyes en detalle
No se permite escribir ningún código de producción a menos que haga pasar un test unitario que falle
La primera ley nos dice que no podemos escribir código de producción si no hace pasar un test unitario existente que actualmente está fallando. Esto implica lo siguiente:
- Tiene que existir un test que describa un aspecto nuevo del comportamiento de la unidad que estamos desarrollando.
- Este test tiene que fallar porque en el código de producción no existe nada que lo haga pasar.
En resumen, la primera ley nos fuerza a escribir un test que defina el comportamiento que vamos a implementar en la unidad de software que estamos desarrollando antes de plantearnos cómo hacerlo.
Ahora bien, ¿cómo tiene que ser el test que escribamos?
No se permite escribir más de un test unitario que sea suficiente para fallar; y los errores de compilación son fallos.
La segunda ley nos dice que el test debe ser suficiente para fallar y que tenemos que considerar fallos los errores de compilación o su equivalente en lenguajes interpretados. Por ejemplo, entre estos errores estarían algunos tan obvios como que la clase o función no existe o no ha sido definida.
Debemos evitar la tentación de escribir un esqueleto de la clase o la función antes de escribir el primer test. Recuerda que estamos hablando de Test Driven Development. Por tanto, son los tests los que nos dicen qué código de producción escribir y cuándo y no al revés.
Que el test sea suficiente para fallar quiere decir que el test ha de ser muy pequeño en diversos sentidos y es algo que al principio resulta bastante difícil de definir. Con frecuencia se habla del test “más sencillo”, del caso más simple, pero no es exactamente así.
¿Qué condiciones tendría que reunir un test en TDD, particularmente el primero?
Pues básicamente forzarnos a escribir el mínimo código posible que se pueda ejecutar. Lo mínimo en OOP sería instanciar la clase que queremos desarrollar sin preocuparnos de más detalles, de momento. El test concreto variará un poco en función del lenguaje y framework de testing que estemos utilizando.
Veamos este ejemplo. Se trata de la kata Leap Year en la se busca crear una función para averiguar si un año dado es bisiesto (leap year) o no. Para el ejemplo, mi intención es crear un objeto Year, al que le pueda preguntar si es bisiesto enviándole el mensaje isLeap. He encontrado este ejercicio en varias recopilaciones de katas sin mención de autoría. Para este capítulo, los ejemplos están escritos en C#.
Las reglas son:
- Los años no divisibles por 4 no son bisiestos (como 1997).
- Los años divisibles por 4 son bisiestos (como 1996), excepto:
- Si son divisibles por 100 no son bisiestos (como 1900).
- Si son divisibles por 400 serán bisiestos (como 2000).
Nuestro objetivo sería poder usar objetos Year de esta forma:
var year = new Year(1996);
if (year.IsLeap()) {
// do something
}
La tentación habitual es tratar de empezar de la siguiente forma porque parece que es el ejemplo del caso más sencillo posible.
using System;
using System.Runtime.Remoting.Metadata.W3cXsd2001;
using NUnit.Framework;
namespace LeapYear
{
public class Tests
{
[Test]
public void ShouldNotBeLeapYear()
{
var year = new Year(1997);
Assert.False(year.IsLeap())
}
}
}
Sin embargo, no es el test más sencillo que pueda fallar por una única razón. En realidad puede fallar por cinco razones, al menos:
- La clase
Yearno existe todavía. - Tampoco aceptaría parámetros pasados por la constructora.
- No responde al mensaje
IsLeap - Podría no retornar nada.
- Podría devolver una respuesta incorrecta.
Es decir, podemos esperar que el test falle por estas cinco causas y solo la última es la que el test realmente describe. Tenemos que reducirlas a solo una.
En este caso, es muy fácil ver que hay una dependencia entre los diversos motivos de fallo, de tal manera que para que se pueda producir uno, tiene que haberse solucionado el anterior. Evidentemente, es necesario que exista una clase que poder instanciar. Por tanto, nuestro primer test debería ser mucho más modesto y esperar únicamente que la clase se pueda instanciar:
using System;
using System.Runtime.Remoting.Metadata.W3cXsd2001;
using NUnit.Framework;
namespace LeapYear
{
public class Tests
{
[Test]
public void CanInstantiate()
{
new Year();
}
}
}
Si lanzásemos este test veríamos que falla por razones obvias: no existe la clase que se pretende instanciar en ninguna parte. El test está fallando por un problema de compilación o equivalente. Por tanto, podría ser un test suficiente para fallar.
A lo largo del proceso veremos que este test es redundante y que podemos prescindir de él, pero no nos adelantemos. Todavía tenemos que conseguir que pase.
No se permite escribir más código de producción del que sea necesario para hacer pasar un test unitario que falle
La primera y la segunda leyes nos dicen que tenemos que escribir un test y cómo debería ser ese test. La tercera ley nos dice cómo tiene que ser el código de producción. Y la condición que nos pone es que haga pasar el test que hemos escrito.
Es muy importante entender que es el test el que nos dice qué código necesitamos implementar y, por tanto, aunque tengamos la certeza de que va a fallar porque ni siquiera tenemos un archivo con el código necesario para definir la clase, debemos ejecutar el test y esperar su mensaje de error.
Es decir: tenemos que ver que el test, efectivamente, falla.
Lo primero que nos dirá al tratar de ejecutarlo es que la clase no existe. En TDD eso no es un problema, sino una indicación de lo que debemos hacer: añadir un archivo con la definición de la clase. Seguramente con las herramientas del IDE podamos generar ese código de manera automática, y es aconsejable hacerlo así.
En nuestro ejemplo, el mensaje del test dice:
The type or namespace name 'Year' could not be found
(are you missing a using directive or an assembly reference?)
Y simplemente tendremos que crear la clase Year.
using System;
using System.Runtime.Remoting.Metadata.W3cXsd2001;
using NUnit.Framework;
namespace LeapYear
{
public class Tests
{
[Test]
public void CanInstantiate()
{
new Year();
}
}
public class Year
{
}
}
En este punto volvemos a ejecutar el test para comprobar si pasa de rojo a verde. En muchos lenguajes este código será suficiente. En algunos casos puedes necesitar algo más.
Si es así, y el test pasa, el primer ciclo está completo y podremos pasar al siguiente comportamiento, a no ser que consideremos que tenemos posibilidades de hacer un refactor del código existente. Por ejemplo, lo habitual aquí sería mover la clase Year a su propio archivo.
namespace LeapYear
{
public class Year
{
}
}
Si el test no ha pasado, nos fijaremos en el mensaje mostrado por el test fallido y actuaremos en consecuencia, añadiendo el código mínimo necesario para que, finalmente, pase y se ponga en verde.
El segundo test y las tres leyes
Cuando hemos logrado hacer pasar el primer test aplicando las tres leyes podríamos pensar que no hemos conseguido realmente nada. Ni siquiera hemos abordado los posibles parámetros que podría necesitar la clase para ser construida, ya sean datos o colaboradores en el caso de servicios o use cases. Incluso el IDE se estará quejando de que no estamos asignando el objeto instanciado a ninguna variable.
Sin embargo, es importante ceñirse a la metodología, sobre todo en estas primeras fases. Con la práctica y la ayuda de un buen IDE el primer ciclo nos habrá llevado apenas unos pocos segundos. En esos pocos segundos hemos escrito un código, ciertamente muy pequeño, pero totalmente respaldado por un test.
Nuestro objetivo sigue siendo que los tests nos dicten qué código tenemos que escribir para implementar cada nuevo comportamiento. Como nuestro primer test ya pasa, tendríamos que escribir el segundo.
Aplicando las tres leyes, lo que viene a continuación es:
- Escribir un nuevo test que defina un comportamiento
- Que ese test sea el mínimo posible para obligarnos a hacer un cambio en el código de producción
- Escribir el código de producción mínimo y suficiente que hace pasar el test
¿Cuál podría ser el próximo comportamiento que necesitamos definir? Si en el primer test nos hemos forzado a escribir el código mínimo necesario para instanciar la clase, el segundo test puede llevarnos por dos caminos:
- Forzarnos a escribir el código necesario para validar parámetros del constructor y, por tanto, poder instanciar un objeto con todo lo necesario.
- Forzarnos a introducir el método que ejecuta el comportamiento deseado.
Así, en nuestro ejemplo, podríamos simplemente asegurarnos de que Year es capaz de responder al mensaje IsLeap.
using System;
using System.Runtime.Remoting.Metadata.W3cXsd2001;
using NUnit.Framework;
namespace LeapYear
{
public class Tests
{
[Test]
public void CanInstantiate()
{
new Year();
}
[Test]
public void CanRespondToIsLeapMessage()
{
var year = new Year();
year.IsLeap();
}
}
}
El test arrojará este mensaje de error:
'Year' does not contain a definition for 'IsLeap' and no accessible extension...
Que nos indica que el siguiente paso debería ser introducir el método que responde a ese mensaje:
namespace LeapYear
{
public class Year
{
public void IsLeap()
{
}
}
}
El test pasa, indicando que ahora los objetos de tipo Year, pueden atender al mensaje IsLeap.
Habiendo llegado a este punto, nos podríamos preguntar: ¿qué pasa si no cumplimos las tres leyes de TDD?
Violaciones de las tres leyes y sus consecuencias
Obviando la broma fácil de que no acabaremos en la cárcel o con una multa por incumplir las leyes de TDD, lo cierto es que sí tendríamos que apechugar con algunas consecuencias.
Primera ley: escribir código de producción sin tener un test
La consecuencia más inmediata es que rompemos el ciclo red-green. El código que escribimos ya no está guiado ni cubierto por tests. De hecho, si queremos tener esa parte testeada, tendremos que hacer un test a posteriori (un test de QA).
Imagina que hacemos esto:
using System;
namespace LeapYear
{
public class Year
{
private readonly int _aYear;
public Year(int aYear)
{
_aYear = aYear;
}
public bool? IsLeap()
{
if (_aYear % 4 == 0)
{
return true;
}
return false;
}
}
}
Los tests existentes fallarán porque hay que pasar un parámetro a la constructora, además no tenemos ningún test que se haga cargo de verificar el comportamiento que hemos introducido. Tendríamos que añadir tests para cubrir la funcionalidad que hemos incorporado, pero ya no estamos dirigiendo el desarrollo.
Segunda ley: escribir más que un test que falle
Esto podemos interpretarlo de dos formas: escribir varios tests o escribir un test que supone un salto de comportamiento demasiado grande.
Escribir más de un test provocaría varios problemas. Para hacerlos pasar todos necesitaríamos implementar una gran cantidad de código y la guía que nos podrían proporcionar esos mismos tests se desdibuja tanto que es como no tenerla. No contaríamos con una indicación concreta que podamos resolver implementando nuevo código.
using System;
using System.Runtime.Remoting.Metadata.W3cXsd2001;
using NUnit.Framework;
namespace LeapYear
{
public class Tests
{
[Test]
public void CanInstantiate()
{
new Year();
}
[Test]
public void CanRespondToIsLeapMessage()
{
var year = new Year();
year.IsLeap();
}
[Test]
public void CommonYearsShouldNotBeLeap()
{
var year = new Year(1997);
Assert.False(year.IsLeap());
}
[Test]
public void YearDivisibleBy4ShouldBeLeap()
{
var year = new Year(1996);
Assert.True(year.IsLeap());
}
}
}
Aquí hemos añadido dos tests. Para hacerlos pasar tendríamos que definir dos comportamientos. Además, son tests demasiado grandes. Todavía no hemos establecido, por ejemplo, que se pasa un parámetro a la constructora, ni que la respuesta será del tipo bool. Estos tests mezclan diversas responsabilidades y tratan de probar demasiadas cosas a la vez. Tendríamos que escribir demasiado código de producción de una sola vez, con lo que conlleva de inseguridad y espacio para que se produzcan errores.
En lugar de eso, necesitamos hacer tests para incrementos de funcionalidad más pequeños. Podemos ver varias posibilidades:
Para introducir que la respuesta es bool podemos asumir que, por defecto, los años no son bisiestos, por lo que esperaremos una respuesta false:
using System;
using System.Runtime.Remoting.Metadata.W3cXsd2001;
using NUnit.Framework;
namespace LeapYear
{
public class Tests
{
[Test]
public void CanInstantiate()
{
new Year();
}
[Test]
public void CanRespondToIsLeapMessage()
{
var year = new Year();
year.IsLeap();
}
[Test]
public void ByDefaultYearsAreNotLeapYears()
{
var year = new Year();
Assert.False(year.IsLeap());
}
}
}
El error es:
Se puede resolver con:
using System;
namespace LeapYear
{
public class Year
{
public Year()
{
}
public bool IsLeap()
{
return false;
}
}
}
Sin embargo, tenemos otra forma de hacerlo. Puesto que el lenguaje tiene tipado fuerte, podemos usar el sistema de tipos como test. Así en lugar de crear un test nuevo:
using System;
using System.Runtime.Remoting.Metadata.W3cXsd2001;
using NUnit.Framework;
namespace LeapYear
{
public class Tests
{
[Test]
public void CanInstantiate()
{
new Year();
}
[Test]
public void CanRespondToIsLeapMessage()
{
var year = new Year();
year.IsLeap();
}
}
}
Cambiamos el tipo de retorno de IsLeap:
using System;
namespace LeapYear
{
public class Year
{
public Year()
{
}
public bool IsLeap()
{
}
}
}
Al ejecutar el test nos indicará que hay un problema, pues no devolvemos nada en la función:
'Year.IsLeap()': not all code paths return a value
Y finalmente, no tenemos más que añadir una respuesta por defecto, que será false:
using System;
namespace LeapYear
{
public class Year
{
public Year()
{
}
public bool IsLeap()
{
return false;
}
}
}
Para introducir el parámetro de construcción podríamos recurrir a un refactor. Pero para esto el lenguaje de programación nos puede condicionar, llevándonos a distintas soluciones.
La vía del refactor es sencilla. Tan solo tenemos que incorporar el parámetro, aunque de momento no lo usaremos. En C# y otros lenguajes podemos hacerlo por la vía de introducir un constructor alternativo, de este modo los tests seguirán pasando. En otros lenguajes, podríamos marcar el parámetro como opcional.
using System;
namespace LeapYear
{
public class Year
{
private readonly int _aYear;
public Year()
{
}
public Year(int aYear)
{
_aYear = aYear;
}
public bool IsLeap()
{
return false;
}
}
}
Como para nosotras no tiene sentido un constructor sin parámetros, ahora podríamos eliminarlo, pero antes tendríamos que refactorizar los tests, de modo que usemos la versión con parámetro:
using System;
using System.Runtime.Remoting.Metadata.W3cXsd2001;
using NUnit.Framework;
namespace LeapYear
{
public class Tests
{
[Test]
public void CanInstantiate()
{
new Year(1997);
}
[Test]
public void CanRespondToIsLeapMessage()
{
var year = new Year(1997);
year.IsLeap();
}
}
}
Lo cierto es que el primer test nos sobra, porque está implícito en el otro.
using System;
using System.Runtime.Remoting.Metadata.W3cXsd2001;
using NUnit.Framework;
namespace LeapYear
{
public class Tests
{
[Test]
public void CanRespondToIsLeapMessage()
{
var year = new Year(1997);
year.IsLeap();
}
}
}
Y ahora podemos eliminar el constructor sin parámetros, ya que no se volverá a usar en ningún caso:
using System;
namespace LeapYear
{
public class Year
{
private readonly int _aYear;
public Year(int aYear)
{
_aYear = aYear;
}
public bool IsLeap()
{
return false;
}
}
}
Tercera ley: escribir más del código de producción necesario para que pase el test
Se trata quizá de la violación más frecuente de todas. Llega un momento en que “vemos” el algoritmo con tanta claridad que nuestro impulso es escribirlo ya y terminar el proceso. Sin embargo, esto nos puede llevar a obviar algunas situaciones. Por ejemplo, en una aplicación podríamos “ver” el algoritmo general e implementarlo. Sin embargo, eso podría habernos distraído de uno o varios casos particulares y no contemplarlos, lo que una vez incorporado a la aplicación y desplegado posiblemente aparecerían errores en producción, incluso con pérdidas económicas.
Por ejemplo, si añadimos un test para probar que controlamos los años no bisiestos:
using System;
using System.Runtime.Remoting.Metadata.W3cXsd2001;
using NUnit.Framework;
namespace LeapYear
{
public class Tests
{
[Test]
public void CanRespondToIsLeapMessage()
{
var year = new Year(1997);
year.IsLeap();
}
[Test]
public void CommonYearsAreNoLeapYears()
{
var year = new Year(1997);
Assert.False(year.IsLeap());
}
}
}
En el estado actual de nuestro ejercicio, un exceso de código sería este:
using System;
namespace LeapYear
{
public class Year
{
private readonly int _aYear;
public Year(int aYear)
{
_aYear = aYear;
}
public bool IsLeap()
{
if (_aYear % 4 == 0)
{
if (_aYear % 400 == 0)
{
return false;
}
if (_aYear % 100 == 0)
{
return true;
}
return true;
}
return false;
}
}
}
El test pasa con este código, pero como puedes ver se ha introducido mucho más del necesario para tener el comportamiento definido por el test, añadiendo código para controlar los años bisiestos y los casos especiales. Así que aparentemente todo está bien.
Si probamos un año bisiesto, veremos que el código funciona, lo que refuerza nuestra impresión de que todo es correcto.
using System;
using System.Runtime.Remoting.Metadata.W3cXsd2001;
using NUnit.Framework;
namespace LeapYear
{
public class Tests
{
[Test]
public void CanRespondToIsLeapMessage()
{
var year = new Year(1997);
year.IsLeap();
}
[Test]
public void CommonYearsAreNoLeapYears()
{
var year = new Year(1997);
Assert.False(year.IsLeap());
}
[Test]
public void ShouldIdentifyStandardLeapYears()
{
var year = new Year(1996);
Assert.True(year.IsLeap());
}
}
}
Pero, un nuevo test falla. Los años divisibles por 100 no deben ser bisiestos (salvo que sean divisibles por 400), y este error lleva un buen rato en nuestro código, pero hasta ahora no teníamos un test que ejecutase esa parte del código.
using System;
using System.Runtime.Remoting.Metadata.W3cXsd2001;
using NUnit.Framework;
namespace LeapYear
{
public class Tests
{
[Test]
public void CanRespondToIsLeapMessage()
{
var year = new Year(1997);
year.IsLeap();
}
[Test]
public void CommonYearsAreNoLeapYears()
{
var year = new Year(1997);
Assert.False(year.IsLeap());
}
[Test]
public void ShouldIdentifyStandardLeapYears()
{
var year = new Year(1996);
Assert.True(year.IsLeap());
}
[Test]
public void ShouldIdentifyCenturyExceptionOfLeapYears()
{
var year = new Year(1900);
Assert.False(year.IsLeap());
}
}
}
Este es el tipo de problemas que pueden pasar desapercibidos cuando añadimos demasiado código para hacer pasar un test. El exceso de código posiblemente no afecta al test que tenemos entre manos, por lo que no sabremos si esconde algún tipo de problema y no lo sabremos si no llegamos a construir un test que lo ponga de manifiesto. O peor: no lo sabremos hasta que el bug explota en producción.
La solución es bastante simple: añade solo el código estrictamente necesario para que el test pase, aunque solo sea devolver el valor esperado por el propio test. No introduzcas comportamiento si no existe antes un test que te obligue a ello porque está fallando.
En nuestro caso era el test que verificaba el tratamiento de los años no bisiestos. De hecho, el siguiente test, que pretendía introducir el comportamiento de detectar los años bisiestos estándar (años divisibles por 4) pasaba sin necesidad de añadir nuevo código. Esto nos lleva al siguiente punto.
Qué significa que un test pase nada más escribirlo
Cuando escribimos un test y pasa sin añadir código de producción puede ser por alguno de estos motivos:
- El algoritmo que hemos escrito es lo bastante general como para cubrir todos los casos posibles: hemos terminado nuestro desarrollo.
- El ejemplo que hemos elegido no es cualitativamente diferente de otros que ya hemos usado y, por lo tanto, no nos fuerza a escribir código de producción. tenemos que encontrar otro ejemplo.
- Hemos añadido demasiado código, que es lo que acabamos de contar en el apartado anterior.
En esta kata Leap Year, por ejemplo, llegará un momento en que no hay forma de escribir un test que falle porque el algoritmo cubre todos los casos: años no bisiestos, bisiestos, años no bisiestos cada 100 años y bisiestos cada 400 años.
La otra posibilidad es que el ejemplo escogido no sea representativo de un nuevo comportamiento, lo que puede venir dado por una mala definición de la tarea o por no haber analizado bien los posibles escenarios.
El ciclo red-green-refactor
Las tres leyes establecen un framework que podríamos llamar “de bajo nivel”. Martin Fowler, por su parte, define el ciclo TDD en estas tres fases que estarían en un nivel superior de abstracción:
- Escribe un test para el siguiente fragmento de funcionalidad que deseas añadir.
- Escribe el código de producción necesario para que el test pase.
- Refactoriza el código, tanto el nuevo como el anterior, para que esté bien estructurado.
Estas tres fases definen lo que se suele conocer como el ciclo “red-green-refactor”, nombrado así por el estado de los tests en cada una de las fases del ciclo:
- Red: la creación de un test que falla (está en rojo) y que describe la funcionalidad o comportamiento que queremos introducir en el software de producción.
- Green: la escritura del código de producción necesario para hacer pasar el test (ponerlo en verde) con lo cual se verifica que se ha añadido el comportamiento especificado.
- Refactor: manteniendo los tests en verde, reorganizar el código para estructurarlo mejor, haciéndolo más legible y sostenible sin perder la funcionalidad desarrollada hasta el momento.
En la práctica los ciclos de refactor surgen después de un cierto número de ciclos de las tres leyes. Los pequeños cambios impulsados por estas se acumulan hasta llegar a un punto en el que comienzan a aparecer smells de código que requieren el refactor.
Referencias
- The three rules of TDD1
- The three rules of TDD - video2
- Refactoring the three laws of TDD3
- TDD with PHPSpec4
- The 3 Laws of TDD: Focus on One Thing at a Time5
- Test Driven Development6
- The cycles of TDD7
5 Fizz Buzz
Entendiendo las leyes y ciclos de TDD
La kata FizzBuzz es una de las katas más sencillas para empezar a practicar TDD. Plantea un problema muy simple y bien acotado, por lo que en una primera fase es muy fácil resolverla por completo en una sesión de una o dos horas. Pero también se pueden ampliar sus requerimientos y lograr desarrollos más complejos, como poner el requisito de que las reglas o el tamaño de la lista sean configurables, que se puedan añadir nuevas reglas, etc.
En este caso, al tratarse de nuestra primera kata, seguiremos la versión más sencilla.
Historia
Según Coding Dojo, no se conoce la autoría de la kata1, pero se considera que fue presentada en sociedad por Michael Feathers y Emily Bache en 2008, en el marco de la conferencia Agile2008.
Enunciado
FizzBuzz es un juego relacionado con el aprendizaje de la división en el que un grupo de estudiantes cuentan los números por turno, reemplazando cada número divisible por tres con la palabra “Fizz” y cada número divisible por cinco con la palabra “Buzz”. Si el número es divisible por ambos, entonces se dice “FizzBuzz”.
Así que nuestro objetivo será escribir un programa que imprima los números del 1 al 100 de tal manera que:
- si el número es divisible por 3 devuelve Fizz.
- si el número es divisible por 5 devuelve Buzz.
- si el número es divisible por 3 y 5 devuelve FizzBuzz.
Orientaciones para resolverla
La kata Fizz Buzz nos va a servir para entender y comenzar a aplicar el ciclo Red-Green-Refactor y las Tres leyes de TDD.
Lo primero que nos conviene hacer es considerar el problema y hacernos una idea general de cómo vamos a solucionarlo. TDD es una estrategia que nos ayuda a evitar la necesidad de hacer un detallado análisis y diseño exhaustivo previo a la solución, pero eso no significa que no debamos primero entender el problema y considerar cómo lo vamos a atacar.
Esto también es necesario para evitar dejarnos llevar por el enunciado literal de la kata, que nos puede llevar a callejones sin salida.
Lo primero que vamos a hacer, una vez que tenemos esa idea general de cómo vamos a enfocar el objetivo, es aplicar la primera ley y escribir un test que falle.
Este test debería definir el primer comportamiento que necesitamos implementar.
Escribir un test que falle significa, en este momento, escribir un test que no va a funcionar porque no existe ningún código que ejecutar, cosa que nos van a decir los mensajes de error. Aunque te parezca absurdo debes intentar ejecutar el test y confirmar que no pasa. Son los mensajes del test los que te van a indicar qué hacer a continuación.
Para conseguir hacer que el test falle tenemos que aplicar la segunda ley, que dice que no podemos escribir un test más grande de lo que sea suficiente para fallar. El test más pequeño posible debería obligarnos a definir la clase instanciándola y poco más.
Por último, para hacer que el test pase, aplicaremos la tercera ley, que dice que no debemos escribir más código de producción que el necesario para que el test pase. Es decir: definir la clase, en su caso el método que vamos a ejercitar y hacer que este devuelva alguna respuesta que finalmente haga pasar el test.
Los dos primeros pasos de esta fase son bastante obvios, pero el tercero no tanto.
Con los dos primeros pasos intentamos llegar a conseguir que el test falle por los motivos adecuados. Es decir, primero falla porque no hemos escrito la clase y, en consecuencia la definimos. Luego fallará porque nos falta el método al que estamos llamando, así que lo definimos. Finalmente, fallará porque no devuelve la respuesta que esperamos, que es lo que queremos llegar a testear.
¿Y qué respuesta deberíamos estar devolviendo en cada caso? Pues ni más ni menos la que espera el test.
Una vez que tenemos un primer test y un primer código de producción que lo hace pasar nos haremos la pregunta: ¿cuál sería el siguiente comportamiento que debería implementar?
Enlaces de interés sobre la kata FizzBuzz
- Vídeo de la kata por Jesús López de la Cruz2
- FizzBuzz en Kata-log3
- FizzBuzz resuelta en SmallTalk4
- Code Katas Explained: FizzBuzz5
- TDD — Which Order to Write Your Tests6
- Solución en Python usando una lista de casos de uso7
6 Resolviendo la kata Fizz Buzz
Enunciado de la kata
Nuestro objetivo será escribir un programa que imprima los números del 1 al 100 de tal manera que:
- si el número es divisible por 3 devuelve Fizz.
- si el número es divisible por 5 devuelve Buzz.
- si el número es divisible por 3 y 5 devuelve FizzBuzz.
Lenguaje y enfoque
Esta kata la vamos a hacer en Python con unittest como librería de testing. La tarea consiste crear una clase FizzBuzz, que tendrá un método generate para crear la lista, de modo que se usará más o menos así:
fizzbuzz = Fizzbuzz()
print(fizzbuzz.generate())
Para ello creo una carpeta fizzbuzzkata y dentro añado el archivo fixzzbuzz_test.py.
Definir la clase
Lo que nos pide el ejercicio es obtener una lista de los números 1 al 100 cambiando algunos de ellos por las palabras ‘Fizz’, ‘Buzz’ o ambas en caso de cumplirse ciertas condiciones.
Fíjate que no nos pide una lista de cualquier cantidad de números, sino específicamente del 1 al 100. Volveremos a eso dentro de un momento.
Ahora vamos a concentrarnos en ese primer test. Lo menos que podemos hacer es que se pueda instanciar un objeto del tipo FizzBuzz. He aquí un posible primer test:
import unittest
class FizzBuzzTestCase(unittest.TestCase):
def test_something(self):
FizzBuzz()
if __name__ == '__main__':
unittest.main()
Puede parecer extraño. Este test se limita a intentar instanciar la clase y nada más.
Este primer test debería ser suficiente para fallar, que es lo que dice la segunda ley, y forzarnos a definir la clase para que el test pueda pasar, cumpliendo la tercera ley. En algunos entornos sería necesaria una aserción, ya que consideran que el test no ha pasado si no se ha verificado explícitamente, cosa que no sucede en Python.
Así que lo lanzamos para ver si es verdad que falla. El resultado, como era de esperar es que el test no pasa, mostrando el siguiente error, el cual es justo el que esperaríamos ver:
NameError: name 'FizzBuzz' is not defined
Para hacer que el test pase, tendremos que definir la clase FizzBuzz, cosa que haremos en el propio archivo del test.
import unittest
class FizzBuzz(object):
pass
class FizzBuzzTestCase(unittest.TestCase):
def test_something(self):
FizzBuzz()
if __name__ == '__main__':
unittest.main()
Y con esto el test pasará. Ahora que estamos en verde podemos pensar en refactorizar. La clase no tiene código. Pero el test no tiene un nombre adecuado, ahora podríamos cambiarlo:
import unittest
class FizzBuzz:
pass
class FizzBuzzTestCase(unittest.TestCase):
def test_can_instantiate(self):
FizzBuzz()
if __name__ == '__main__':
unittest.main()
Normalmente, es mejor que las clases estén en su propio archivo (o módulo en Python) porque es más fácil gestionar el código y saber dónde está cada cosa. Definitivamente, no queremos el código de producción en el archivo del test, así que creamos el archivo fizzbuzz.py moviendo de paso la clase.
Y en el test, la importamos:
import unittest
from fizzbuzzkata.fizzbuzz import FizzBuzz
class FizzBuzzTestCase(unittest.TestCase):
def test_can_instantiate(self):
FizzBuzz()
if __name__ == '__main__':
unittest.main()
Al introducir este cambio y ejecutar el test podemos ver que ahora sí pasa y ya estamos en verde.
Hemos cumplido las tres leyes y cerrado nuestro primer ciclo test-código-refactor. No hay mucho más que podamos hacer aquí, salvo pasar al siguiente test.
Definir el método generate
La clase FizzBuzz no solo no hace nada, ni siquiera tiene métodos. Hemos dicho que queremos que tenga un método generate que es el que devolverá la lista de los números del 1 al 100.
Para forzarnos a escribir el método generate, tenemos que escribir un test que lo llame. El método tendrá que devolver algo, ¿no? No. No siempre es necesario que devuelva algo. Nos basta con que nada se rompa al llamar al método.
import unittest
from fizzbuzzkata.fizzbuzz import FizzBuzz
class FizzBuzzTestCase(unittest.TestCase):
def test_can_instantiate(self):
FizzBuzz()
def test_responds_to_generate_message(self):
fizzbuzz = FizzBuzz()
fizzbuzz.generate()
if __name__ == '__main__':
unittest.main()
Al ejecutar el test nos dice que no tiene ningún método generate:
Por supuesto que no lo tiene, tenemos que añadirlo:
class FizzBuzz(object):
def generate(self):
pass
Ahora ya tenemos una clase capaz de responder al mensaje generate. ¿Podemos hacer algún refactor aquí?
Pues sí, pero no en el código de producción, sino en los tests. Resulta que este test que acabamos de escribir se superpone al anterior. Es decir, el test test_responds_to_generate_message cubre al test test_can_instantiate, convirtiéndolo en redundante. Por tanto, lo podemos quitar:
import unittest
from fizzbuzzkata.fizzbuzz import FizzBuzz
class FizzBuzzTestCase(unittest.TestCase):
def test_responds_to_generate_message(self):
fizzbuzz = FizzBuzz()
fizzbuzz.generate()
if __name__ == '__main__':
unittest.main()
Quizá esto te sorprenda. Es lo que comentamos al principio del libro, algunos de los tests que utilizamos para dirigir el desarrollo dejan de tener utilidad por un motivo u otro, generalmente porque son redundantes y no aportan ninguna información que no nos estén dando otros tests.
Definir un comportamiento para generate
Específicamente queremos que nos devuelva una lista de números. Pero ahora no hace falta que lo haga con los múltiplos de 3 y 5 convertidos.
El test debe verificar esto, pero debe seguir pasando cuando hayamos desarrollado el algoritmo completo. Lo que podemos verificar es que devuelve una lista de 100 elementos, sin prestar atención a los que contiene exactamente.
Este test nos forzará a darle un comportamiento en respuesta al mensaje generate:
import unittest
from fizzbuzzkata.fizzbuzz import FizzBuzz
class FizzBuzzTestCase(unittest.TestCase):
def test_respond_to_generate_message(self):
fizzbuzz = FizzBuzz()
fizzbuzz.generate()
def test_generates_list_of_100_elements(self):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
self.assertEqual(100, len(num_list))
if __name__ == '__main__':
unittest.main()
Por supuesto, el test falla:
TypeError: object of type 'NoneType' has no len()
Ahora mismo, el método devuelve None. Nosotros queremos una lista:
class FizzBuzz(object):
def generate(self):
return []
Al hacer que generate devuelva una lista, hacemos que el test falle porque no se cumple lo que esperamos: que la lista tenga un cierto número de elementos:
AssertionError: 100 != 0
Este ya es un error del test. Los anteriores eran básicamente errores equivalentes a los errores de compilación (errores de sintaxis, etc.). Por eso es tan importante ver los tests fallar, para utilizar el feedback que nos proporcionan los mensajes de error.
Hacer que el test pase es bastante fácil:
class FizzBuzz(object):
def generate(self):
return [None] * 100
Con el test pasando vamos a pensar un poco.
En primer lugar, se puede argumentar que en este test hemos pedido que la respuesta de generate cumpla dos condiciones:
- ser de tipo list (o array, o collection)
- tener exactamente 100 elementos
Podríamos haber forzado esto mismo con dos tests aún más pequeños.
A estos pequeños pasos se les suele llamar baby steps y lo cierto es que no tienen una medida determinada, sino que dependen de nuestra práctica y experiencia.
Así, por ejemplo, el test que hemos creado es lo bastante pequeño como para no generar un gran salto de código en producción, aunque es capaz de verificar las dos condiciones a la vez.
En segundo lugar, fíjate que hemos escrito tan solo el código necesario para que se cumpla el test. De hecho devolvemos una lista de 100 elementos None, lo cual parece que no tiene mucho sentido, pero es suficiente para nuestro objetivo con este test. Recuerda: no escribas más código del necesario para hacer pasar el test.
En tercer lugar, ya tenemos bastante código escrito, entre test y producción, como para examinarlo y ver si tenemos alguna oportunidad de refactorizar.
La oportunidad más clara de refactor que tenemos ahora mismo es el número mágico 100, que podríamos representar mediante una constante de la clase. De nuevo, cada lenguaje te ofrecerá sus propias opciones:
class FizzBuzz(object):
_NUMBER_OF_ELEMENTS = 100
def generate(self):
return [None] * self._NUMBER_OF_ELEMENTS
Y tenemos alguna en el código de test. Otra vez el test que hemos añadido se superpone e incluye al anterior, por lo que podríamos quitarlo.
import unittest
from fizzbuzzkata.fizzbuzz import FizzBuzz
class FizzBuzzTestCase(unittest.TestCase):
def test_generates_list_of_100_elements(self):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
self.assertEqual(100, len(num_list))
if __name__ == '__main__':
unittest.main()
De igual manera, el nombre del test puede mejorar. En lugar de hacer una referencia a la cifra concreta, podríamos simplemente indicar algo más general, que no ate el test a un detalle específico de la implementación:
import unittest
from fizzbuzzkata.fizzbuzz import FizzBuzz
class FizzBuzzTestCase(unittest.TestCase):
def test_generates_list_of_required_number_of_elements(self):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
self.assertEqual(100, len(num_list))
if __name__ == '__main__':
unittest.main()
Por último, y no menos importante, igualmente tenemos un número mágico 100, al cual le pondremos un nombre:
import unittest
from fizzbuzzkata.fizzbuzz import FizzBuzz
class FizzBuzzTestCase(unittest.TestCase):
_NUMBER_OF_ELEMENTS = 100
def test_generates_list_of_required_number_of_elements(self):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
self.assertEqual(self._NUMBER_OF_ELEMENTS, len(num_list))
if __name__ == '__main__':
unittest.main()
Y con esto, hemos terminado un nuevo ciclo en el que ya hemos introducido la fase de refactor.
Generar una lista de números
Nuestra clase FizzBuzz ya puede generar una lista de 100 elementos, pero de momento cada uno de ellos es, literalmente, nada. Es hora de escribir un test que nos fuerce a poner números en esa lista.
Para ellos podríamos esperar que la lista generada contenga los números del 1 al 100. Sin embargo, tenemos un problema: al final del proceso de desarrollo la lista contendrá los números, pero algunos de ellos estarán representados con las palabras Fizz, Buzz o FizzBuzz. Si no tengo esto en cuenta, este tercer test empezará a fallar en cuanto comience a implementar el algoritmo que convierte los números. No parece una buena solución.
Un enfoque más prometedor es: ¿qué números no se verán afectados por el algoritmo? Pues aquellos que no sean múltiplos de 3 o de 5, por tanto podríamos escoger algunos de ellos para verificar que se incluyen en la lista sin transformar.
El más sencillo de todos es el 1, que debería figurar en la primera posición de la lista. Por razones de simetría vamos a hacer que los números se generen como strings.
import unittest
from fizzbuzzkata.fizzbuzz import FizzBuzz
class FizzBuzzTestCase(unittest.TestCase):
_NUMBER_OF_ELEMENTS = 100
def test_generates_list_of_required_number_of_elements(self):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
self.assertEqual(self._NUMBER_OF_ELEMENTS, len(num_list))
def test_number_one_is_represented_as_itself(self):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
self.assertEqual('1', num_list[0])
if __name__ == '__main__':
unittest.main()
El test es muy pequeño y falla:
¿Qué cambio podríamos introducir en el código de producción en este punto para que el test pase? El más obvio podría ser el siguiente:
class FizzBuzz(object):
_NUMBER_OF_ELEMENTS = 100
def generate(self):
return ['1'] * self._NUMBER_OF_ELEMENTS
Lo cierto es que es suficiente como para pasar el test, así que nos vale.
Un problema que tenemos aquí es que el número 1 no aparece como tal en el test. Sí aparece su representación, pero usamos su posición en num_list, que es un array 0-indexed. Vamos a hacer explícito que estamos testeando sobre la representación de un número. Primero introducimos el concepto de posición:
import unittest
from fizzbuzzkata.fizzbuzz import FizzBuzz
class FizzBuzzTestCase(unittest.TestCase):
_NUMBER_OF_ELEMENTS = 100
def test_generates_list_of_required_number_of_elements(self):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
self.assertEqual(self._NUMBER_OF_ELEMENTS, len(num_list))
def test_number_one_is_represented_as_itself(self):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
position = 0
self.assertEqual('1', num_list[position])
if __name__ == '__main__':
unittest.main()
Y ahora el de número, así como su relación con posición:
import unittest
from fizzbuzzkata.fizzbuzz import FizzBuzz
class FizzBuzzTestCase(unittest.TestCase):
_NUMBER_OF_ELEMENTS = 100
def test_generates_list_of_required_number_of_elements(self):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
self.assertEqual(self._NUMBER_OF_ELEMENTS, len(num_list))
def test_number_one_is_represented_as_itself(self):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
number = 1
position = number - 1
self.assertEqual('1', num_list[position])
if __name__ == '__main__':
unittest.main()
Ya no necesitamos referirnos a la posición para nada, tan solo al número.
import unittest
from fizzbuzzkata.fizzbuzz import FizzBuzz
class FizzBuzzTestCase(unittest.TestCase):
_NUMBER_OF_ELEMENTS = 100
def test_generates_list_of_required_number_of_elements(self):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
self.assertEqual(self._NUMBER_OF_ELEMENTS, len(num_list))
def test_number_one_is_represented_as_itself(self):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
number = 1
self.assertEqual('1', num_list[(number - 1)])
if __name__ == '__main__':
unittest.main()
Podríamos hacer el test más fácil de leer. Primero separamos la verificación:
import unittest
from fizzbuzzkata.fizzbuzz import FizzBuzz
class FizzBuzzTestCase(unittest.TestCase):
_NUMBER_OF_ELEMENTS = 100
def test_generates_list_of_required_number_of_elements(self):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
self.assertEqual(self._NUMBER_OF_ELEMENTS, len(num_list))
def test_number_one_is_represented_as_itself(self):
number = 1
self.__assert_number_is_represented_as(number)
def __assert_number_is_represented_as(self, number):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
self.assertEqual('1', num_list[(number - 1)])
if __name__ == '__main__':
unittest.main()
Extraemos la representación como parámetro en la aserción y hacemos un inline de number para que sea más fluida la lectura:
import unittest
from fizzbuzzkata.fizzbuzz import FizzBuzz
class FizzBuzzTestCase(unittest.TestCase):
_NUMBER_OF_ELEMENTS = 100
def test_generates_list_of_required_number_of_elements(self):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
self.assertEqual(self._NUMBER_OF_ELEMENTS, len(num_list))
def test_number_one_is_represented_as_itself(self):
self.__assert_number_is_represented_as(1, '1')
def __assert_number_is_represented_as(self, number, representation):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
self.assertEqual(representation, num_list[(number - 1)])
if __name__ == '__main__':
unittest.main()
Como ves, hemos trabajado mucho en el test. Ahora será muy barato introducir nuevos ejemplos, lo que nos ayudará a escribir más tests y que el proceso sea más agradable y cómodo.
Seguimos generando números
En realidad todavía no hemos verificado que el método generate nos esté dando una lista de números, así que necesitamos seguir proponiendo nuevos tests que nos fuercen a introducir ese código.
Vamos a asegurarnos de que en la segunda posición aparece el número 2 que es el siguiente más sencillo que no es múltiplo de 3 o de 5:
import unittest
from fizzbuzzkata.fizzbuzz import FizzBuzz
class FizzBuzzTestCase(unittest.TestCase):
_NUMBER_OF_ELEMENTS = 100
def test_generates_list_of_required_number_of_elements(self):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
self.assertEqual(self._NUMBER_OF_ELEMENTS, len(num_list))
def test_number_one_is_represented_as_itself(self):
self.__assert_number_is_represented_as(1, '1')
self.__assert_number_is_represented_as(2, '2')
def __assert_number_is_represented_as(self, number, representation):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
self.assertEqual(representation, num_list[(number - 1)])
if __name__ == '__main__':
unittest.main()
Tenemos un nuevo test y también falla, así que vamos a añadir código en producción para que el test pase. Sin embargo, tenemos algunos problemas con esta implementación:
class FizzBuzz(object):
_NUMBER_OF_ELEMENTS = 100
def generate(self):
return ['1'] * self._NUMBER_OF_ELEMENTS
Para intervenir en ella necesitaríamos refactorizarla un poco primero. Como mínimo extraer la respuesta a una variable que podamos manipular antes de devolverla.
Pero como el test ahora mismo está fallando no podemos refactorizar. Antes tenemos que anular o borrar el test que acabamos de crear. Lo más fácil es comentarlo y así no se ejecutará. Recuerda, para hacer refactor es obligatorio que los tests pasen:
import unittest
from fizzbuzzkata.fizzbuzz import FizzBuzz
class FizzBuzzTestCase(unittest.TestCase):
_NUMBER_OF_ELEMENTS = 100
def test_generates_list_of_required_number_of_elements(self):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
self.assertEqual(self._NUMBER_OF_ELEMENTS, len(num_list))
def test_number_one_is_represented_as_itself(self):
self.__assert_number_is_represented_as(1, '1')
# self.__assert_number_is_represented_as(2, '2')
def __assert_number_is_represented_as(self, number, representation):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
self.assertEqual(representation, num_list[(number - 1)])
if __name__ == '__main__':
unittest.main()
Ahora sí podemos trabajar:
class FizzBuzz(object):
_NUMBER_OF_ELEMENTS = 100
def generate(self):
num_list = ['1'] * self._NUMBER_OF_ELEMENTS
return num_list
Y volvemos a activar el test, que ahora falla porque el número dos es representado con un ‘1’. El cambio más sencillo que se me ocurre ahora es este, tan tonto:
class FizzBuzz(object):
_NUMBER_OF_ELEMENTS = 100
def generate(self):
num_list = ['1'] * self._NUMBER_OF_ELEMENTS
num_list[1] = '2'
return num_list
Lo cierto es que el test está en verde. Sabemos que esta no es la implementación que resolverá el problema completo, pero nuestro código de producción solo está obligado a satisfacer los tests existentes. Por tanto, no nos precipitemos. Veamos qué podemos hacer.
El nombre del test está obsoleto, para empezar, hagámoslo más general:
import unittest
from fizzbuzzkata.fizzbuzz import FizzBuzz
class FizzBuzzTestCase(unittest.TestCase):
_NUMBER_OF_ELEMENTS = 100
def test_generates_list_of_required_number_of_elements(self):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
self.assertEqual(self._NUMBER_OF_ELEMENTS, len(num_list))
def test_number_is_represented_as_itself(self):
self.__assert_number_is_represented_as(1, '1')
self.__assert_number_is_represented_as(2, '2')
def __assert_number_is_represented_as(self, number, representation):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
self.assertEqual(representation, num_list[(number - 1)])
if __name__ == '__main__':
unittest.main()
Una vez resuelto esto, recordemos que antes vimos que el concepto de número y representación eran necesarios para definir mejor el comportamiento esperado en los tests. Podemos introducirlos ahora en nuestro código de producción:
class FizzBuzz(object):
_NUMBER_OF_ELEMENTS = 100
def generate(self):
num_list = ['1'] * self._NUMBER_OF_ELEMENTS
number = 2
representation = '2'
num_list[number-1] = representation
return num_list
Es un primer paso. Se pueden ver las limitaciones de la solución actual. Por ejemplo, ¿por qué tiene un tratamiento especial el 1? ¿Y qué pasará si queremos verificar otro número? Son varios problemas.
En cuanto al número 1, la clave está en la idea de lista de números. Ahora mismo generamos una lista de constantes, pero cada elemento de esa lista debería ser un número correlativo empezando por el número 1, hasta completar el número de elementos.
Y luego tendríamos que reemplazar cada número por su representación. Algo así:
class FizzBuzz(object):
_NUMBER_OF_ELEMENTS = 100
def generate(self):
num_list = list(range(1, self._NUMBER_OF_ELEMENTS + 1))
number = 1
representation = '1'
num_list[number-1] = representation
number = 2
representation = '2'
num_list[number-1] = representation
return num_list
El test sigue pasando con esta nueva estructura, pero esto no parece muy práctico. Sin embargo, podemos ver un patrón. Necesitamos recorrer la lista para darle una solución:
class FizzBuzz(object):
_NUMBER_OF_ELEMENTS = 100
def generate(self):
num_list = list(range(1, self._NUMBER_OF_ELEMENTS + 1))
for number in num_list:
if number == 1:
representation = '1'
if number == 2:
representation = '2'
num_list[number-1] = representation
return num_list
Con la información de que disponemos, podríamos asumir simplemente que nos basta con convertir el número en string y ponerlo en su lugar:
class FizzBuzz(object):
_NUMBER_OF_ELEMENTS = 100
def generate(self):
num_list = list(range(1, self._NUMBER_OF_ELEMENTS + 1))
for number in num_list:
representation = str(number)
num_list[number-1] = representation
return num_list
Claro que existen formas más pythonicas y compactas, como esta:
class FizzBuzz:
_NUMBERS_IN_LIST = 100
def generate(self):
return list(map(lambda num: str(num + 1), range(self._NUMBERS_IN_LIST)))
Pero debemos tener cuidado, probablemente estamos adelantándonos demasiado con este refactor y seguramente nos generará problemas cuando intentemos avanzar. Por eso, es preferible mantener una implementación más directa e ingenua y dejar las optimizaciones y estructuras más avanzadas para cuando el comportamiento del método esté completamente definido. Así que te recomendaría evitar este tipo de aproximación.
Todo este refactor con los tests pasando. Esto quiere decir que:
1. Con el test describimos el comportamiento que queremos desarrollar
2. Hacemos pasar el test con el código más sencillo posible, por estúpidamente simple que nos parezca, a fin de tener ese comportamiento implementado
3. Usamos los test en verde como red de seguridad para reestructurar el código hasta encontrar un diseño mejor: fácil de entender, mantener y extender.
Los puntos 2 y 3 se construyen basándose en estos principios:
- KISS: Keep it simply stupid (mantenlo simplemente estúpido), que quiere decir mantener el sistema lo más tonto posible, y no intentar añadir inteligencia prematuramente. Cuanto más mecánico y simple mejor, dentro de sus necesidades. Este KISS es nuestra primera aproximación.
- Ley de Gall: todo sistema complejo que funciona ha evolucionado desde un sistema más simple que funcionaba. Por tanto, empezamos por una implementación muy simple que funcione (KISS) y la hacemos evolucionar hacia una más compleja que también funciona, cosa que sabemos gracias a que el test sigue pasando.
- YAGNI: Your aren’t gonna need it (no lo vas a necesitar), que nos fuerza a no implementar más comportamiento que lo estrictamente necesario para que pasen los tests actuales.
Pero ahora tenemos que implementar nuevos comportamientos.
El test que no falla
El siguiente número que no es múltiplo de 3, 5 o 15 es 4, así que añadimos un ejemplo para eso:
import unittest
from fizzbuzzkata.fizzbuzz import FizzBuzz
class FizzBuzzTestCase(unittest.TestCase):
_NUMBER_OF_ELEMENTS = 100
def test_generates_list_of_required_number_of_elements(self):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
self.assertEqual(self._NUMBER_OF_ELEMENTS, len(num_list))
def test_number_is_represented_as_itself(self):
self.__assert_number_is_represented_as(1, '1')
self.__assert_number_is_represented_as(2, '2')
self.__assert_number_is_represented_as(4, '4')
def __assert_number_is_represented_as(self, number, representation):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
self.assertEqual(representation, num_list[(number - 1)])
if __name__ == '__main__':
unittest.main()
Y el test pasa. ¿Buena noticia? Depende. Un test que pasa nada más crearlo siempre es motivo de sospecha, al menos desde el punto de vista de TDD. Recuerda: escribir un test que falle es lo primero. Si el test no falla es que:
- El comportamiento ya está implementado
- No es el test que andábamos buscando
En nuestro caso ocurre que el último refactor ha dado lugar al comportamiento general de los números que no necesitan transformación. De hecho, podemos categorizar los números en estas clases:
- Números que se representan como ellos mismos
- Múltiplos de tres, representados por ‘Fizz’
- Múltiplos de cinco, representados por ‘Buzz’
- Múltiplos de tres y cinco, representados por ‘FizzBuzz’
1 y 2 son miembros de la primera clase, por lo que son ejemplos más que suficientes, ya que cualquier número de esa clase nos valdría como ejemplo. En TDD los necesitamos porque nos han ayudado a introducir la idea de que tendríamos que recorrer la lista de números. Pero nos bastaría con un único test en QA. Por eso, al introducir el ejemplo del 4, no hace falta añadir nuevo código: el comportamiento ya está implementado.
Es hora de moverse a las otras clases de números.
Aprendiendo a decir “Fizz”
Es hora de que nuestro FizzBuzz sea capaz de convertir el 3 en “Fizz”. Un test mínimo para especificarlo sería el siguiente:
import unittest
from fizzbuzzkata.fizzbuzz import FizzBuzz
class FizzBuzzTestCase(unittest.TestCase):
_NUMBER_OF_ELEMENTS = 100
def test_generates_list_of_required_number_of_elements(self):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
self.assertEqual(self._NUMBER_OF_ELEMENTS, len(num_list))
def test_number_is_represented_as_itself(self):
self.__assert_number_is_represented_as(1, '1')
self.__assert_number_is_represented_as(2, '2')
self.__assert_number_is_represented_as(4, '4')
def test_three_and_its_multiples_are_represented_as_fizz(self):
self.__assert_number_is_represented_as(3, 'Fizz')
def __assert_number_is_represented_as(self, number, representation):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
self.assertEqual(representation, num_list[(number - 1)])
if __name__ == '__main__':
unittest.main()
Teniendo un test que falla, veamos qué código de producción mínimo podríamos añadir para que pase:
class FizzBuzz(object):
_NUMBER_OF_ELEMENTS = 100
def generate(self):
num_list = list(range(1, self._NUMBER_OF_ELEMENTS + 1))
for number in num_list:
representation = str(number)
if number == 3:
representation = 'Fizz'
num_list[number - 1] = representation
return num_list
Hemos añadido un if que hace pasar este caso particular. De momento no hay otra forma mejor con la información que tenemos. Recuerda KISS, Gall y YAGNI para evitar avanzar más de lo debido.
En lo que toca al código, puede que haya una manera mejor de poblar la lista. En lugar de generar una lista de números y cambiarla, tal vez podamos iniciar una lista vacía e ir añadiendo las representaciones de los números en ella:
class FizzBuzz(object):
_NUMBER_OF_ELEMENTS = 100
def generate(self):
representations = list()
num_list = list(range(1, self._NUMBER_OF_ELEMENTS + 1))
for number in num_list:
representation = str(number)
if number == 3:
representation = 'Fizz'
representations.append(representation)
return representations
Esto funciona. Ahora num_list no tiene mucha razón de ser como lista. Podemos hacer un cambio:
class FizzBuzz(object):
_NUMBER_OF_ELEMENTS = 100
def generate(self):
representations = list()
num_list = range(1, self._NUMBER_OF_ELEMENTS + 1)
for number in num_list:
representation = str(number)
if number == 3:
representation = 'Fizz'
representations.append(representation)
return representations
Y eliminar la variable temporal:
class FizzBuzz(object):
_NUMBER_OF_ELEMENTS = 100
def generate(self):
representations = list()
for number in range(1, self._NUMBER_OF_ELEMENTS + 1):
representation = str(number)
if number == 3:
representation = 'Fizz'
representations.append(representation)
return representations
Todo sigue funcionando correctamente, como atestiguan los tests.
Decir “Fizz” cuando toca
Ahora queremos que nos ponga un “Fizz” cuando el número es múltiplo de 3 y no solo cuando es exactamente 3. Por supuesto, nos toca añadir un test para especificarlo. Esta vez con el número 6, que es el más cercano que tenemos y que es múltiplo de 3 (y no de cinco).
import unittest
from fizzbuzzkata.fizzbuzz import FizzBuzz
class FizzBuzzTestCase(unittest.TestCase):
_NUMBER_OF_ELEMENTS = 100
def test_generates_list_of_required_number_of_elements(self):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
self.assertEqual(self._NUMBER_OF_ELEMENTS, len(num_list))
def test_number_is_represented_as_itself(self):
self.__assert_number_is_represented_as(1, '1')
self.__assert_number_is_represented_as(2, '2')
self.__assert_number_is_represented_as(4, '4')
def test_three_and_its_multiples_are_represented_as_fizz(self):
self.__assert_number_is_represented_as(3, 'Fizz')
self.__assert_number_is_represented_as(6, 'Fizz')
def __assert_number_is_represented_as(self, number, representation):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
self.assertEqual(representation, num_list[(number - 1)])
if __name__ == '__main__':
unittest.main()
Para hacer pasar el test el cambio que hay que hacer es bastante pequeño. Tenemos que modificar la condición para ampliarla a los múltiplos de tres. Pero vamos a hacerlo de manera progresiva.
Primero establecemos el comportamiento:
class FizzBuzz(object):
_NUMBER_OF_ELEMENTS = 100
def generate(self):
representations = list()
for number in range(1, self._NUMBER_OF_ELEMENTS + 1):
representation = str(number)
if number == 3:
representation = 'Fizz'
if number == 6:
representation = 'Fizz'
representations.append(representation)
return representations
Con esto el test, pasa. Ahora vamos a cambiar el código para que use el concepto múltiplo de:
class FizzBuzz(object):
_NUMBER_OF_ELEMENTS = 100
def generate(self):
representations = list()
for number in range(1, self._NUMBER_OF_ELEMENTS + 1):
representation = str(number)
if number == 3:
representation = 'Fizz'
if number == 6:
representation = 'Fizz'
if number % 3 == 0:
representation = 'Fizz'
representations.append(representation)
return representations
El test sigue pasando, lo que indica que nuestra hipótesis es correcta. Ahora podemos eliminar la parte de código redundante:
class FizzBuzz(object):
_NUMBER_OF_ELEMENTS = 100
def generate(self):
representations = list()
for number in range(1, self._NUMBER_OF_ELEMENTS + 1):
representation = str(number)
if number % 3 == 0:
representation = 'Fizz'
representations.append(representation)
return representations
En este punto, podrías querer probar otros ejemplos de la misma clase, aunque realmente no es necesario dado que cualquier múltiplo de tres es un representante adecuado. Por eso, nos moveremos al siguiente comportamiento.
Aprendiendo a decir “Buzz”
Este test nos permite especificar el nuevo comportamiento:
import unittest
from fizzbuzzkata.fizzbuzz import FizzBuzz
class FizzBuzzTestCase(unittest.TestCase):
_NUMBER_OF_ELEMENTS = 100
def test_generates_list_of_required_number_of_elements(self):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
self.assertEqual(self._NUMBER_OF_ELEMENTS, len(num_list))
def test_number_is_represented_as_itself(self):
self.__assert_number_is_represented_as(1, '1')
self.__assert_number_is_represented_as(2, '2')
self.__assert_number_is_represented_as(4, '4')
def test_three_and_its_multiples_are_represented_as_fizz(self):
self.__assert_number_is_represented_as(3, 'Fizz')
self.__assert_number_is_represented_as(6, 'Fizz')
def test_five_and_its_multiples_are_represented_as_buzz(self):
self.__assert_number_is_represented_as(5, 'Buzz')
def __assert_number_is_represented_as(self, number, representation):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
self.assertEqual(representation, num_list[(number - 1)])
if __name__ == '__main__':
unittest.main()
Así que modificamos el código de producción para lograr que pase el test. Como hemos hecho antes, tratamos el caso particular de forma particular:
class FizzBuzz(object):
_NUMBER_OF_ELEMENTS = 100
def generate(self):
representations = list()
for number in range(1, self._NUMBER_OF_ELEMENTS + 1):
representation = str(number)
if number % 3 == 0:
representation = 'Fizz'
if number == 5:
representation = 'Buzz'
representations.append(representation)
return representations
Sí, ya sabemos cómo tendríamos que tratar el caso general de los múltiplos de cinco, pero es preferible forzarse a ir despacio. Recuerda que el objetivo principal del ejercicio no es resolver la generación de la lista, sino hacerlo guiadas por tests. Nuestro interés ahora es internalizar este ciclo de pasos cortos.
No hay mucho más que podamos hacer ahora, salvo pasar al siguiente test.
Decir “Buzz” cuando toca
A estas alturas el test es bastante obvio, el siguiente múltiplo de 5 es 10:
import unittest
from fizzbuzzkata.fizzbuzz import FizzBuzz
class FizzBuzzTestCase(unittest.TestCase):
_NUMBER_OF_ELEMENTS = 100
def test_generates_list_of_required_number_of_elements(self):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
self.assertEqual(self._NUMBER_OF_ELEMENTS, len(num_list))
def test_number_is_represented_as_itself(self):
self.__assert_number_is_represented_as(1, '1')
self.__assert_number_is_represented_as(2, '2')
self.__assert_number_is_represented_as(4, '4')
def test_three_and_its_multiples_are_represented_as_fizz(self):
self.__assert_number_is_represented_as(3, 'Fizz')
self.__assert_number_is_represented_as(6, 'Fizz')
def test_five_and_its_multiples_are_represented_as_buzz(self):
self.__assert_number_is_represented_as(5, 'Buzz')
self.__assert_number_is_represented_as(10, 'Buzz')
def __assert_number_is_represented_as(self, number, representation):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
self.assertEqual(representation, num_list[(number - 1)])
if __name__ == '__main__':
unittest.main()
Y, de nuevo, el cambio en el código de producción es simple al principio:
class FizzBuzz(object):
_NUMBER_OF_ELEMENTS = 100
def generate(self):
representations = list()
for number in range(1, self._NUMBER_OF_ELEMENTS + 1):
representation = str(number)
if number % 3 == 0:
representation = 'Fizz'
if number == 5:
representation = 'Buzz'
if number == 10:
representation = 'Buzz'
representations.append(representation)
return representations
A continuación, procedemos paso a paso en el refactor, ahora que hemos asegurado el comportamiento:
class FizzBuzz(object):
_NUMBER_OF_ELEMENTS = 100
def generate(self):
representations = list()
for number in range(1, self._NUMBER_OF_ELEMENTS + 1):
representation = str(number)
if number % 3 == 0:
representation = 'Fizz'
if number == 5:
representation = 'Buzz'
if number == 10:
representation = 'Buzz'
if number % 5 == 0:
representation = 'Buzz'
representations.append(representation)
return representations
Y luego:
class FizzBuzz(object):
_NUMBER_OF_ELEMENTS = 100
def generate(self):
representations = list()
for number in range(1, self._NUMBER_OF_ELEMENTS + 1):
representation = str(number)
if number % 3 == 0:
representation = 'Fizz'
if number % 5 == 0:
representation = 'Buzz'
representations.append(representation)
return representations
Y con este refactor podemos pasar a la siguiente clase de números.
Aprender a decir “FizzBuzz”
La estructura es exactamente igual. Empecemos por el caso más sencillo: 15 debe devolver “FizzBuzz” ya que 15 es el primer número que es múltiplo de 3 y 5 a la vez
import unittest
from fizzbuzzkata.fizzbuzz import FizzBuzz
class FizzBuzzTestCase(unittest.TestCase):
_NUMBER_OF_ELEMENTS = 100
def test_generates_list_of_required_number_of_elements(self):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
self.assertEqual(self._NUMBER_OF_ELEMENTS, len(num_list))
def test_number_is_represented_as_itself(self):
self.__assert_number_is_represented_as(1, '1')
self.__assert_number_is_represented_as(2, '2')
self.__assert_number_is_represented_as(4, '4')
def test_three_and_its_multiples_are_represented_as_fizz(self):
self.__assert_number_is_represented_as(3, 'Fizz')
self.__assert_number_is_represented_as(6, 'Fizz')
def test_five_and_its_multiples_are_represented_as_buzz(self):
self.__assert_number_is_represented_as(5, 'Buzz')
self.__assert_number_is_represented_as(10, 'Buzz')
def test_fifteen_and_its_multiples_are_represented_as_fizzbuzz(self):
self.__assert_number_is_represented_as(15, 'FizzBuzz')
def __assert_number_is_represented_as(self, number, representation):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
self.assertEqual(representation, num_list[(number - 1)])
if __name__ == '__main__':
unittest.main()
El nuevo test falla. Hagámoslo pasar:
class FizzBuzz(object):
_NUMBER_OF_ELEMENTS = 100
def generate(self):
representations = list()
for number in range(1, self._NUMBER_OF_ELEMENTS + 1):
representation = str(number)
if number % 3 == 0:
representation = 'Fizz'
if number % 5 == 0:
representation = 'Buzz'
if number == 15:
representation = 'FizzBuzz'
representations.append(representation)
return representations
Decir “FizzBuzz” cuando toca
Y seguimos introduciendo un test para otro caso de la clase de múltiplos de 3 y 5, que será 30.
import unittest
from fizzbuzzkata.fizzbuzz import FizzBuzz
class FizzBuzzTestCase(unittest.TestCase):
_NUMBER_OF_ELEMENTS = 100
def test_generates_list_of_required_number_of_elements(self):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
self.assertEqual(self._NUMBER_OF_ELEMENTS, len(num_list))
def test_number_is_represented_as_itself(self):
self.__assert_number_is_represented_as(1, '1')
self.__assert_number_is_represented_as(2, '2')
self.__assert_number_is_represented_as(4, '4')
def test_three_and_its_multiples_are_represented_as_fizz(self):
self.__assert_number_is_represented_as(3, 'Fizz')
self.__assert_number_is_represented_as(6, 'Fizz')
def test_five_and_its_multiples_are_represented_as_buzz(self):
self.__assert_number_is_represented_as(5, 'Buzz')
self.__assert_number_is_represented_as(10, 'Buzz')
def test_fifteen_and_its_multiples_are_represented_as_fizzbuzz(self):
self.__assert_number_is_represented_as(15, 'FizzBuzz')
self.__assert_number_is_represented_as(30, 'FizzBuzz')
def __assert_number_is_represented_as(self, number, representation):
fizzbuzz = FizzBuzz()
num_list = fizzbuzz.generate()
self.assertEqual(representation, num_list[(number - 1)])
if __name__ == '__main__':
unittest.main()
Esta vez iré directamente a la implementación final, pero ya te haces a la idea:
class FizzBuzz(object):
_NUMBER_OF_ELEMENTS = 100
def generate(self):
representations = list()
for number in range(1, self._NUMBER_OF_ELEMENTS + 1):
representation = str(number)
if number % 3 == 0:
representation = 'Fizz'
if number % 5 == 0:
representation = 'Buzz'
if number % 15 == 0:
representation = 'FizzBuzz'
representations.append(representation)
return representations
¡Y ya tenemos nuestro “FizzBuzz”!
Finalizando
Hemos completado el desarrollo del comportamiento especificado de la clase FizzBuzz. De hecho, cualquier test que añadamos ahora nos confirmará que el algoritmo es lo bastante general como para que todos los casos estén cubiertos. Es decir, no hay un test concebible que nos pueda obligar a introducir más código de producción: no hay nada más que debamos hacer.
En un caso de trabajo real este código sería funcional y entregable. Pero ciertamente podemos mejorarlo todavía. Todos los tests pasando indican que el comportamiento deseado está implementado, así que podríamos refactorizar sin miedo buscando una solución más flexible. Por ejemplo, con la siguiente solución sería fácil añadir algunas reglas más:
class FizzBuzz(object):
_NUMBER_OF_ELEMENTS = 100
def generate(self):
rules = {
3: 'Fizz',
5: 'Buzz',
15: 'FizzBuzz',
}
representations = list()
for number in range(1, self._NUMBER_OF_ELEMENTS + 1):
representation = str(number)
for divisor in rules.keys():
if number % divisor == 0:
representation = rules[divisor]
representations.append(representation)
return representations
Y si te fijas bien, sería relativamente fácil modificar la clase para introducir las reglas desde fuera, ya que bastaría con pasar el diccionario con las reglas al instanciar la clase, cumpliendo el principio de Open for extension and Closed for modification. En este caso, hemos dejado que se usen las reglas originales si no se indican otras, de modo que los tests siguen pasando exactamente igual.
class FizzBuzz(object):
_NUMBER_OF_ELEMENTS = 100
def __init__(self, rules=None):
if rules is None:
rules = {
3: 'Fizz',
5: 'Buzz',
15: 'FizzBuzz',
}
self.rules = rules
def generate(self):
representations = list()
for number in range(1, self._NUMBER_OF_ELEMENTS + 1):
representation = str(number)
for divisor in self.rules.keys():
if number % divisor == 0:
representation = self.rules[divisor]
representations.append(representation)
return representations
Qué hemos aprendido con esta kata
- Las leyes de TDD
- El ciclo red->green->refactor
- Usar tests mínimos para hacer avanzar el código de producción
- Cambiar el código de producción lo mínimo para conseguir el comportamiento
- Usar la fase de refactor para mejorar el diseño del código
7 Elección de los ejemplos y criterio de finalización
Una de las preguntas más frecuentes cuando empiezas a hacer TDD es cuántos tests tienes que escribir hasta considerar el desarrollo terminado. La respuesta corta es: tendrás que hacer todos los tests que sean necesarios y ni uno más. La respuesta larga es este capítulo.
Checklist driven testing
Una buena técnica puede ser seguir el consejo de Kent Beck y escribir una lista de control o check-list en la que anotamos todos aquellos comportamientos que queremos implementar. Obviamente, a medida que completamos cada comportamiento vamos tachando items en la lista.
También es posible que, durante el trabajo, descubramos que necesitamos testear algún otro comportamiento, que podemos suprimir alguno de los elementos de la lista, o que nos interesa cambiar el orden en que lo hemos planeado. Por supuesto que podemos hacer todo esto según nos convenga.
La lista no es más que una herramienta para no depender de nuestra memoria durante el proceso. Al fin y al cabo, uno de los beneficios de hacer Test Driven Development es reducir la cantidad de información y conocimiento que tenemos que utilizar en cada fase del proceso de desarrollo. Cada ciclo de TDD implica un problema muy pequeño, que podemos resolver con bastante poco esfuerzo. Pequeños pasos que acaban llevándonos muy lejos.
Veamos un ejemplo con la kata Leap Year, en la que tenemos que crear una función para calcular si un año es bisiesto o no. Una posible lista de control sería esta:
Otro ejemplo para la kata Prime Numbers, en la que el ejercicio consiste en desarrollar una función que obtenga los factores primos de un número:
Selección de ejemplos
Por cada comportamiento que queremos implementar necesitaremos un cierto número de ejemplos con los que escribir los tests. En el capítulo siguiente veremos que TDD tiene dos momentos principales: uno relacionado con el establecimiento de la interfaz de la unidad que estamos creando y otro en el que desarrollamos el comportamiento propiamente dicho. Es en este momento cuando necesitamos ejemplos que cuestionen la implementación existente y nos obliguen a introducir código que produzca el comportamiento deseado.
Una buena idea es, por tanto, anotar varios ejemplos posibles con los que probar cada item de la lista de control.
Pero, ¿cuántos ejemplos son necesarios? En QA tenemos varias técnicas para escoger ejemplos representativos con los que generar los tests, pero tienen el objetivo de optimizar la relación entre el número de tests y su capacidad de cubrir los escenarios posibles.
Podemos utilizar algunas de ellas en TDD, aunque de una forma un poco diferente, como veremos a continuación. Ten en cuenta que en TDD estamos desarrollando un algoritmo y, en muchos casos, lo vamos descubriendo mientras lo escribimos. Para eso necesitaremos varios ejemplos relacionados con el mismo comportamiento, de modo que podamos identificar regularidades y descubrir cómo generalizarlo.
Las técnicas en las que nos vamos a fijar son:
Partición por clase de equivalencia
Esta técnica se basa en que el conjunto de todos los posibles casos concebibles se puede dividir en clases mediante algún criterio. Todos los ejemplos en la misma clase serían equivalentes, por lo que bastaría hacer un test con un ejemplo de cada clase, ya que todos son igualmente representativos de la misma.
Análisis de límites
Esta técnica es similar a la anterior, pero prestando atención a los límites o fronteras entre clases. Se escogen dos ejemplos de cada clase que son justamente los que se encuentran en sus límites. Ambos ejemplos son representativos de la clase, pero nos permiten estudiar qué ocurre en los extremos del intervalo.
Se usa cuando los ejemplos son datos contínuos o nos importa especialmente el cambio que se produce al pasar de una clase a otra. Específicamente es el tipo de situación en la que el resultado depende de si el valor considerado es mayor o estrictamente mayor, etc.
Tabla de decisión
La tabla de decisión no es más que el resultado de combinar los posibles valores, agrupados en clases, de los parámetros que se pasan a la unidad bajo test.
Vamos a ver la elección de ejemplos aplicada al caso de Leap Year. Para eso, empezamos con la lista:
Veamos el primer item. Podríamos usar cualquier número que cumpla la condición de no ser divisible por 4:
En el segundo item, los ejemplos deben cumplir la condición de ser divisibles por 4:
Prestemos atención al siguiente elemento de la lista. La condición de ser números divisibles por 100 se superpone con la condición anterior. Por tanto, tenemos que eliminar algunos ejemplos del item anterior:
Y ocurre lo mismo con el último de los elementos de la lista. Los ejemplos para este item son los números divisibles por 400. También se superpone con el ejemplo anterior:
De este modo, la lista con los ejemplos quedaría así:
Por otro lado, la elección de ejemplos para Prime Factors nos podría dar esto:
Uso de varios ejemplos para generalizar un algoritmo
En ejercicios de código simples como puede ser la kata Leap Year, es relativamente fácil anticipar el algoritmo, de modo que no necesitaríamos usar varios ejemplos para hacerlo evolucionar e implementarlo. En realidad, sería suficiente con un ejemplo de cada clase, como hemos visto al hablar de la partición por clases de equivalencia, y en pocos minutos tendríamos el problema resuelto.
Sin embargo, si estamos empezando con TDD es buena idea ir paso a paso. Lo mismo que si nos enfrentamos a un comportamiento complejo. Es preferible tomar baby steps realmente pequeños, introducir varios ejemplos y esperar a tener suficiente información para generalizar. En este mismo libro puedes encontrar varias aplicaciones de esta técnica. Tener algo de duplicación de código es preferible a escoger la abstracción equivocada y construir sobre ella.
Una heurística que puedes aplicar es la regla de los tres. Esta regla nos dice que no deberíamos intentar generalizar código hasta tener al menos tres repeticiones del mismo. Para ello, tendremos que identificar las partes fijas y las partes que cambian.
Considera este ejemplo, tomado de un ejercicio de la kata Leap Year. En este punto los tests están pasando, pero de momento no hemos generado un algoritmo.
function leapYear(year) {
if (year === 1992) {
return true;
}
if (year === 1996) {
return true;
}
if (year === 2020) {
return true;
}
return false;
}
describe('Identify Leap Year', () => {
it('should be Leap Year', () => {
expect(leapYear(1992)).toBeTruthy();
expect(leapYear(1996)).toBeTruthy();
expect(leapYear(2020)).toBeTruthy();
});
})
Ya tenemos tres repeticiones. ¿Qué tienen en común aparte de la estructura if/then?. Forcemos un pequeño cambio:
function leapYear(year) {
if (year === 498 * 4) {
return true;
}
if (year === 499 * 4) {
return true;
}
if (year === 505 * 4) {
return true;
}
return false;
}
describe('Identify Leap Year', () => {
it ('should be Common Year', () => {
expect(leapYear(1997)).toBeFalsy();
expect(leapYear(1998)).toBeFalsy();
expect(leapYear(2021)).toBeFalsy();
});
it('should be Leap Year', () => {
expect(leapYear(1992)).toBeTruthy();
expect(leapYear(1996)).toBeTruthy();
expect(leapYear(2020)).toBeTruthy();
});
})
Claramente, los tres años son divisibles por 4. Así que podríamos expresarlo de otra manera:
function leapYear(year) {
if (year % 4 === 0) {
return true;
}
if (year % 4 === 0) {
return true;
}
if (year % 4 === 0) {
return true;
}
return false;
}
describe('Identify Leap Year', () => {
it ('should be Common Year', () => {
expect(leapYear(1997)).toBeFalsy();
expect(leapYear(1998)).toBeFalsy();
expect(leapYear(2021)).toBeFalsy();
});
it('should be Leap Year', () => {
expect(leapYear(1992)).toBeTruthy();
expect(leapYear(1996)).toBeTruthy();
expect(leapYear(2020)).toBeTruthy();
});
})
Que ahora es una repetición obvia y se puede eliminar:
function leapYear(year) {
if (year % 4 === 0) {
return true;
}
return false;
}
describe('Identify Leap Year', () => {
it ('should be Common Year', () => {
expect(leapYear(1997)).toBeFalsy();
expect(leapYear(1998)).toBeFalsy();
expect(leapYear(2021)).toBeFalsy();
});
it('should be Leap Year', () => {
expect(leapYear(1992)).toBeTruthy();
expect(leapYear(1996)).toBeTruthy();
expect(leapYear(2020)).toBeTruthy();
});
})
Esto ha sido muy obvio, por supuesto. Sin embargo, no siempre tendremos las cosas tan fáciles.
En resumen, si no conocemos muy bien el problema, puede ser útil esperar a que se cumpla la regla de los tres para empezar a pensar en generalizaciones del código. Esto implica que, como mínimo, introduciremos tres ejemplos que representen la misma clase antes de refactorizar la solución a una más general.
Veamos otro ejemplo en la misma kata:
function leapYear(year) {
if (year % 100 === 0) {
return false;
}
if (year % 4 === 0) {
return true;
}
return false;
}
describe('Identify Leap Year', () => {
it ('should be Common Year', () => {
expect(leapYear(1997)).toBeFalsy();
expect(leapYear(1998)).toBeFalsy();
expect(leapYear(2021)).toBeFalsy();
});
it('should be Leap Year', () => {
expect(leapYear(1992)).toBeTruthy();
expect(leapYear(1996)).toBeTruthy();
expect(leapYear(2020)).toBeTruthy();
});
it('should be exceptional common year', function () {
expect(leapYear(1700)).toBeFalsy();
expect(leapYear(1800)).toBeFalsy();
expect(leapYear(1900)).toBeFalsy();
});
})
La duplicación que no lo es
El concepto divisible es evidente en esta ocasión y realmente no necesitamos un tercer caso para valorar la posibilidad de extraerlo. Pero aquí lo importante no es la duplicación. En realidad nos hubiese bastado con un ejemplo. Este refactor lo hacemos porque hace explícita la idea de que la condición que se evalúa es el hecho de que el número del año sea divisible por un cierto factor para que se aplique la regla.
function leapYear(year) {
function divisibleBy(divisor) {
return year % divisor === 0;
}
if (divisibleBy(100)) {
return false;
}
if (divisibleBy(4)) {
return true;
}
return false;
}
describe('Identify Leap Year', () => {
it ('should be Common Year', () => {
expect(leapYear(1997)).toBeFalsy();
expect(leapYear(1998)).toBeFalsy();
expect(leapYear(2021)).toBeFalsy();
});
it('should be Leap Year', () => {
expect(leapYear(1992)).toBeTruthy();
expect(leapYear(1996)).toBeTruthy();
expect(leapYear(2020)).toBeTruthy();
});
it('should be exceptional common year', function () {
expect(leapYear(1700)).toBeFalsy();
expect(leapYear(1800)).toBeFalsy();
expect(leapYear(1900)).toBeFalsy();
});
})
Esto se ve más claro si avanzamos un poco más.
function leapYear(year) {
function divisibleBy(divisor) {
return year % divisor === 0;
}
if (divisibleBy(400)) {
return true;
}
if (divisibleBy(100)) {
return false;
}
if (divisibleBy(4)) {
return true;
}
return false;
}
Tenemos una misma estructura repetida tres veces, pero no podemos extraer un concepto común de aquí. Dos de las repeticiones representan el mismo concepto (año bisiesto), pero la tercera representa años de duración normal excepcionales.
En búsqueda de la abstracción incorrecta
Intentemos otra aproximación:
function leapYear(year) {
function divisibleBy(divisor) {
return year % divisor === 0;
}
if (divisibleBy(4 * 4 * 5 * 5)) {
return true;
}
if (divisibleBy(4 * 5 * 5)) {
return false;
}
if (divisibleBy(4)) {
return true;
}
return false;
}
Si dividimos el año entre cuatro podríamos plantear otra idea, ya que eso nos podría ayudar a identificar mejor las partes comunes y diferentes:
function leapYear(year) {
function divisibleBy(divisor) {
return year % divisor === 0;
}
year /= 4
if (divisibleBy(4 * 5 * 5)) {
return true;
}
if (divisibleBy(5 * 5)) {
return false;
}
if (divisibleBy(1)) {
return true;
}
return false;
}
Es extraño, pero funciona. Más simplificado:
function leapYear(year) {
function divisibleBy(divisor) {
return year % divisor === 0;
}
year /= 4
if (divisibleBy(100)) {
return true;
}
if (divisibleBy(25)) {
return false;
}
if (divisibleBy(1)) {
return true;
}
return false;
}
Sigue funcionando. Pero, ¿de qué nos sirve?
- Por un lado, seguimos sin encontrar una manera de reconciliar las tres estructuras
if/then. - Por otro, hemos hecho que las reglas de dominio sean irreconocibles.
En otras palabras: intentar encontrar una abstracción basándonos solo en la existencia de repetición en el código puede ser un camino sin salida.
La abstracción correcta
Como hemos señalado antes, el concepto que nos interesa es el de año bisiesto y las reglas que lo determinan. ¿Podemos hacer el código menos repetitivo? Puede ser. Volvamos al principio:
function leapYear(year) {
function divisibleBy(divisor) {
return year % divisor === 0;
}
if (divisibleBy(400)) {
return true;
}
if (divisibleBy(100)) {
return false;
}
if (divisibleBy(4)) {
return true;
}
return false;
}
La cuestión es que la regla de divisible por 400 es una excepción a la regla de divisible por 100:
function leapYear(year) {
function divisibleBy(divisor) {
return year % divisor === 0;
}
if (divisibleBy(100) && !divisibleBy(400)) {
return false;
}
if (divisibleBy(4)) {
return true;
}
return false;
}
Lo que nos permite hacer esto y compactar un poco la solución:
function leapYear(year) {
function divisibleBy(divisor) {
return year % divisor === 0;
}
if (divisibleBy(100) && !divisibleBy(400)) {
return false;
}
return divisibleBy(4);
}
Quizá podamos hacerla un poco más explícita:
function leapYear(year) {
function divisibleBy(divisor) {
return year % divisor === 0;
}
function isCommonYearExceptionally() {
return divisibleBy(100) && !divisibleBy(400);
}
if (isCommonYearExceptionally()) {
return false;
}
return divisibleBy(4);
}
Pero ahora queda un poco raro, necesitamos ser más explícitas aquí:
function leapYear(year) {
function divisibleBy(divisor) {
return year % divisor === 0;
}
function isCommonYearExceptionally() {
return divisibleBy(100) && !divisibleBy(400);
}
function isLeapYear() {
return divisibleBy(4);
}
if (isCommonYearExceptionally()) {
return false;
}
return isLeapYear();
}
En este punto, me pregunto si esto no es demasiado poco natural. Por un lado, la abstracción es correcta, pero a fuerza de llevarla tan lejos posiblemente estamos pecando de cierta sobre-ingeniería. El dominio del problema es muy pequeño y las reglas muy sencillas y claras. Si comparas esto:
function leapYear(year) {
function divisibleBy(divisor) {
return year % divisor === 0;
}
if (divisibleBy(400)) {
return true;
}
if (divisibleBy(100)) {
return false;
}
if (divisibleBy(4)) {
return true;
}
return false;
}
Con esto:
function leapYear(year) {
function divisibleBy(divisor) {
return year % divisor === 0;
}
function isCommonYearExceptionally() {
return divisibleBy(100) && !divisibleBy(400);
}
function isLeapYear() {
return divisibleBy(4);
}
if (isCommonYearExceptionally()) {
return false;
}
return isLeapYear();
}
Creo que me quedaría con la primera solución. Ahora bien, en un problema más complejo y más complicado de entender, puede que la segunda solución sea mucho más adecuada, precisamente porque nos ayudaría a hacer explícitos los conceptos implicados.
La moraleja es que no hay que empeñarse en buscar la abstracción perfecta, sino la suficiente para este momento.
8 Evolución del comportamiento mediante tests
La metodología TDD se basa en ciclos de trabajo en los que definimos un comportamiento deseado en forma de test, realizamos cambios en el código de producción para implementarlo, y refactorizamos la solución una vez que sabemos que funciona.
Si bien disponemos de herramientas específicas para detectar situaciones que requieren refactor e incluso métodos bien definidos para llevarlo a cabo, no tenemos recursos que guíen las transformaciones necesarias del código de una forma similar. Es decir, ¿existe algún proceso que nos sirva para decidir qué tipo de cambio aplicar al código para implementar un comportamiento?
The Transformation Priority Premise1 es un artículo que plantea un framework útil en este sentido. Partiendo de la idea de que a medida que los tests son más específicos el código se vuelve más general, propone una secuencia del tipo de transformaciones que podemos aplicar cada vez que estamos en fase de implementación, en la transición de rojo a verde.
El desarrollo mediante TDD tendría dos partes principales:
- En la primera parte construimos la interfaz pública de la clase, definiendo cómo nos vamos a comunicar con ella y cómo nos va a responder. Esta respuesta la analizamos en su forma más genérica, que sería el tipo de dato que proporciona.
- En la segunda parte desarrollamos el comportamiento, empezando desde los casos más genéricos e introduciendo después los más específicos.
Vamos a ver esto con un ejemplo práctico. Realizaremos la kata Roman Numerals fijándonos en cómo los tests nos sirven para guiar estas dos partes. En esta ocasión el lenguaje será Kotlin.
Construir la interfaz pública de una clase dirigida por tests
Siempre empezaremos con un test que nos obligue a definir la clase, pues de momento no nos hace falta nada más que tener algún objeto con el que poder llegar a interactuar.
package org.talkingbit.kata
import org.junit.jupiter.api.Test
class RomanNumeralsTest {
@Test
fun `Should convert numbers to roman` () {
RomanNumerals()
}
}
Ejecutamos el test para verlo fallar y, a continuación, escribimos la definición de la clase vacía, lo mínimo imprescindible para que el test pase.
package org.talkingbit.kata
class RomanNumerals {
}
Si la hemos creado en el mismo archivo que el test, ahora podemos moverla a su sitio durante la fase de refactor.
Ya podemos pensar en el segundo test, que necesitamos para definir la interfaz pública, es decir: cómo vamos a comunicarnos con el objeto una vez instanciado, qué mensajes es capaz de entender:
package org.talkingbit.kata
import org.junit.jupiter.api.Test
class RomanNumeralsTest {
@Test
fun `It converts numbers to roman` () {
RomanNumerals().toRoman()
}
}
Estamos modificando el primer test. Ahora que tenemos algo de soltura, podemos permitirnos estas licencias, para que escribir un nuevo test nos resulte más económico. Comprobamos que falle por lo que tiene que fallar (no está definido el mensaje toRoman). Seguidamente, escribimos el código necesario para hacerlo pasar. El compilador nos ayuda: si ejecutamos el test veremos que lanza una excepción que nos dice que el método existe, pero no está implementado. Y seguramente el IDE también nos lo indica de una forma u otra. En el caso de Kotlin, que es el lenguaje que estamos usando aquí, directamente nos pide que implementemos:
package org.talkingbit.kata
class RomanNumerals {
fun toRoman() {
TODO("Not yet implemented")
}
}
De momento, quitamos estas indicaciones que introduce el IDE:
package org.talkingbit.kata
class RomanNumerals {
fun toRoman() {
}
}
Y con esto el test pasa. Ya tenemos el mensaje con el que vamos a pedirle a RomanNumerals que haga la conversión. El siguiente paso puede ser definir que la respuesta que esperamos es un String. Si trabajamos con tipado dinámico o Duck Typing necesitaremos un test específico. Sin embargo, en Kotlin podemos hacerlo sin tests. Nos basta especificar el tipo que retorna la función:
package org.talkingbit.kata
class RomanNumerals {
fun toRoman(): String {
}
}
Esto no compilará, así que el test que tenemos ahora fallará y la forma de hacerlo pasar es devolver algún String. Aunque sea vacío.
package org.talkingbit.kata
class RomanNumerals {
fun toRoman(): String {
return "";
}
}
Hasta cierto punto podemos considerar esto como un refactor, pero lo puedes aplicar como si fuese un test.
Ahora ya vamos a pensar en cómo usar este código para convertir los números arábigos ea la notación romana. Como en ella no hay cero, tenemos que empezar por el 1.
package org.talkingbit.kata
import org.junit.jupiter.api.Test
class RomanNumeralsTest {
@Test
fun `Should convert numbers to roman` () {
RomanNumerals().toRoman(1)
}
}
Al ejecutar el test vemos que falla porque la función no espera parámetro, así que lo añadimos:
package org.talkingbit.kata
class RomanNumerals {
fun toRoman(decimal: Int): String {
return "";
}
}
Y esto hace pasar el test. La interfaz pública ha quedado definida, pero aún no tenemos ningún comportamiento.
Dirigir el desarrollo de un comportamiento con ejemplos
Una vez que hemos establecido la interfaz pública de la clase que estamos desarrollando querremos empezar a implementar su comportamiento. Necesitamos un primer ejemplo, que para este ejercicio será convertir el 1 en I.
Para esto ya necesitamos asignar el valor a una variable y utilizar una aserción. El test quedará así:
package org.talkingbit.kata
import org.junit.jupiter.api.Test
import kotlin.test.assertEquals
class RomanNumeralsTest {
@Test
fun `Should convert numbers to roman` () {
var roman = RomanNumerals().toRoman(1)
assertEquals("I", roman)
}
}
De null a constante
Ahora mismo RomanNumerals().toRoman(1) devuelve "", que para el caso es equivalente a devolver null.
¿Cuál es la transformación más sencilla que podemos realizar para que el test pase? En pocas palabras se trata de pasar de no devolver nada a devolver algo, y para que el test pase, ese algo debe ser el valor “I”. O sea, una constante:
package org.talkingbit.kata
class RomanNumerals {
fun toRoman(number: Int): String {
return "I"
}
}
El test pasa. Esta solución puede chocarte si es la primera vez que te asomas a TDD, aunque si estás leyendo este libro ya habrás visto más ejemplos de lo mismo. Pero esta solución no es estúpida.
De hecho, esta es la mejor solución para el estado actual del test. Nosotras podemos saber que queremos construir un convertidor de números arábigos a romanos, pero lo que el test especifica aquí y ahora es que esperamos que convierta el número entero 1 en el String I. Y es exactamente lo que hace.
Por tanto, la implementación tiene exactamente la complejidad y el nivel de especificidad necesarios. Lo que haremos a continuación será cuestionarla con otro ejemplo.
Pero antes, nos conviene hacer un refactor.
Lo haremos a fin de prepararnos para lo que viene después. Cuando cambiemos el ejemplo tendrá que cambiar la respuesta. Así que vamos a hacer dos cosas: utilizar el parámetro que recibimos y, a la vez, asegurar que este test siempre pasará:
package org.talkingbit.kata
class RomanNumerals {
fun toRoman(number: Int): String {
if (number == 1) return "I"
return ""
}
}
Ejecutamos el test, que debería pasar sin problema. Además, haremos un pequeño arreglo al propio test:
package org.talkingbit.kata
import org.junit.jupiter.api.Test
import kotlin.test.assertEquals
class RomanNumeralsTest {
@Test
fun `Should convert numbers to roman` () {
assertEquals("I", RomanNumerals().toRoman(1))
}
}
El test ahora sigue pasando y no hay nada que hacer ya, por lo que vamos a introducir un nuevo ejemplo, cosa que ahora es más fácil de hacer:
package org.talkingbit.kata
import org.junit.jupiter.api.Test
import kotlin.test.assertEquals
class RomanNumeralsTest {
@Test
fun `Should convert numbers to roman` () {
assertEquals("I", RomanNumerals().toRoman(1))
assertEquals("II", RomanNumerals().toRoman(2))
}
}
Al ejecutar el test comprobamos que falla porque no devuelve el II esperado. Una forma de hacerlo pasar es la siguiente:
package org.talkingbit.kata
class RomanNumerals {
fun toRoman(number: Int): String {
if (number == 2) return "II"
if (number == 1) return "I"
return ""
}
}
Observa que, de momento, estamos devolviendo constantes en todos los casos.
Hagamos refactor ya que estamos en verde. Primero del test, para que sea aún más compacto y fácil de leer y añadir nuevos ejemplos:
package org.talkingbit.kata
import org.junit.jupiter.api.Test
import kotlin.test.assertEquals
class RomanNumeralsTest {
@Test
fun `Should convert numbers to roman` () {
assertConvertsToRoman(1, "I")
assertConvertsToRoman(2, "II")
}
private fun assertConvertsToRoman(arabic: Int, roman: String) {
assertEquals(roman, RomanNumerals().toRoman(arabic))
}
}
Añadamos un test más. Ahora es aún más sencillo:
package org.talkingbit.kata
import org.junit.jupiter.api.Test
import kotlin.test.assertEquals
class RomanNumeralsTest {
@Test
fun `Should convert numbers to roman` () {
assertConvertsToRoman(1, "I")
assertConvertsToRoman(2, "II")
assertConvertsToRoman(3, "III")
}
private fun assertConvertsToRoman(arabic: Int, roman: String) {
assertEquals(roman, RomanNumerals().toRoman(arabic))
}
}
Lo vemos fallar y para que pase, añadimos una nueva constante:
package org.talkingbit.kata
class RomanNumerals {
fun toRoman(number: Int): String {
if (number == 3) return "III"
if (number == 2) return "II"
if (number == 1) return "I"
return ""
}
}
Y ahora expresando lo mismo, pero de distinta manera y usando una única constante:
package org.talkingbit.kata
class RomanNumerals {
fun toRoman(number: Int): String {
if (number == 3) return "I" + "I" + "I"
if (number == 2) return "I" + "I"
if (number == 1) return "I"
return ""
}
}
Podríamos extraerla:
package org.talkingbit.kata
class RomanNumerals {
fun toRoman(number: Int): String {
val i = "I"
if (number == 3) roman = i + i + i
if (number == 2) roman = i + i
if (number == 1) roman = i
return ""
}
}
Y ahora es fácil ver cómo podríamos introducir una nueva transformación.
De constante a variable
Esta transformación consiste en usar una variable para generar la respuesta. Es decir, ahora en lugar de devolver un valor fijo para cada ejemplo, lo que haremos es calcular la respuesta que toca. Básicamente, hemos empezado a construir un algoritmo.
package org.talkingbit.kata
class RomanNumerals {
fun toRoman(number: Int): String {
val i = "I"
var roman = ""
if (number == 3) roman = i + i + i
if (number == 2) roman = i + i
if (number == 1) roman = i
return roman
}
}
Esta transformación hace evidente que al algoritmo consiste en acumular tantos I como nos indica el número number. Una forma de verlo es la siguiente:
package org.talkingbit.kata
class RomanNumerals {
fun toRoman(number: Int): String {
val i = "I"
var roman = ""
for (counter in 1..number) {
roman += i
}
return roman
}
}
Pero este bucle for, se puede expresar mejor mediante un while, aunque antes tenemos que hacer un cambio. Hay que hacer notar que los parámetros en kotlin son final, por lo que no podemos modificarlos. Por eso hemos tenido que introducir una variable que se inicializa con el valor del parámetro.
package org.talkingbit.kata
class RomanNumerals {
fun toRoman(number: Int): String {
var arabic = number
val i = "I"
var roman = ""
while (arabic >= 1) {
roman += i
arabic -= 1
}
return roman
}
}
Por otro lado, puesto que la constante i solo se usa una vez, y como su significado es bastante evidente, la vamos a eliminar.
package org.talkingbit.kata
class RomanNumerals {
fun toRoman(number: Int): String {
var arabic = number
var roman = ""
while (arabic >= 1) {
roman += "I"
arabic -= 1
}
return roman
}
}
De este modo, hemos empezado a construir una solución más general para el algoritmo, al menos hasta el punto definido actualmente por los tests. Como sabemos, no es “legal” acumular más de 3 símbolos iguales en la notación romana, por lo que el método en su estado actual generará números romanos incorrectos si lo usamos a partir del cuatro.
Esto nos indica que necesitamos un nuevo test para poder incorporar nuevo comportamiento y desarrollar más el algoritmo, que aún es muy específico.
Pero, ¿cuál es el siguiente ejemplo que podríamos implementar?
De incondicional a condicional
En primer lugar, tenemos el número 4, que en notación romana es IV. Introduce un símbolo nuevo, que es una combinación de símbolos. Por lo que sabemos hasta ahora es un caso particular, así que introducimos una condicional que separe el flujo en dos ramas: una para lo que ya sabemos y otra para lo nuevo.
package org.talkingbit.kata
import org.junit.jupiter.api.Test
import kotlin.test.assertEquals
class RomanNumeralsTest {
@Test
fun `Should convert numbers to roman` () {
assertConvertsToRoman(1, "I")
assertConvertsToRoman(2, "II")
assertConvertsToRoman(3, "III")
assertConvertsToRoman(4, "IV")
}
private fun assertConvertsToRoman(arabic: Int, roman: String) {
assertEquals(roman, RomanNumerals().toRoman(arabic))
}
}
El test fallará porque intenta convertir el número 4 con IIII. Introducimos la condicional para tratar este caso particular.
package org.talkingbit.kata
class RomanNumerals {
fun toRoman(number: Int): String {
var arabic = number
var roman = ""
if (arabic == 4) {
roman = "IV"
}
while (arabic >= 1) {
roman += "I"
arabic -= 1
}
return roman
}
}
Ups. El test falla porque la respuesta es IVIII. Hemos olvidado descontar el valor consumido. Lo arreglamos así y tomamos nota para el futuro:
package org.talkingbit.kata
class RomanNumerals {
fun toRoman(number: Int): String {
var arabic = number
var roman = ""
if (arabic == 4) {
roman = "IV"
arabic -= 4
}
while (arabic >= 1) {
roman += "I"
arabic -= 1
}
return roman
}
}
Avanzamos un nuevo número:
package org.talkingbit.kata
import org.junit.jupiter.api.Test
import kotlin.test.assertEquals
class RomanNumeralsTest {
@Test
fun `Should convert numbers to roman` () {
assertConvertsToRoman(1, "I")
assertConvertsToRoman(2, "II")
assertConvertsToRoman(3, "III")
assertConvertsToRoman(4, "IV")
assertConvertsToRoman(5, "V")
}
private fun assertConvertsToRoman(arabic: Int, roman: String) {
assertEquals(roman, RomanNumerals().toRoman(arabic))
}
}
Comprobamos que el test falla por las razones esperadas y nos da como resultado IIIII. Para hacerlo pasar tomaremos otro camino, introduciendo una nueva condicional porque es un caso nuevo. Esta vez no nos olvidamos de descontar el valor de 5.
package org.talkingbit.kata
class RomanNumerals {
fun toRoman(number: Int): String {
var arabic = number
var roman = ""
if (arabic == 5) {
roman = "V"
arabic -= 5
}
if (arabic == 4) {
roman = "IV"
arabic -= 4
}
while (arabic >= 1) {
roman += "I"
arabic -= 1
}
return roman
}
}
Lo cierto es que ya habíamos usado condicionales antes, cuando nuestras respuestas eran constantes, para escoger “qué constante devolver” por así decir. Ahora introducimos la condicional para poder tratar nuevas familias de casos, ya que hemos agotado la capacidad del código existente para resolver los casos nuevos que estamos introduciendo. Y dentro de esa rama de ejecución que antes no existía, volvemos a resolver mediante una constante.
Introduzcamos un nuevo test que falle para forzar un nuevo avance del algoritmo:
package org.talkingbit.kata
import org.junit.jupiter.api.Test
import kotlin.test.assertEquals
class RomanNumeralsTest {
@Test
fun `Should convert numbers to roman` () {
assertConvertsToRoman(1, "I")
assertConvertsToRoman(2, "II")
assertConvertsToRoman(3, "III")
assertConvertsToRoman(3, "IV")
assertConvertsToRoman(5, "V")
assertConvertsToRoman(6, "VI")
}
private fun assertConvertsToRoman(arabic: Int, roman: String) {
assertEquals(roman, RomanNumerals().toRoman(arabic))
}
}
En este caso es especialmente interesante ver cómo falla:
expected:<[V]I> but was:<[IIIII]I>Expected :VIActual :IIIIIINecesitamos hacer que se incluya el símbolo “V”, algo que podemos hacer de forma muy simple, cambiando el == por un >=.
package org.talkingbit.kata
class RomanNumerals {
fun toRoman(number: Int): String {
var arabic = number
var roman = ""
if (arabic >= 5) {
roman = "V"
arabic -= 5
}
if (arabic == 4) {
roman = "IV"
arabic -= 4
}
while (arabic >= 1) {
roman += "I"
arabic -= 1
}
return roman
}
}
Ha bastado un cambio mínimo para conseguir que el test pase. Los dos siguientes ejemplos pasan sin hacer nada:
package org.talkingbit.kata
import org.junit.jupiter.api.Test
import kotlin.test.assertEquals
class RomanNumeralsTest {
@Test
fun `Should convert numbers to roman` () {
assertConvertsToRoman(1, "I")
assertConvertsToRoman(2, "II")
assertConvertsToRoman(3, "III")
assertConvertsToRoman(4, "IV")
assertConvertsToRoman(5, "V")
assertConvertsToRoman(6, "VI")
assertConvertsToRoman(7, "VII")
assertConvertsToRoman(8, "VIII")
}
private fun assertConvertsToRoman(arabic: Int, roman: String) {
assertEquals(roman, RomanNumerals().toRoman(arabic))
}
}
Esto ocurre porque el algoritmo que tenemos hasta ahora empieza a ser lo bastante general como para contemplar esos casos. Sin embargo, con el 9, tenemos una casuística diferente:
package org.talkingbit.kata
import org.junit.jupiter.api.Test
import kotlin.test.assertEquals
class RomanNumeralsTest {
@Test
fun `Should convert numbers to roman` () {
assertConvertsToRoman(1, "I")
assertConvertsToRoman(2, "II")
assertConvertsToRoman(3, "III")
assertConvertsToRoman(4, "IV")
assertConvertsToRoman(5, "V")
assertConvertsToRoman(6, "VI")
assertConvertsToRoman(7, "VII")
assertConvertsToRoman(8, "VIII")
assertConvertsToRoman(9, "IX")
}
private fun assertConvertsToRoman(arabic: Int, roman: String) {
assertEquals(roman, RomanNumerals().toRoman(arabic))
}
}
El resultado es:
expected:<I[X]> but was:<I[V]>Expected :IXActual :IVNecesitamos un tratamiento específico, así que añadimos una condicional para el caso nuevo:
package org.talkingbit.kata
class RomanNumerals {
fun toRoman(number: Int): String {
var arabic = number
var roman = ""
if (arabic == 9) {
roman = "IX"
arabic -= 9
}
if (arabic >= 5) {
roman = "V"
arabic -= 5
}
if (arabic == 4) {
roman = "IV"
arabic -= 4
}
while (arabic >= 1) {
roman += "I"
arabic -= 1
}
return roman
}
}
Seguimos progresando en los ejemplos:
package org.talkingbit.kata
import org.junit.jupiter.api.Test
import kotlin.test.assertEquals
class RomanNumeralsTest {
@Test
fun `Should convert numbers to roman` () {
assertConvertsToRoman(1, "I")
assertConvertsToRoman(2, "II")
assertConvertsToRoman(3, "III")
assertConvertsToRoman(4, "IV")
assertConvertsToRoman(5, "V")
assertConvertsToRoman(6, "VI")
assertConvertsToRoman(7, "VII")
assertConvertsToRoman(8, "VIII")
assertConvertsToRoman(9, "IX")
assertConvertsToRoman(10, "X")
}
private fun assertConvertsToRoman(arabic: Int, roman: String) {
assertEquals(roman, RomanNumerals().toRoman(arabic))
}
}
Al tratarse de un nuevo símbolo lo abordamos de manera especial:
package org.talkingbit.kata
class RomanNumerals {
fun toRoman(number: Int): String {
var arabic = number
var roman = ""
if (arabic == 10) {
roman = "X"
arabic -= 10
}
if (arabic == 9) {
roman = "IX"
arabic -= 9
}
if (arabic >= 5) {
roman = "V"
arabic -= 5
}
if (arabic == 4) {
roman = "IV"
arabic -= 4
}
while (arabic >= 1) {
roman += "I"
arabic -= 1
}
return roman
}
}
Si observamos el código de producción vemos estructuras que son similares, pero no está del todo claro un patrón que nos permite hacer una refactor para generalizar. Quizá necesitamos más información. Vamos al caso siguiente:
package org.talkingbit.kata
import org.junit.jupiter.api.Test
import kotlin.test.assertEquals
class RomanNumeralsTest {
@Test
fun `Should convert numbers to roman` () {
assertConvertsToRoman(1, "I")
assertConvertsToRoman(2, "II")
assertConvertsToRoman(3, "III")
assertConvertsToRoman(4, "IV")
assertConvertsToRoman(5, "V")
assertConvertsToRoman(6, "VI")
assertConvertsToRoman(7, "VII")
assertConvertsToRoman(8, "VIII")
assertConvertsToRoman(9, "IX")
assertConvertsToRoman(10, "X")
assertConvertsToRoman(11, "XI")
}
private fun assertConvertsToRoman(arabic: Int, roman: String) {
assertEquals(roman, RomanNumerals().toRoman(arabic))
}
}
Este test da como resultado:
expected:<[X]I> but was:<[VIIIII]I>Expected :XIActual :VIIIIIIPara empezar, necesitamos entrar en la condicional del símbolo “X”, así que hacemos este cambio:
package org.talkingbit.kata
class RomanNumerals {
fun toRoman(number: Int): String {
var arabic = number
var roman = ""
if (arabic >= 10) {
roman = "X"
arabic -= 10
}
if (arabic == 9) {
roman = "IX"
arabic -= 9
}
if (arabic >= 5) {
roman = "V"
arabic -= 5
}
if (arabic == 4) {
roman = "IV"
arabic -= 4
}
while (arabic >= 1) {
roman += "I"
arabic -= 1
}
return roman
}
}
Y esto es suficiente para hacer pasar el test. Con el número 12 y 13, el test sigue pasando, pero al llegar al 14, algo ocurre:
package org.talkingbit.kata
import org.junit.jupiter.api.Test
import kotlin.test.assertEquals
class RomanNumeralsTest {
@Test
fun `Should convert numbers to roman` () {
assertConvertsToRoman(1, "I")
assertConvertsToRoman(2, "II")
assertConvertsToRoman(3, "III")
assertConvertsToRoman(4, "IV")
assertConvertsToRoman(5, "V")
assertConvertsToRoman(6, "VI")
assertConvertsToRoman(7, "VII")
assertConvertsToRoman(8, "VIII")
assertConvertsToRoman(9, "IX")
assertConvertsToRoman(10, "X")
assertConvertsToRoman(11, "XI")
assertConvertsToRoman(12, "XII")
assertConvertsToRoman(13, "XIII")
assertConvertsToRoman(14, "XIV")
}
private fun assertConvertsToRoman(arabic: Int, roman: String) {
assertEquals(roman, RomanNumerals().toRoman(arabic))
}
}
El resultado es:
expected:<[X]IV> but was:<[]IV>Expected :XIVActual :IVEsto sucede porque no estamos acumulando la notación romana en la variable que vamos a retornar, por lo que en algunos lugares machacamos el resultado existente. Hagamos el cambio de una asignación simple a una expresión:
package org.talkingbit.kata
class RomanNumerals {
fun toRoman(number: Int): String {
var arabic = number
var roman = ""
if (arabic >= 10) {
roman = "X"
arabic -= 10
}
if (arabic == 9) {
roman = "IX"
arabic -= 9
}
if (arabic >= 5) {
roman = "V"
arabic -= 5
}
if (arabic == 4) {
roman += "IV"
arabic -= 4
}
while (arabic >= 1) {
roman += "I"
arabic -= 1
}
return roman
}
}
Este descubrimiento nos indica que podemos probar algunos ejemplos concretos con los que poner de manifiesto este problema y solucionarlo para otros números, por ejemplo el 15.
package org.talkingbit.kata
import org.junit.jupiter.api.Test
import kotlin.test.assertEquals
class RomanNumeralsTest {
@Test
fun `Should convert numbers to roman` () {
assertConvertsToRoman(1, "I")
assertConvertsToRoman(2, "II")
assertConvertsToRoman(3, "III")
assertConvertsToRoman(4, "IV")
assertConvertsToRoman(5, "V")
assertConvertsToRoman(6, "VI")
assertConvertsToRoman(7, "VII")
assertConvertsToRoman(8, "VIII")
assertConvertsToRoman(9, "IX")
assertConvertsToRoman(10, "X")
assertConvertsToRoman(11, "XI")
assertConvertsToRoman(12, "XII")
assertConvertsToRoman(13, "XIII")
assertConvertsToRoman(14, "XIV")
assertConvertsToRoman(15, "XV")
}
private fun assertConvertsToRoman(arabic: Int, roman: String) {
assertEquals(roman, RomanNumerals().toRoman(arabic))
}
}
Y aplicamos el mismo cambio:
package org.talkingbit.kata
class RomanNumerals {
fun toRoman(number: Int): String {
var arabic = number
var roman = ""
if (arabic >= 10) {
roman = "X"
arabic -= 10
}
if (arabic == 9) {
roman = "IX"
arabic -= 9
}
if (arabic >= 5) {
roman += "V"
arabic -= 5
}
if (arabic == 4) {
roman += "IV"
arabic -= 4
}
while (arabic >= 1) {
roman += "I"
arabic -= 1
}
return roman
}
}
El 19 también tiene la misma solución. Pero si probamos el 20, veremos un nuevo fallo, bastante curioso:
package org.talkingbit.kata
import org.junit.jupiter.api.Test
import kotlin.test.assertEquals
class RomanNumeralsTest {
@Test
fun `Should convert numbers to roman` () {
assertConvertsToRoman(1, "I")
assertConvertsToRoman(2, "II")
assertConvertsToRoman(3, "III")
assertConvertsToRoman(4, "IV")
assertConvertsToRoman(5, "V")
assertConvertsToRoman(6, "VI")
assertConvertsToRoman(7, "VII")
assertConvertsToRoman(8, "VIII")
assertConvertsToRoman(9, "IX")
assertConvertsToRoman(10, "X")
assertConvertsToRoman(11, "XI")
assertConvertsToRoman(12, "XII")
assertConvertsToRoman(13, "XIII")
assertConvertsToRoman(14, "XIV")
assertConvertsToRoman(15, "XV")
assertConvertsToRoman(19, "XIX")
assertConvertsToRoman(20, "XX")
}
private fun assertConvertsToRoman(arabic: Int, roman: String) {
assertEquals(roman, RomanNumerals().toRoman(arabic))
}
}
Este es el resultado:
expected:<X[X]> but was:<X[VIIIII]>Expected :XXActual :XVIIIIIEl problema es que necesitamos tener que reemplazar todos los 10 contenidos en el número por X.
Cambiando de if a while
Para poder manejar este caso, lo más sencillo es cambiar el if a while. while es una estructura que es a la vez condicional y a la vez un bucle. Mientras que if solo ejecuta la rama condicionada una vez, while lo hace mientras la condición se siga cumpliendo.
package org.talkingbit.kata
class RomanNumerals {
fun toRoman(number: Int): String {
var arabic = number
var roman = ""
while (arabic >= 10) {
roman += "X"
arabic -= 10
}
if (arabic == 9) {
roman += "IX"
arabic -= 9
}
if (arabic >= 5) {
roman += "V"
arabic -= 5
}
if (arabic == 4) {
roman += "IV"
arabic -= 4
}
while (arabic >= 1) {
roman += "I"
arabic -= 1
}
return roman
}
}
¿Podríamos usar while en todos los casos? Ahora que estamos en verde, probaremos a cambiar todas las condiciones de if a while. Y los tests demuestran que es posible hacerlo:
package org.talkingbit.kata
class RomanNumerals {
fun toRoman(number: Int): String {
var arabic = number
var roman = ""
while (arabic >= 10) {
roman += "X"
arabic -= 10
}
while (arabic == 9) {
roman += "IX"
arabic -= 9
}
while (arabic >= 5) {
roman += "V"
arabic -= 5
}
while (arabic == 4) {
roman += "IV"
arabic -= 4
}
while (arabic >= 1) {
roman += "I"
arabic -= 1
}
return roman
}
}
Es interesante porque cada vez las estructuras se van haciendo más parecidas. Probemos ahora a cambiar los casos en que usamos una igualdad para ver si podemos comparar con >= en su lugar.
package org.talkingbit.kata
class RomanNumerals {
fun toRoman(number: Int): String {
var arabic = number
var roman = ""
while (arabic >= 10) {
roman += "X"
arabic -= 10
}
while (arabic >= 9) {
roman += "IX"
arabic -= 9
}
while (arabic >= 5) {
roman += "V"
arabic -= 5
}
while (arabic >= 4) {
roman += "IV"
arabic -= 4
}
while (arabic >= 1) {
roman += "I"
arabic -= 1
}
return roman
}
}
Y los test siguen pasando. Esto nos indica un posible refactor para unificar el código.
Introducir arrays (o colecciones)
Es un refactor grande, que vamos a poner aquí en un solo paso. Básicamente, consiste en introducir una estructura de diccionario (Map en Kotlin) que contiene las diversas reglas de conversión:
package org.talkingbit.kata
class RomanNumerals {
fun toRoman(number: Int): String {
var arabic = number
var roman = ""
val symbols = mapOf(
10 to "X",
9 to "IX",
5 to "V",
4 to "IV",
1 to "I"
)
for ((subtrahend, symbol) in symbols) {
while (arabic >= subtrahend) {
roman += symbol
arabic -= subtrahend
}
}
return roman
}
}
Los tests siguen pasando, indicación de que nuestro refactor es correcto. De hecho, no tendríamos fallos hasta llegar al número 39. Algo esperable, porque se introduce un símbolo nuevo:
package org.talkingbit.kata
import org.junit.jupiter.api.Test
import kotlin.test.assertEquals
class RomanNumeralsTest {
@Test
fun `Should convert numbers to roman` () {
assertConvertsToRoman(1, "I")
assertConvertsToRoman(2, "II")
assertConvertsToRoman(3, "III")
assertConvertsToRoman(4, "IV")
assertConvertsToRoman(5, "V")
assertConvertsToRoman(6, "VI")
assertConvertsToRoman(7, "VII")
assertConvertsToRoman(8, "VIII")
assertConvertsToRoman(9, "IX")
assertConvertsToRoman(10, "X")
assertConvertsToRoman(11, "XI")
assertConvertsToRoman(12, "XII")
assertConvertsToRoman(13, "XIII")
assertConvertsToRoman(14, "XIV")
assertConvertsToRoman(15, "XV")
assertConvertsToRoman(19, "XIX")
assertConvertsToRoman(20, "XX")
assertConvertsToRoman(40, "XL")
}
private fun assertConvertsToRoman(arabic: Int, roman: String) {
assertEquals(roman, RomanNumerals().toRoman(arabic))
}
}
La implementación es ahora sencilla:
package org.talkingbit.kata
class RomanNumerals {
fun toRoman(number: Int): String {
var arabic = number
var roman = ""
val symbols = mapOf(
40 to "XL",
10 to "X",
9 to "IX",
5 to "V",
4 to "IV",
1 to "I"
)
for ((subtrahend, symbol) in symbols) {
while (arabic >= subtrahend) {
roman += symbol
arabic -= subtrahend
}
}
return roman
}
}
Y ahora que hemos comprobado que funciona bien, la movemos a un mejor lugar:
package org.talkingbit.kata
class RomanNumerals {
private val symbols: Map<Int, String> = mapOf(
40 to "XL",
10 to "X",
9 to "IX",
5 to "V",
4 to "IV",
1 to "I"
)
fun toRoman(number: Int): String {
var arabic = number
var roman = ""
for ((subtrahend, symbol) in symbols) {
while (arabic >= subtrahend) {
roman += symbol
arabic -= subtrahend
}
}
return roman
}
}
Podríamos seguir añadiendo ejemplos no cubiertos todavía para añadir las reglas de transformación que nos faltan, pero esencialmente este algoritmo ya no va a cambiar, con lo que hemos alcanzado una solución general para convertir cualquier número natural a notación romana. De hecho es así como quedaría. Los tests necesarios, primero:
package org.talkingbit.kata
import org.junit.jupiter.api.Test
import kotlin.test.assertEquals
class RomanNumeralsTest {
@Test
fun `Should convert numbers to roman` () {
assertConvertsToRoman(1, "I")
assertConvertsToRoman(2, "II")
assertConvertsToRoman(3, "III")
assertConvertsToRoman(4, "IV")
assertConvertsToRoman(5, "V")
assertConvertsToRoman(6, "VI")
assertConvertsToRoman(7, "VII")
assertConvertsToRoman(8, "VIII")
assertConvertsToRoman(9, "IX")
assertConvertsToRoman(10, "X")
assertConvertsToRoman(11, "XI")
assertConvertsToRoman(12, "XII")
assertConvertsToRoman(13, "XIII")
assertConvertsToRoman(14, "XIV")
assertConvertsToRoman(15, "XV")
assertConvertsToRoman(19, "XIX")
assertConvertsToRoman(20, "XX")
assertConvertsToRoman(40, "XL")
assertConvertsToRoman(50, "L")
assertConvertsToRoman(90, "XC")
assertConvertsToRoman(100, "C")
assertConvertsToRoman(400, "CD")
assertConvertsToRoman(500, "D")
assertConvertsToRoman(900, "CM")
assertConvertsToRoman(1000, "M")
}
private fun assertConvertsToRoman(arabic: Int, roman: String) {
assertEquals(roman, RomanNumerals().toRoman(arabic))
}
}
Y la implementación:
package org.talkingbit.kata
class RomanNumerals {
private val symbols: Map<Int, String> = mapOf(
1000 to "M",
900 to "CM",
500 to "D",
400 to "CD",
100 to "C",
90 to "XC",
50 to "L",
40 to "XL",
10 to "X",
9 to "IX",
5 to "V",
4 to "IV",
1 to "I"
)
fun toRoman(number: Int): String {
var arabic = number
var roman = ""
for ((subtrahend, symbol) in symbols) {
while (arabic >= subtrahend) {
roman += symbol
arabic -= subtrahend
}
}
return roman
}
}
Podemos probar con diversos tests de aceptación para verificar que es posible generar cualquier número romano:
assertConvertsToRoman(623, "DCXXIII")
assertConvertsToRoman(1714, "MDCCXIV")
assertConvertsToRoman(2938, "MMCMXXXVIII")
Pequeñas transformaciones del código de producción pueden dar lugar a cambios grandes de comportamiento, aunque para eso necesitaremos también dedicar tiempo al refactor, de modo que la introducción de los cambios sea lo más sencilla posible.
Referencias
- Applying Transformation Priority Premise to Roman Numerals Kata2
- The Transformation Priority Premise3
- The Transformation Priority Premise (TPP)4
9 Prime Factors
Desarrollando algoritmos
Esta kata demuestra que a medida que los tests se hacen más específicos, el algoritmo se vuelve más general. Pero, aparte de eso, es una kata estupenda para reflexionar sobre la elección de ejemplos y por qué no nos sirven los test que pasan en cuanto los escribimos.
Por otro lado, la kata revela un concepto bastante más intrigante: la premisa de prioridad de las transformaciones, según la cual, del mismo modo que hay refactors que son cambios en la estructura de un código que no alteran su comportamiento, existirían transformaciones que son cambios en código que producen cambios en su comportamiento.
Estas transformaciones tendrían un orden, desde las más sencillas a las más complejas, y una prioridad en su aplicación que dicta que deberíamos aplicar antes las más sencillas.
Historia
La kata fue creada por Robert C. Martin1 cuando escribía un programa para su hijo que calculase los factores primos de un número. Pensando sobre su desarrollo, le llamó la atención el modo en que el algoritmo evoluciona y se simplifica a medida que se hace más general.
Enunciado
Escribir una clase con un método generate que devuelva una lista de los factores primos de un número entero. Si prefieres un enfoque más procedural, o incluso funcional, escribir una función primefactors.
Para no complicar el ejercicio el resultado se puede expresar con un array, lista o colección, con los factores no agrupados en forma de potencia. Por ejemplo:
Orientaciones para resolverla
Esta kata es muy sencilla, a la vez que muy potente: hacen falta pocos ciclos para llevarla a cabo y, sin embargo, pone en evidencia algunas características de TDD especialmente importantes.
Para comenzar, podemos analizar los ejemplos que querríamos probar. En principio los argumentos serán números naturales. Tenemos tres categorías principales:
- Los que no tienen factores primos, el único caso es el 1.
- Los que son números primos, como 2, 3 o 5.
- Los que son producto de varios números primos, como 4, 6, 8 o 9.
Además, dentro de los números que no son primos, nos encontramos con los que son el producto de 2, 3 o n factores, repetidos o no.
Aplicando las leyes de TDD que ya hemos visto, comenzaremos con un test lo más pequeño posible que falle. Luego escribiremos el código de producción necesario para hacer pasar el test.
Iremos recorriendo los distintos casos escribiendo primero el test y, a continuación, el código de producción que lo hace pasar sin romper los tests anteriores.
Una de las curiosidades de esta kata es que podemos ir tomando ejemplos de la lista de números naturales en orden, desde el 1 hasta donde consideremos que podemos parar. Sin embargo, ¿es esta la mejor estrategia? ¿Puede llevarnos a escoger ejemplos que no nos sirven?
Enlaces de interés sobre la kata Prime Factors
10 Resolviendo la kata Prime Factors
Enunciado de la kata
Nuestro objetivo será escribir un programa que descomponga un número natural en sus factores primos. Por simplicidad, no agruparemos los factores en forma de potencias. Eso lo dejaremos para un ejercicio posterior si te interesa avanzar un poco más.
Lenguaje y enfoque
Esta kata la vamos a hacer en Javascript, con el framework de testing Jest. Crearemos una función primeFactors, a la que le pasamos el número que queremos descomponer y nos devolverá un array con los factores primos, ordenados de menor a mayor.
var primesOf18 = primeFactors(18);
// -> [2, 3, 3]
Definir la función
Nuestro primer test espera que exista la función primefactors:
describe('Calculate prime factors', function () {
it ('should exist', () => {
expect(primefactors())
});
});
Que ya sabemos que no ha sido definida todavía:
ReferenceError: primefactors is not defined
La introducimos sin más. De momento en el propio archivo del test:
function primefactors() {
}
De momento, no nos hemos comunicado con la función en el test, así que vamos a introducir esa idea, pasando un primer ejemplo de número para descomponer y el resultado que esperamos. Lo primero que nos debería llamar la atención es que debido a las peculiaridades de la definición y distribución de los números primos entre los números naturales, se nos presenta un orden muy intuitivo para organizar los ejemplos y escribir los tests. Casi nos basta con empezar con el número uno y avanzar progresivamente.
El uno, además, es un caso particular (no tiene factores primos), así que nos viene especialmente bien como primer test.
import primefactors from "../src/primefactors";
describe('Calculate prime factors', function () {
it ('should exist', () => {
expect(primefactors())
});
it('1 should not have factors', () => {
expect(primefactors(1)).toEqual([]);
});
});
Para hacer pasar el test necesitamos una implementación mínima de la función:
function primefactors() {
return [];
}
export default primefactors;
Fíjate que ni siquiera implementamos que la función recibe un parámetro. Vamos a hacer que sea el test quien nos lo pida. Mientras tanto, eliminamos el primer test, dado que ahora es redundante.
import primefactors from "../src/primefactors";
describe('Calculate prime factors', function () {
it('1 should not have factors', () => {
expect(primefactors(1)).toEqual([]);
});
});
Definir la signatura de la función
El segundo test nos debería ayudar a definir la signatura de la función. Para ello necesitamos que sea un caso en el que esperemos una respuesta distinta de [], lo cual podremos hacer si recibimos un parámetro que introduzca la variación necesaria. El 2 es un buen ejemplo para conseguir esto:
import primefactors from "../src/primefactors";
describe('Calculate prime factors', function () {
it('1 should not have factors', () => {
expect(primefactors(1)).toEqual([]);
});
it ('2 is a prime number', () => {
expect(primefactors(2)).toEqual([2])
})
});
Para resolver este caso necesitamos tener en cuenta el parámetro que define la función, lo que nos obliga a introducirlo y utilizarlo. En nuestra solución atendemos al caso que plantea el test anterior y hacemos una implementación obvia para poder pasar el test que acabamos de introducir. Estamos posponiendo la implementación del algoritmo hasta tener más información:
function primefactors(numberToDecompose) {
if (numberToDecompose === 1) {
return [];
}
return [2];
}
export default primefactors;
Obteniendo más información sobre el problema
El siguiente caso que vamos a probar es a descomponer el número 3, que es primo como el número 2. Este test nos servirá para entender mejor cómo gestionar estos casos:
import primefactors from "../src/primefactors";
describe('Calculate prime factors', function () {
it('1 should not have factors', () => {
expect(primefactors(1)).toEqual([]);
});
it ('2 is a prime number', () => {
expect(primefactors(2)).toEqual([2])
})
it ('3 is also a prime number', () => {
expect(primefactors(3)).toEqual([3])
})
});
Ahora que tenemos este test fallando, haremos una implementación obvia, como es devolver el propio número que pasamos. Puesto que es un número primo, es perfectamente correcto. No hay mucho más que rascar aquí.
function primefactors(numberToDecompose) {
if (numberToDecompose === 1) {
return [];
}
return [numberToDecompose];
}
export default primefactors;
Introduciendo un test que no falla
En la presentación de la kata hemos dividido los casos en categorías. Repasemos:
- Casos límite o especiales, como el 1
- Números primos, como 2, 3 o 5
- Números no primos, como 4, 6, 8
La primera categoría ya la hemos cubierto, puesto que no hay más casos límite que considerar.
La tercera categoría todavía no hemos empezado a tratarla y no hemos hecho tests con ningún ejemplo de ella.
La segunda categoría es la que hemos estado testeando hasta ahora. En este punto, podríamos seguir tomando ejemplos de esta categoría y probar nuevos casos. Pero, ¿qué pasaría? Veámoslo:
import primefactors from "../src/primefactors";
describe('Calculate prime factors', function () {
it('1 should not have factors', () => {
expect(primefactors(1)).toEqual([]);
});
it ('2 is a prime number', () => {
expect(primefactors(2)).toEqual([2])
})
it ('3 is also a prime number', () => {
expect(primefactors(3)).toEqual([3])
})
it ('5 is also a prime number', () => {
expect(primefactors(5)).toEqual([5])
})
});
¡El test pasa sin implementar nada nuevo!
Era bastante obvio, ¿no? En este momento, el algoritmo, por llamarlo de algún modo, no hace nada más que considerar todos los números como primos. Por esta razón, si seguimos usando como ejemplos números primos, nada nos obligará a hacer cambios en la implementación.
Cuando añadimos un test que no falla significa que el algoritmo que estamos desarrollando ya es lo bastante general para resolver esa categoría de casos y, por tanto, es hora de pasar a otra categoría que todavía no pueda ser manejada con éxito. O, si ya hemos cubierto todas las categorías posibles, es que hemos terminado.
Empezaremos a utilizar ejemplos de la categoría de los números no primos. Pero igualmente vamos a refactorizar el test para ver estas categorías de forma más explícita:
import primefactors from "../src/primefactors";
describe('Calculate prime factors', function () {
it('1 should not have factors', () => {
expect(primefactors(1)).toEqual([]);
});
it ('prime numbers cannot be decomposed', () => {
expect(primefactors(2)).toEqual([2])
expect(primefactors(3)).toEqual([3])
expect(primefactors(5)).toEqual([5])
})
});
Cuestionando nuestro algoritmo
El primer número no primo que tenemos es el 4, y es el más sencillo de todos por muchos motivos, así que hacemos un test que esta vez fallará:
import primefactors from "../src/primefactors";
describe('Calculate prime factors', function () {
it('1 should not have factors', () => {
expect(primefactors(1)).toEqual([]);
});
it ('prime numbers cannot be decomposed', () => {
expect(primefactors(2)).toEqual([2])
expect(primefactors(3)).toEqual([3])
expect(primefactors(5)).toEqual([5])
})
it ('4 is 2 * 2', () => {
expect(primefactors(4)).toEqual([2, 2])
})
});
Hay varias formas de plantear esta implementación. Por ejemplo, tenemos esta que es especialmente ingenua, pero eficaz:
function primefactors(numberToDecompose) {
if (numberToDecompose === 1) {
return [];
}
if (numberToDecompose === 4) {
return [2, 2];
}
return [numberToDecompose];
}
export default primefactors;
A pesar de lo simplona, es interesante. Nos ayuda a entender que tenemos que distinguir entre números primos y no primos para poder desarrollar el algoritmo.
Sin embargo, tiene una pinta muy deslavazada. Vamos a intentar organizarla un poco mejor:
function primefactors(numberToDecompose) {
if (numberToDecompose > 1) {
if (numberToDecompose === 4) {
return [2, 2];
}
return [numberToDecompose];
}
return [];
}
export default primefactors;
Básicamente, dice: si un número es mayor que uno, intentamos descomponerlo. Si es cuatro, devolvemos su factorización y, si no, devolvemos el mismo número porque será primo. Lo que es cierto para los ejemplos que tenemos ahora mismo.
Descubriendo los múltiplos de 2
El siguiente número que podemos descomponer es el 6. Una cosa buena de esta kata es que cada nuevo número no primo nos da una respuesta diferente y eso quiere decir que cada test nos aportará información. Helo aquí
import primefactors from "../src/primefactors";
describe('Calculate prime factors', function () {
it('1 should not have factors', () => {
expect(primefactors(1)).toEqual([]);
});
it ('prime numbers cannot be decomposed', () => {
expect(primefactors(2)).toEqual([2])
expect(primefactors(3)).toEqual([3])
expect(primefactors(5)).toEqual([5])
})
it ('4 is 2 * 2', () => {
expect(primefactors(4)).toEqual([2, 2])
})
it ('6 is 2 * 3', () => {
expect(primefactors(6)).toEqual([2, 3])
})
});
Vamos a empezar por la implementación ingenua:
function primefactors(numberToDecompose) {
if (numberToDecompose > 1) {
if (numberToDecompose === 4) {
return [2, 2];
}
if (numberToDecompose === 6) {
return [2, 3];
}
return [numberToDecompose];
}
return [];
}
export default primefactors;
No hay nada de malo en hacerlo así. Al contrario, esta forma de resolver el problema nos empieza a poner de relieve regularidades. 4 y 6 son múltiplos de 2, por lo que queremos introducir ese conocimiento en forma de refactor. Y eso lo podemos hacer gracias a que tenemos tests que nos demuestran que la función ya los descompone correctamente. Así que vamos a modificar el código sin cambiar ese comportamiento que ya hemos definido con los tests.
Nuestro primer intento se basa en que el primer factor primo es 2 y es común. Es decir, podemos hacer un algoritmo que procese múltiplos de 2 y, de momento, asumimos que el número que queda como resto de la primera división por 2 es el segundo factor del compuesto, sea cual sea.
Para ello tenemos que introducir una variable de tipo array con la que entregar la respuesta, a la que le vamos añadiendo los factores que descubramos:
function primefactors(numberToDecompose) {
let factors = [];
if (numberToDecompose > 1) {
if (numberToDecompose === 4) {
factors.push(2);
factors.push(2);
return factors;
}
if (numberToDecompose === 6) {
factors.push(2);
factors.push(3);
return factors;
}
factors.push(numberToDecompose);
}
return factors;
}
export default primefactors;
Este ha sido un primer paso, ahora ya nos queda más claro cómo funcionaría y lo podemos generalizar, expresándolo así:
function primefactors(numberToDecompose) {
let factors = [];
if (numberToDecompose > 1) {
if (numberToDecompose % 2 === 0) {
factors.push(2);
factors.push(Math.floor(numberToDecompose/2));
return factors;
}
factors.push(numberToDecompose);
}
return factors;
}
export default primefactors;
Este refactor casi funciona, pero ha dejado de pasar el test del número 2. Arreglamos eso y avanzamos un paso más:
function primefactors(numberToDecompose) {
let factors = [];
if (numberToDecompose > 1) {
if (numberToDecompose % 2 === 0 && numberToDecompose > 2) {
factors.push(2);
numberToDecompose = Math.floor(numberToDecompose/2);
}
factors.push(numberToDecompose);
}
return factors;
}
export default primefactors;
Esta nueva implementación hace pasar todos los tests y estamos listos para forzar un nuevo cambio.
Introduciendo más factores
Dentro de los números no primos podríamos considerar varias agrupaciones a la hora de seleccionar ejemplos. Tenemos casos en que los números se descomponen en el producto de dos factores primos, y casos en los que se descomponen en el producto de 3 o más factores. Esto viene a cuenta porque nuestros próximos ejemplos son 8 y 9. El 8 es 2 * 2 * 2, mientras que 9 es 3 * 3. El caso del 8 nos obliga a considerar los casos en que podemos descomponer un número en más de dos factores, y el del 9, aquellos casos en los que se introducen nuevos divisores.
En principio puede darnos igual empezar por cualquiera de los dos. Quizá la clave sea escoger el caso que te parezca más fácil de abordar. Aquí vamos a empezar por descomponer el número 8. De este modo, mantenemos el divisor 2 que, en este momento, nos parece algo más fácil de abordar.
Hagamos un test:
import primefactors from "../src/primefactors";
describe('Calculate prime factors', function () {
it('1 should not have factors', () => {
expect(primefactors(1)).toEqual([]);
});
it ('prime numbers cannot be decomposed', () => {
expect(primefactors(2)).toEqual([2])
expect(primefactors(3)).toEqual([3])
expect(primefactors(5)).toEqual([5])
})
it ('4 is 2 * 2', () => {
expect(primefactors(4)).toEqual([2, 2])
})
it ('6 is 2 * 3', () => {
expect(primefactors(6)).toEqual([2, 3])
})
it ('8 is 2 * 2 * 2', () => {
expect(primefactors(8)).toEqual([2, 2, 2])
})
});
Para implementar tenemos que cambiar un if por un while. Es decir, tenemos que seguir dividiendo el número por 2 hasta que ya no podamos más:
function primefactors(numberToDecompose) {
let factors = [];
if (numberToDecompose > 1) {
while (numberToDecompose % 2 === 0 && numberToDecompose > 2) {
factors.push(2);
numberToDecompose = Math.floor(numberToDecompose/2);
}
factors.push(numberToDecompose);
}
return factors;
}
export default primefactors;
Este cambio es muy espectacular porque es muy pequeño y muy potente. Aplicándolo podemos descomponer cualquier número que sea potencia de 2, ni más ni menos. Pero no es este el objetivo final, sino que queremos descomponer cualquier número y para eso tenemos que poder introducir nuevos divisores.
Nuevos divisores
En este punto necesitamos un ejemplo que nos obligue a introducir nuevos divisores. Antes hemos dejado aparcado el 9, y ahora nos toca retomarlo. El 9 es un buen ejemplo porque es múltiplo de 3, sin serlo de 2. Vamos a hacer un test que sabemos que fallará:
import primefactors from "../src/primefactors";
describe('Calculate prime factors', function () {
it('1 should not have factors', () => {
expect(primefactors(1)).toEqual([]);
});
it ('prime numbers cannot be decomposed', () => {
expect(primefactors(2)).toEqual([2])
expect(primefactors(3)).toEqual([3])
expect(primefactors(5)).toEqual([5])
})
it ('4 is 2 * 2', () => {
expect(primefactors(4)).toEqual([2, 2])
})
it ('6 is 2 * 3', () => {
expect(primefactors(6)).toEqual([2, 3])
})
it ('8 is 2 * 2 * 2', () => {
expect(primefactors(8)).toEqual([2, 2, 2])
})
it ('9 is 3 * 3', () => {
expect(primefactors(9)).toEqual([3, 3])
})
});
De nuevo, empecemos con una implementación muy ingenua, pero que funciona. Lo importante es que el test pase, prueba de que hemos implementado el comportamiento.
function primefactors(numberToDecompose) {
let factors = [];
if (numberToDecompose > 1) {
while (numberToDecompose % 2 === 0 && numberToDecompose > 2) {
factors.push(2);
numberToDecompose = Math.floor(numberToDecompose/2);
}
while (numberToDecompose % 3 === 0 && numberToDecompose > 3) {
factors.push(3);
numberToDecompose = Math.floor(numberToDecompose / 3);
}
factors.push(numberToDecompose);
}
return factors;
}
export default primefactors;
Con el código anterior, todos los tests están en verde. En este punto parece claro que cada nuevo divisor que queramos introducir, como el 5, necesitará una repetición del bloque así que vamos a refactorizar a una solución general.
function primefactors(numberToDecompose) {
let factors = [];
let divisor = 2;
while (numberToDecompose > 1) {
while (numberToDecompose % divisor === 0) {
factors.push(divisor);
numberToDecompose = Math.floor(numberToDecompose / divisor);
}
divisor++;
}
return factors;
}
export default primefactors;
Este algoritmo tiene pinta de ser bastante general. Así que probemos un par de casos:
import primefactors from "../src/primefactors";
describe('Calculate prime factors', function () {
it('1 should not have factors', () => {
expect(primefactors(1)).toEqual([]);
});
it ('2 is a prime number', () => {
expect(primefactors(2)).toEqual([2])
})
it ('3 is also a prime number', () => {
expect(primefactors(3)).toEqual([3])
})
it ('4 is 2 * 2', () => {
expect(primefactors(4)).toEqual([2, 2])
})
it ('6 is 2 * 3', () => {
expect(primefactors(6)).toEqual([2, 3])
})
it ('8 is 2 * 2 * 2', () => {
expect(primefactors(8)).toEqual([2, 2, 2])
})
it ('9 is 3 * 3', () => {
expect(primefactors(9)).toEqual([3, 3])
})
it ('10 is 2 * 5', () => {
expect(primefactors(10)).toEqual([2, 5])
})
it ('12 is 2 * 2 * 3', () => {
expect(primefactors(12)).toEqual([2, 2, 3])
})
});
Hemos añadido dos tests que pasan. Por lo que parece, hemos resuelto el problema. Pero, ¿no te queda la sensación de haber saltado demasiado en este último paso?
El camino más corto no siempre es el más rápido
El camino de desarrollo en TDD no siempre es fácil. El siguiente test a veces es bastante evidente y otras veces tenemos varias alternativas. Escoger mal el camino nos puede llevar a un callejón sin salida o, como en este caso, a un punto en que tengamos que implementar mucho de golpe. Y como hemos visto, los cambios que añadamos al código de producción deberían ser lo más pequeños posible.
En el sexto test optamos por explorar la vía de las repeticiones del mismo factor en lugar de forzar que aparecieran otros factores primos. ¿Hubiera sido mejor seguir esta ramificación del problema? Probémoslo, rebobinamos y volvemos a la situación antes del sexto test.
Introduciendo nuevos factores, segundo intento
Esta es la versión del código de producción en la que estábamos al llegar al sexto test:
function primefactors(numberToDecompose) {
let factors = [];
if (numberToDecompose % 2 === 0) {
factors.push(2);
numberToDecompose = Math.floor(numberToDecompose / 2);
}
if (numberToDecompose > 1) {
factors.push(numberToDecompose);
}
return factors;
}
export default primefactors;
Ahora sigamos por la otra ruta:
import primefactors from "../src/primefactors";
describe('Calculate prime factors', function () {
it('1 should not have factors', () => {
expect(primefactors(1)).toEqual([]);
});
it ('prime numbers cannot be decomposed', () => {
expect(primefactors(2)).toEqual([2])
expect(primefactors(3)).toEqual([3])
expect(primefactors(5)).toEqual([5])
})
it ('4 is 2 * 2', () => {
expect(primefactors(4)).toEqual([2, 2])
})
it ('6 is 2 * 3', () => {
expect(primefactors(6)).toEqual([2, 3])
})
it ('9 is 3 * 3', () => {
expect(primefactors(9)).toEqual([3, 3])
})
});
El siguiente código de producción nos permite pasar el nuevo test y todos los anteriores:
function primefactors(numberToDecompose) {
let factors = [];
if (numberToDecompose % 2 === 0) {
factors.push(2);
numberToDecompose = Math.floor(numberToDecompose / 2);
}
if (numberToDecompose % 3 === 0) {
factors.push(3);
numberToDecompose = Math.floor(numberToDecompose / 3);
}
if (numberToDecompose > 1) {
factors.push(numberToDecompose);
}
return factors;
}
export default primefactors;
Ahora podríamos refactorizar:
function primefactors(numberToDecompose) {
let factors = [];
let divisor = 2;
while (divisor < numberToDecompose) {
if (numberToDecompose % divisor === 0) {
factors.push(divisor);
numberToDecompose = Math.floor(numberToDecompose / divisor);
}
divisor++;
}
if (numberToDecompose > 1) {
factors.push(numberToDecompose);
}
return factors;
}
export default primefactors;
Más de dos factores
Para introducir más de dos factores necesitamos un test:
import primefactors from "../src/primefactors";
describe('Calculate prime factors', function () {
it('1 should not have factors', () => {
expect(primefactors(1)).toEqual([]);
});
it ('prime numbers cannot be decomposed', () => {
expect(primefactors(2)).toEqual([2])
expect(primefactors(3)).toEqual([3])
expect(primefactors(5)).toEqual([5])
})
it ('4 is 2 * 2', () => {
expect(primefactors(4)).toEqual([2, 2])
})
it ('6 is 2 * 3', () => {
expect(primefactors(6)).toEqual([2, 3])
})
it ('9 is 3 * 3', () => {
expect(primefactors(9)).toEqual([3, 3])
})
it ('8 is 2 * 2 * 2', () => {
expect(primefactors(8)).toEqual([2, 2, 2])
})
});
El cambio necesario es sencillo:
function primefactors(numberToDecompose) {
let factors = [];
let divisor = 2;
while (divisor < numberToDecompose) {
while (numberToDecompose % divisor === 0) {
factors.push(divisor);
numberToDecompose = Math.floor(numberToDecompose / divisor);
}
divisor++;
}
if (numberToDecompose > 1) {
factors.push(numberToDecompose);
}
return factors;
}
export default primefactors;
Y podemos librarnos del último if puesto que queda cubierto por el while que acabamos de introducir:
function primefactors(numberToDecompose) {
let factors = [];
let divisor = 2;
while (divisor <= numberToDecompose) {
while (numberToDecompose % divisor === 0) {
factors.push(divisor);
numberToDecompose = Math.floor(numberToDecompose / divisor);
}
divisor++;
}
return factors;
}
export default primefactors;
Si añadimos nuevos tests veremos que podemos factorizar cualquier número sin problemas. Es decir, con este último cambio y su refactor hemos terminado el desarrollo de la clase. ¿Ha sido mejor este camino? En parte sí. Hemos llegado a un algoritmo casi idéntico, pero diría que el recorrido ha sido más suave, los saltos de código de producción menos pronunciados y todo ha ido mejor hilado.
¿Tenemos criterios para elegir buenos ejemplos?
Desde el punto de vista de QA tradicional existen una serie de métodos para elegir los casos de test. Sin embargo, estos métodos no son necesariamente aplicables en TDD. Recuerda cómo empezábamos este libro: QA y TDD no son lo mismo pese a usar las mismas herramientas y solaparse mucho ambas disciplinas. TDD es una metodología para guiar el desarrollo de software y los tests más adecuados para hacerlo pueden ser sutilmente diferentes de los que usaríamos para verificar el funcionamiento de un software.
Por ejemplo, la categorización que hemos hecho de los números en primos y no primos puede ser más que suficiente en QA, pero en TDD los casos de números no primos podrían subdividirse:
- Potencias de un factor primo, como el 4, el 8 o el 9, que implican un único primo multiplicado varias veces por sí mismo.
- Producto de diferentes primos, como el 6, el 10, que implican varios números primos.
- Productos de n factores primos, con n mayor que dos.
Cada una de estas categorías nos fuerza a implementar distintas partes del algoritmo, lo que puede plantearnos problemas más o menos fáciles de resolver. Incluso, una mala elección podría llevarnos a un callejón sin salida.
Sin embargo, nada nos impide volver atrás si nos quedamos estancados. Cuando tengamos una duda razonable de si tomar un curso u otro en TDD, lo mejor es tomar nota de cuál es el estado del desarrollo y ese punto, marcándolo como un punto de retorno en caso de que nos metamos en algún cenagal de código. Marcha atrás y pensar de nuevo. Haberse equivocado es también información.
Qué hemos aprendido con esta kata
- Con esta kata hemos aprendido cómo a medida que añadimos tests y estos son más específicos, el algoritmo se hace más general
- También hemos visto que obtenemos mejores resultados priorizando las transformaciones (cambios en el código de producción) más sencillas
11 La elección del primer test
En TDD la elección del primer test es un problema interesante. En algunos trabajos y tutoriales sobre TDD se suele hablar del “caso más sencillo” y ahí se queda la recomendación. Pero en realidad deberíamos acostumbrarnos a buscar el test más pequeño que pueda fallar, que suele ser una cosa muy distinta.
Con todo, no parece una definición muy práctica, así que posiblemente merece una explicación más detenida. ¿Hay una forma más o menos objetiva de decidir cuál es el test mínimo que pueda fallar?
A la búsqueda del primer test más sencillo que pueda fallar
Supongamos la kata Roman Numerals. Consiste en crear un convertidor entre números decimales y romanos. Decidimos que la clase va a ser RomanNumeralsConverter y la función se llama toRoman, de modo que se utilizaría más o menos así:
$roman = $romanNumeralsConverter->toRoman(54)
Según el enfoque del “caso más sencillo” podríamos hacer un test más o menos como este:
public function testShouldConvertOne(): void
{
$converter = new RomanNumeralsConverter();
$this->assertEquals("I", $converter->toRoman(1));
}
Parece correcto, ¿verdad? Sin embargo, este no es el test más sencillo que pueda fallar. En realidad hay como mínimo dos aún más sencillos que pueden fallar y ambos nos forzarán a crear código de producción.
– Pensemos un momento sobre el test que acabamos de escribir: ¿qué ocurrirá si lo ejecutamos?
– Fallará.
– Pero, ¿por qué fallará?
– Obvio: porque ni siquiera tenemos la clase definida. Al intentar ejecutar el test, no encuentra la clase.
– ¿Podemos decir que el test falla por la razón que esperamos que falle?
– Humm. ¿Qué quieres decir?
– Quiero decir que el test establece que esperamos que pueda convertir el decimal 1 en el romano I. Debería fallar porque no hace la conversión, no porque no encuentre la clase. En realidad el test puede fallar por, como mínimo, tres causas: que la clase no exista, que la clase no tenga el método toRoman y que no devuelva el resultado “I”. Y solo debería fallar por una.
– ¿Me estás diciendo que el primer test debería ser simplemente instanciar la clase?
– Sí.
– ¿Y qué sentido tiene?
– Que el test, al fallar, solo puede fallar por la razón que esperamos que falle.
– Tengo que pensar en eso un momento.
– Sin problema. Te espero en el párrafo siguiente.
Esta es la cuestión. Para ser el caso más sencillo, este primer test puede fallar por tres motivos diferentes que consideramos como que el test no pasa (recuerda, la segunda ley: no compilar es fallar), por tanto, deberíamos reducirlo para que solo falle por una causa.
Como nota al margen: es cierto que podría fallar por otras muchas causas, como equivocarnos de nombre al escribir, poner la clase en el namespace incorrecto, etc. Asumimos que esos errores son involuntarios. Además, al ejecutar el test nos dirá el error. De ahí la importancia de lanzar los tests, ver cómo fallan y asegurarnos de que fallan como es debido.
Vayamos más despacio, entonces.
El primer test solo debería pedir que exista la clase y se pueda instanciar.
public function testShouldInstantiate(): void
{
$this->expectNotToPerformAssertions();
new RomanNumeralsConverter();
}
En PHPUnit un test sin aserciones falla o al menos se considera risky. Para hacer que pase claramente especificamos que no vamos a realizar aserciones. En otros lenguajes esto es innecesario.
Para pasar el test tengo que crear la clase. Una vez creada veré que el test pasa y entonces podré afrontar el siguiente paso.
El segundo test debería obligarme a definir el método deseado en la clase, aunque todavía no sepamos qué hacer con él o qué parámetros necesitará.
public function testShouldBeAbleToConvertToRoman(): void
{
$this->expectNotToPerformAssertions();
$converter = new RomanNumeralsConverter();
$converter->toRoman();
}
De nuevo, este test es un poco especial en PHP. Por ejemplo, en PHP y otros lenguajes podemos ignorar el retorno de un método si no está tipado. Otros lenguajes nos exigirán tipar el método de manera explícita, cosa que en este paso podría hacerse con void para que no devuelva nada. Otra estrategia sería devolver un valor vacío del tipo adecuado (en este caso string). Hay lenguajes, por su parte, que requieren que se use el resultado del método si es que se devuelve, pero también permiten ignorarlo.
Un asunto interesante es que una vez que hemos hecho pasar este segundo test, el primero es redundante: el caso está cubierto por este segundo test y si un cambio en el código lo hace fallar, el segundo test fallará también. En la fase de refactor puedes borrarlo.
Y es ahora cuando el “caso más sencillo” tiene sentido porque este test, tras los anteriores fallará por la razón adecuada:
public function testShouldConvertOne(): void
{
$converter = new RomanNumeralsConverter();
$this->assertEquals("I", $converter->toRoman(1));
}
Este ya es un test que fallaría por la razón esperada: la clase no tiene nada definido que realice la conversión.
De nuevo, una vez hagas pasar este test y estés en fase de refactor, el anterior puedes borrarlo. Ha cumplido su función de forzarnos a añadir un cambio en el código. Además, en caso de que ese segundo test falle por un cambio en el código, nuestro test actual también fallará. Por tanto, puedes borrarlo también.
Supongo que ahora te haces dos preguntas:
- Por qué hacer tres tests para quedarme con el que había pensado al principio
- Por qué puedo borrar esos tests
Vayamos por partes, entonces.
Por qué empezar con pasos tan pequeños
Un test solo debería tener una razón para fallar. Imagínalo como una aplicación del Single Responsibility Principle. Si un test tiene más de una razón para fallar lo más posible es que estemos queriendo hacer que un test provoque muchos cambios a la vez en el código.
Es cierto que en testing existe una técnica llamada triangulación en la que justamente se verifican varios posibles aspectos que deben ocurrir juntos para considerar que el test pasa o falla. Pero, como hemos dicho al principio del libro TDD no es QA, por lo que no son aplicables las mismas técnicas.
En TDD lo que queremos es que los tests nos digan cuál es el cambio que tenemos que producir en el software y este cambio debería ser lo más pequeño posible y lo menos ambiguo posible.
Cuando no tenemos nada de código de producción escrito, lo más pequeño que podemos hacer es crear un archivo en el que se defina la función o clase que estamos desarrollando. Es el primer paso. Y aun así, hay posibilidades de que no lo hagamos correctamente:
- nos equivocamos en el nombre del archivo
- nos equivocamos en su ubicación en el proyecto
- nos equivocamos al teclear el nombre de la clase o función
- nos equivocamos al situarla en un name space
- …
Tenemos que evitar todos estos problemas solo para conseguir instanciar una clase o poder usar una función, pero ese test mínimo fallará si pasa cualquiera de esas cosas. Al corregir todas las que puedan suceder haremos que el test pase.
Sin embargo, si el test puede fallar por más razones, se multiplicarán las potenciales fuentes de errores porque hay que hacer más cosas para hacerlo pasar. Además, algunas de ellas pueden depender y entremezclarse entre sí. En general, el cambio necesario en el código de producción será demasiado grande con el test en rojo y, por tanto, hacerlo pasar a verde será más costoso y menos obvio.
Por qué borrar estos primeros tests
En TDD muchos tests son redundantes. Desde el punto de vista de QA en TDD se testea demasiado. En primer lugar, porque muchas veces se utilizan varios ejemplos de la misma clase, precisamente para encontrar la regla general que caracteriza a esa clase. Por otro lado, hay tests que hacemos en TDD que están incluidos en otros.
Es el caso de estos primeros tests que hemos mostrado hace un momento.
El test que nos fuerza a definir la unidad de software por primera vez está incluido en cualquier otro test que podamos imaginar por la simple razón de que para que se puedan ejecutar esos otros tests necesitamos la clase. Dicho de otro modo, si falla el primer test, fallarán todos los demás.
En esta situación el test es redundante y lo podemos borrar.
No siempre es fácil identificar tests redundantes. En algunas etapas de TDD usamos ejemplos de la misma clase para mover el desarrollo, con lo cual puede llegar un punto en que algunos de esos tests sean redundantes y podamos borrarlos por innecesarios.
Por otro lado, otra posibilidad es refactorizar los tests con data providers o técnicas similares con las que abaratar la creación de nuevos ejemplos.
La felicidad de los paths
Happy path testing
Denominamos happy path al flujo de un programa cuando no se producen problemas y puede ejecutar el algoritmo completo. El happy path ocurre cuando los datos de entrada son válidos y no se generan errores en el proceso porque todos los datos manejados están en sus rangos de valores aceptables y no se producen otros fallos que puedan afectar a la unidad de software que estamos desarrollando.
El happy path testing en TDD consiste en escoger ejemplos que deberían dar como resultado valores predecibles, sobre los que podemos testear. Por ejemplo, en la kata Roman Numerals, un ejemplo de test de happy path sería:
public function testShouldConvertFour(): void
{
$converter = new RomanNumeralsConverter();
$this->assertEquals("IV", $converter->toRoman(4));
}
Con mucha frecuencia en las katas trabajamos con tests de happy path. Esto es así porque nos interesa centrarnos en el desarrollo del algoritmo y que el ejercicio no dure demasiado tiempo.
Sad path testing
Por el contrario, los sad paths son aquellos flujos del programa que terminan mal. Cuando decimos que terminan mal queremos decir que se produce un error y no se puede terminar de ejecutar el algoritmo.
Sin embargo, los errores y la forma en la que el código de producción se enfrenta a ellos, forman parte del comportamiento del software y en el trabajo real merecen ser considerados al utilizar la metodología TDD.
En ese sentido, el sad path testing sería justamente la elección de casos de tests que describen situaciones en las que el código de producción tiene que manejar datos de entrada incorrectos o respuestas de sus colaboradores que debemos tratar también. Un ejemplo de esto sería algo así:
public function testShouldFailWithInvalidInput(): void
{
$converter = new RomanNumeralsConverter();
$this->expectException(InvalidInput::class);
$converter->toRoman(-12.34);
}
Esto es: nuestro convertidor de números romanos no puede manejar números negativos ni números con decimales y, por tanto, en un programa real tendríamos que gestionar esta situación. En el ejemplo, la consecuencia es lanzar una excepción. Pero podría ser cualquier otra forma de reacción que nos convenga para los propósitos de la aplicación.
public function testShouldFailWithInvalidInput(): void
{
$converter = new RomanNumeralsConverter();
$this->assertEquals('Non possum hic numerus converto', $converter->toRoman(-12.34));
}
12 NIF
Comienza por los sad paths y aplaza las soluciones
Esta kata consiste originalmente en crear un Value Object para representar el NIF, o número de identificación fiscal español. Su forma habitual es una cadena de ocho caracteres numéricos y una letra de control, que nos ayuda a asegurar su validez.
Al tratarse de un Value Object queremos poder instanciarlo a partir de un string y garantizar que sea válido para poder utilizarlo sin problemas en cualquier lugar del código de una aplicación.
Una de las dificultades para desarrollar este tipo de objetos en TDD es que a veces no necesitan implementar comportamientos significativos y es más importante asegurarse de que se crean consistentes.
El algoritmo para validarlo es relativamente sencillo, como veremos, pero el interés está sobre todo en cómo librarnos de todas las cadenas de caracteres que no pueden formar un NIF válido.
Historia
Esta kata es original y surgió por casualidad al preparar un pequeño taller de introducción a TDD y live coding acerca de los beneficios de utilizar la metodología en el trabajo cotidiano.
Al profundizar en este ejemplo se fueron poniendo de manifiesto dos cuestiones que resultan muy interesantes:
- Empezar por tests que descarten los casos inválidos nos permite evitar atacar el desarrollo del algoritmo nada más empezar, quitándolos de en medio y reduciendo el espacio del problema. La consecuencia es que acabamos desarrollando objetos más resilientes, con algoritmos más limpios y contribuye a prevenir la aparición de bugs en el código de producción.
- Se pone de manifiesto el mecanismo de aplazar la solución de cada problema hasta el siguiente test. Es decir: para hacer que cada nuevo test pase, introducimos una implementación inflexible que nos permita cumplir ese test, pero para que los anteriores sigan pasando nos vemos obligados a refactorizar el código que ya teníamos antes.
Enunciado
Crear una clase Nif, que será un Value Object para representar el Número de Identificación Fiscal de España. Este número es una cadena de ocho caracteres numéricos, con una letra final que actúa como carácter de control.
Esta letra de control se obtiene calculando el resto de dividir la parte numérica del NIF entre 23 (mod 23). El resultado nos indica la fila en la que consultar la letra de control de la siguiente tabla:
| Resto | Letra |
|---|---|
| 0 | T |
| 1 | R |
| 2 | W |
| 3 | A |
| 4 | G |
| 5 | M |
| 6 | Y |
| 7 | F |
| 8 | P |
| 9 | D |
| 10 | X |
| 11 | B |
| 12 | N |
| 13 | J |
| 14 | Z |
| 15 | S |
| 16 | Q |
| 17 | V |
| 18 | H |
| 19 | L |
| 20 | C |
| 21 | K |
| 22 | E |
Existe un caso especial de NIF que es el NIE o Número de Identificación para Extranjeros. En este caso, el primer carácter será una letra X, Y o Z. Para el cálculo del mod 23 se reemplazan por los valores 0, 1 y 2, respectivamente.
Orientaciones para resolverla
Esta kata nos puede aportar varios aprendizajes tanto de TDD como de tipos de datos y validación.
En las katas es habitual obviar temas como la validación de datos para simplificar el ejercicio y centrarnos en el desarrollo del algoritmo. En un desarrollo real no podemos hacer esto, sino justamente poner mucho énfasis en validar los datos a distintos niveles, tanto por razones de seguridad como para evitar errores en los cálculos.
Así que hemos incluido esta kata precisamente para practicar cómo desarrollar mediante TDD algoritmos que primero gestionan todos los valores que no pueden manejar tanto desde el punto de vista estructural como de dominio.
En concreto este ejemplo se baja en el hecho de que el comportamiento efectivo del constructor que vamos a crear es asignar el valor que le pasamos. Todo lo demás que hace es comprobar que ese valor es adecuado para eso, por lo que actúa como barrera de valores indeseados.
Al tratarse de un Value Object intentaremos crear una clase a la que se le pasa la cadena candidata en el constructor. Si la cadena resulta ser inválida para un NIF el constructor lanzará una excepción, impidiendo que se puedan instanciar objetos con valores inadecuados. Fundamentalmente, nuestros primeros tests esperarán excepciones o errores.
De todas las infinitas cadenas que podría recibir este constructor solo unas pocas serán NIF válidos, por lo que nuestro primer objetivo podría ser eliminar las más obvias: las que nunca podrían serlo porque tienen el número de caracteres inadecuado.
En una segunda fase, buscaremos controlar aquellas que no podrían nunca ser un NIF por su estructura, básicamente porque no siguen el esquema de ocho caracteres numéricos y una letra final, teniendo en cuanta la excepción de los NIE, que sí podrían tener una letra al principio.
Con esto tendríamos todo preparado para implementar el algoritmo de validación, ya que slo tendríamos que manejar strings que estructuralmente podrían ser NIF.
Una cosa que los pasos anteriores nos garantizan es que los tests no empezarán a fallar cuando introduzcamos el algoritmo, debido a que sus ejemplos nunca podrían ser válidos. Si comenzásemos usando string que estructuralmente podrían ser NIF, aunque los hayamos escrito al azar, podríamos encontrarnos con alguno que casualmente fuese válido y al implementar la parte correspondiente del algoritmo ese test fallaría por la razón equivocada.
Enlaces de interés sobre la kata
- La kata del NIF para aprender TDD1
13 Resolviendo la Kata NIF
En este kata vamos a orientarnos en una estrategia que aborde primero los sad paths, es decir, vamos a tratar primero los casos que provocarían un error. De este modo, primero desarrollaremos la validación de la estructura del input, para pasar después al del algoritmo.
Es habitual que las katas obvien temas como las validaciones, pero en este caso hemos preferido hacer un ejemplo que es más realista, en el sentido de que es una situación con la que lidiamos habitualmente. En el código de un proyecto en producción es fundamental la validación de datos de entrada y no está de más practicar con un ejercicio que pone su foco casi exclusivamente en ello.
Aparte, veremos un par de técnicas interesantes para transformar una interfaz pública sin romper los tests.
Enunciado de la kata
Crear una clase Nif, que será un Value Object para representar el Número de Identificación Fiscal de España. Es una combinación de una cadena de ocho caracteres numéricos, con una letra final que actúa como carácter de control.
Esta letra de control se obtiene calculando el resto de dividir la parte numérica del NIF entre 23 (mod 23). El resultado nos indica la fila en la que consultar la letra de control de la siguiente tabla. En esta tabla he incluido también ejemplos sencillos de NIF válidos para que los puedas usar en los tests.
| Parte numérica | Resto | Letra | Ejemplo NIF válido |
|---|---|---|---|
| 00000023 | 0 | T | 00000023T |
| 00000024 | 1 | R | 00000024R |
| 00000025 | 2 | W | 00000025W |
| 00000026 | 3 | A | 00000026A |
| 00000027 | 4 | G | 00000027G |
| 00000028 | 5 | M | 00000028M |
| 00000029 | 6 | Y | 00000029Y |
| 00000030 | 7 | F | 00000030F |
| 00000031 | 8 | P | 00000031P |
| 00000032 | 9 | D | 00000032D |
| 00000033 | 10 | X | 00000033X |
| 00000034 | 11 | B | 00000034B |
| 00000035 | 12 | N | 00000035N |
| 00000036 | 13 | J | 00000036J |
| 00000037 | 14 | Z | 00000037Z |
| 00000038 | 15 | S | 00000038S |
| 00000039 | 16 | Q | 00000039Q |
| 00000040 | 17 | V | 00000040V |
| 00000041 | 18 | H | 00000041H |
| 00000042 | 19 | L | 00000042L |
| 00000043 | 20 | C | 00000043C |
| 00000044 | 21 | K | 00000044K |
| 00000045 | 22 | E | 00000045E |
Puedes crear NIF inválidos simplemente escogiendo una parte numérica y la letra que no le corresponde.
| Ejemplo inválido |
|---|
| 00000000S |
| 00000001M |
| 00000002H |
| 00000003Q |
| 00000004E |
Hay una excepción: los NIF para extranjeras (o NIE) pueden empezar por las letras X, Y o Z, que a los efectos de los cálculos se reemplazan por los números 0, 1 y 2, respectivamente. En ese caso X0000000T equivale a 00000000T.
Para evitar confusiones se han excluido las letras U, I, O y Ñ.
Una cadena que empieza por una letra distinta de X, Y, Z, o que contenga caracteres alfabéticos en las posiciones centrales también es inválida.
Lenguaje y enfoque
Esta kata la vamos a resolver en Go, por lo que vamos a matizar un poco su resultado. En este ejemplo vamos a crear un tipo de dato Nif, que será básicamente un string, y una función factoría NewNif que nos permitirá construir NIF validados a partir de un string que le pasamos.
Por otro lado, el testing en Go es también un poco particular. Aunque el lenguaje incorpora de forma estándar soporte para realizar tests, no incluye utilidades habituales como asserts.
Disclaimer
Para resolver esta kata me voy a aprovechar de la forma en que Go gestiona los errores. Estos se pueden devolver como una de las respuestas de una función, lo que te obliga a gestionarlos siempre de manera explícita.
Basar tests en mensajes de error no es una buena práctica, porque pueden cambiar con facilidad haciendo fallar los tests aunque no haya realmente una alteración de la funcionalidad. Sin embargo, en esta kata vamos a usar los mensajes de error como una especie de comodín temporal en el que apoyarnos haciendo que cambien de más específicos a más generales. Al acabar el ejercicio manejaremos únicamente dos errores posibles.
Creando la función constructora
En esta kata nos interesa empezar centrándonos en los sad paths, los casos en los que no vamos a poder usar el argumento pasado a la función constructora. De todas las innumerables combinaciones de string que la función podría recibir vamos primero a dar una respuesta a las que sabemos con seguridad que no nos van a servir porque no se ajustan a los requisitos. Esta respuesta será un error.
Empezaremos rechazando aquellas cadenas que sean demasiado largas, las que tienen más de nueve caracteres. Esto lo podemos describir con este test:
En el archivo nif/nif_test.go
package nif
import "testing"
func TestShouldFailWhenStringIsTooLong(t *testing.T) {
NewNif()
}
De momento vamos a ignorar las respuestas de la función simplemente para forzarnos a implementar el mínimo de código.
Como es de suponer el test fallará porque no compila. Así que implementamos el código mínimo necesario, que puede ser tan pequeño como este:
Archivo nif/nif.go
package nif
func NewNif() {
}
Con esto ya logramos una base sobre la que construir.
Ahora podemos avanzar un paso más. La función debería aceptar un parámetro:
package nif
import "testing"
func TestShouldFailWhenStringIsTooLong(t *testing.T) {
NewNif("01234567891011")
}
Volvemos a hacer pasar el test con:
package nif
func NewNif(candidate string) {
}
Y, finalmente, devolver:
- el NIF cuando el que hemos pasado es válido.
- un error en caso de que no se pueda.
En Go una función puede devolver varios valores y, por convención, se devuelven también los errores como último valor devuelto.
Esto proporciona una flexibilidad que no es habitual encontrar en otros lenguajes y nos deja jugar con algunas ideas que son como mínimo curiosas. Por ejemplo, nosotras vamos a ignorar de momento la respuesta de la función y centrarnos solo en los errores. Nuestro próximo test va a pedir que la función devuelva solo el error sin hacer nada con él. El if es, de momento, para que el compilador no proteste.
package nif
import "testing"
func TestShouldFailWhenStringIsTooLong(t *testing.T) {
err := NewNif("01234567891011")
if err != nil {}
}
Este test nos indica que debemos devolver algo, así que por ahora indicamos que vamos a devolver un error, que puede ser nil.
package nif
func NewNif(candidate string) error {
return nil
}
Avancemos un paso más esperando que se produzca un error determinado cuando se cumple la circunstancia definida por el test, que la cadena es demasiado larga, y con lo que tendremos ya un primer test en condiciones:
package nif
import "testing"
func TestShouldFailWhenStringIsTooLong(t *testing.T) {
err := NewNif("01234567891011")
if err.Error() != "too long" {
t.Errorf("Expected too long, got %s", err.Error())
}
}
De nuevo fallará el test y para hacerlo pasar devolvemos incondicionalmente el error:
package nif
import "errors"
func NewNif(candidate string) error {
return errors.New("too long")
}
Y con esto ya hemos hecho que nuestro primer test esté completo y pase. Podríamos ser un poco más estrictas en el manejo de la respuesta para contemplar el caso de que err sea nil, pero de momento es algo que no nos tiene que afectar.
En este punto me gustaría llamar tu atención al hecho de que no estamos resolviendo nada todavía: el error se devuelve de manera incondicional, por lo que estamos retrasando esta validación para más tarde.
Implementar la primera validación
Nuestro segundo test tiene como objetivo forzar la implementación de la validación que acabamos de posponer. Puede sonar un poco extraño, pero nos muestra que uno de los grandes beneficios de TDD es el hecho de poder posponer decisiones. Al hacerlo, tendremos un poco más de información, lo que siempre es una ventaja.
El test es muy similar al anterior:
package nif
import "testing"
func TestShouldFailWhenStringIsTooLong(t *testing.T) {
err := NewNif("01234567891011")
if err.Error() != "too long" {
t.Errorf("Expected too long, got %s", err.Error())
}
}
func TestShouldFailWhenStringIsTooShort(t *testing.T) {
err := NewNif("0123456")
if err.Error() != "too short" {
t.Errorf("Expected too short, got %s", err.Error())
}
}
Este test ya nos obliga a actuar de manera diferente en cada caso, así que vamos a implementar la validación que limita los string demasiado largos:
package nif
import "errors"
func NewNif(candidate string) error {
if len(candidate) > 9 {
return errors.New("too long")
}
return errors.New("too short")
}
Vuelvo a señalar que en este momento lo que dice el test no lo estamos implementando ahora. Lo haremos en el siguiente ciclo, pero el test se cumple al devolver el error esperado de forma incondicional.
No hay mucho más que podamos hacer en el código de producción, pero al fijarnos en los tests podemos ver que sería posible unificar un poco su estructura. Al fin y al cabo vamos a hacer una serie de ellos en los que pasamos un valor y esperamos un error determinado como respuesta.
Un test para dominarlos a todos
En Go existe una estructura de test similar a la que en otros lenguajes nos proporciona el uso de Data Providers: Table Test.
package nif
import "testing"
func TestShouldFailIfCandidateIsInvalid(t *testing.T) {
tests := []struct {
name string
example string
expected string
}{
{"should fail if too long", "01234567891011", "too long"},
{"should fail if too short", "01234", "too short"},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
err := NewNif(test.example)
if err.Error() != test.expected {
t.Errorf("Expected %s, got %s", test.expected, err.Error())
}
})
}
}
Con esto conseguimos que ahora sea muy fácil y rápido añadir tests, sobre todo si son de la misma familia, como en este caso en el que pasamos cadenas candidatas inválidas y chequeamos por el error. Además, si hacemos cambios en la interfaz de la constructora solo tenemos un lugar en donde aplicarlos.
Con esto, tendríamos ya todo preparado para seguir desarrollando.
Completar la validación de la longitud y empezar a examinar la estructura
Con los dos tests anteriores verificamos si la cadena que vamos a examinar cumple la especificación de tener exactamente nueve caracteres, aunque de momento eso no está implementado. Lo haremos ahora.
Sin embargo, puede que te preguntes por qué no testear simplemente que la función rechaza los strings que no la cumplan, algo que podríamos hacer en un único test.
La razón es que en realidad hay dos posibles formas de que no se cumpla la especificación: el string tiene más de nueve caracteres o el string tiene menos. Si hacemos un solo test elegiremos uno de los dos casos, con lo cual no estamos garantizando que se cumpla el otro.
En este ejemplo concreto en que hay un único valor que nos interesa podríamos plantear la disyuntiva entre strings con longitud nueve y strings con longitud distinta de nueve. Sin embargo, es frecuente que tengamos que trabajar con intervalos de valores que, además, pueden estar abiertos o cerrados. En esa situación la estrategia de dos, o incluso más tests, es muchísimo más segura.
En cualquier caso, en el punto en el que estamos, para mover el desarrollo necesitamos añadir otro requisito en forma de test. Los dos tests existentes nos definen la longitud válida del string. El siguiente test pregunta por su estructura.
Y con el refactor que acabamos de hacer añadir un test es tremendamente sencillo.
Empezaremos por el principio. Los NIF válidos comienzan con un número, excepto un subconjunto de ellos que lo hace por alguna de las letras X, Y y Z. Una forma de definir el test es de la siguiente forma:
package nif
import "testing"
func TestShouldFailIfCandidateIsInvalid(t *testing.T) {
tests := []struct {
name string
example string
expected string
}{
{
"should fail if too long",
"01234567891011",
"too long",
},
{
"should fail if too short",
"01234",
"too short",
},
{
"should fail if starts with a letter other than X, Y, Z",
"A12345678",
"bad start format",
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
err := NewNif(test.example)
if err.Error() != test.expected {
t.Errorf("Expected %s, got %s", test.expected, err.Error())
}
})
}
}
Para hacer pasar el test, resolvemos primero el problema pendiente del anterior:
package nif
import "errors"
func NewNif(candidate string) error {
if len(candidate) > 9 {
return errors.New("too long")
}
if len(candidate) < 9 {
return errors.New("too short")
}
return errors.New("bad start format")
}
Aquí tenemos una oportunidad de refactor bastante clara que consistiría en unir las condicionales que evalúan la longitud del string. Sin embargo, esa va a hacer que el test falle, ya que al menos tendríamos que cambiar un mensaje de error.
La vía no muy limpia de cambiar a la vez test y código de producción
Una posibilidad es “saltarnos” temporalmente la condición de que el refactor sea con los tests en verde y hacer cambios a la vez en prod y test. Veamos qué pasa.
Lo primero sería cambiar el test para esperar un mensaje de error distinto, que será más genérico e igual para todos los casos que queremos consolidar en este paso:
package nif
import "testing"
func TestShouldFailIfCandidateIsInvalid(t *testing.T) {
tests := []struct {
name string
example string
expected string
}{
{
"should fail if too long",
"01234567891011",
"bad format",
},
{
"should fail if too short",
"01234",
"bad format",
},
{
"should fail if starts with a letter other than X, Y, Z",
"A12345678",
"bad start format",
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
err := NewNif(test.example)
if err.Error() != test.expected {
t.Errorf("Expected %s, got %s", test.expected, err.Error())
}
})
}
}
Esto hará fallar el test. Cosa que se puede arreglar cambiando el código de producción del mismo modo:
package nif
import "errors"
func NewNif(candidate string) error {
if len(candidate) > 9 {
return errors.New("bad format")
}
if len(candidate) < 9 {
return errors.New("bad format")
}
return errors.New("bad start format")
}
El test vuelve a pasar y estamos listas para el refactor. Pero no vamos a hacer eso.
La vía segura
Otra opción es hacer un refactor temporal en el test para hacerlo más tolerante. Simplemente, hacemos que sea posible devolver un error más genérico aparte del error específico.
package nif
import "testing"
func TestShouldFailIfCandidateIsInvalid(t *testing.T) {
tests := []struct {
name string
example string
expected string
}{
{
"should fail if too long",
"01234567891011",
"too long",
},
{
"should fail if too short",
"01234",
"too short",
},
{
"should fail if starts with a letter other than X, Y, Z",
"A12345678",
"bad start format",
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
err := NewNif(test.example)
if err.Error() != test.expected && err.Error() != "bad format" {
t.Errorf("Expected %s, got %s", test.expected, err.Error())
}
})
}
}
Este cambio nos permite ahora hacer el cambio en producción sin romper nada:
package nif
import "errors"
func NewNif(candidate string) error {
if len(candidate) > 9 {
return errors.New("bad format")
}
if len(candidate) < 9 {
return errors.New("bad format")
}
return errors.New("bad end format")
}
El test sigue pasando y ahora sí podemos hacer el refactor.
Unificar la validación por longitud del string
Unificar las condicionales es fácil en este momento. Este es el primer paso, que incluyo aquí para tener un modelo de cómo hacer esto en caso de que fuese un intervalo de longitudes válidas.
package nif
import "errors"
func NewNif(candidate string) error {
if len(candidate) > 9 || len(candidate) < 9 {
return errors.New("bad format")
}
return errors.New("bad start format")
}
Pero se puede hacer mejor:
package nif
import "errors"
func NewNif(candidate string) error {
if len(candidate) != 9 {
return errors.New("bad format")
}
return errors.New("bad start format")
}
Y un poco más expresivo:
package nif
import "errors"
func NewNif(candidate string) error {
const maxlength = 9
if len(candidate) != maxlength {
return errors.New("bad format")
}
return errors.New("bad start format")
}
Finalmente, un nuevo refactor del test para contemplar estos cambios. Retiramos nuestro cambio temporal aunque es posible que tengamos que volver a utilizarlo en el futuro.
package nif
import "testing"
func TestShouldFailIfCandidateIsInvalid(t *testing.T) {
tests := []struct {
name string
example string
expected string
}{
{
"should fail if too long",
"01234567891011",
"bad format",
},
{
"should fail if too short",
"01234",
"bad format",
},
{
"should fail if starts with a letter other than X, Y, Z",
"A12345678",
"bad start format",
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
err := NewNif(test.example)
if err.Error() != test.expected {
t.Errorf("Expected %s, got %s", test.expected, err.Error())
}
})
}
}
Fíjate que hemos podido hacer todos estos cambios sin que fallaran los tests.
Avanzando en la estructura
El código está bastante compacto, así que vamos a añadir un nuevo test que nos permita avanzar con la validez de la estructura. El fragmento central del NIF está compuesto solo por números, exactamente siete:
package nif
import "testing"
func TestShouldFailIfCandidateIsInvalid(t *testing.T) {
tests := []struct {
name string
example string
expected string
}{
{
"should fail if too long",
"01234567891011",
"bad format",
},
{
"should fail if too short",
"01234",
"bad format",
},
{
"should fail if starts with a letter other than X, Y, Z",
"A12345678",
"bad start format",
},
{
"should fail if doesn't have 7 digit in the middle",
"0123X567R",
"bad middle format",
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
err := NewNif(test.example)
if err.Error() != test.expected {
t.Errorf("Expected %s, got %s", test.expected, err.Error())
}
})
}
}
Lo lanzamos para asegurarnos de que falla por la razón adecuada. Para hacer pasar el test tenemos que resolver primero el test anterior, por lo que añadiremos código para verificar que el primer símbolo es un número o una letra en el conjunto X, Y y Z. Lo haremos con una expresión regular:
package nif
import (
"errors"
"regexp"
)
func NewNif(candidate string) error {
const maxlength = 9
if len(candidate) != maxlength {
return errors.New("bad format")
}
invalid := regexp.MustCompile(`(?i)^[^0-9XYZ].*`)
if invalid.MatchString(candidate) {
return errors.New("bad start format")
}
return errors.New("bad middle format")
}
Con este código hacemos pasar el test, pero vamos a hacer un refactor.
Invertir la condicional
Tiene sentido que en vez de hacer match contra una expresión regular que excluya los string no válidos, hagamos match contra una expresión que los detecte. Con eso tendremos que invertir la condicional. Lo cierto es que el cambio es bastante pequeño:
package nif
import (
"errors"
"regexp"
)
func NewNif(candidate string) error {
const maxlength = 9
if len(candidate) != maxlength {
return errors.New("bad format")
}
valid := regexp.MustCompile(`(?i)^[0-9XYZ].*`)
if !valid.MatchString(candidate) {
return errors.New("bad start format")
}
return errors.New("bad middle format")
}
El final de la estructura
Nos estamos acercando al final de la validación estructural del NIF, necesitamos un test que nos diga cuáles rechazar en función de su último símbolo, lo que nos llevará a resolver el problema que quedaba pendiente del test anterior:
package nif
import "testing"
func TestShouldFailIfCandidateIsInvalid(t *testing.T) {
tests := []struct {
name string
example string
expected string
}{
{
"should fail if too long",
"01234567891011",
"bad format",
},
{
"should fail if too short",
"01234",
"bad format",
},
{
"should fail if starts with a letter other than X, Y, Z",
"A12345678",
"bad start format",
},
{
"should fail if doesn't have 7 digit in the middle",
"0123X567R",
"bad middle format",
},
{
"should fail if doesn't end with a valid control letter",
"01234567U",
"invalid end format",
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
err := NewNif(test.example)
if err.Error() != test.expected {
t.Errorf("Expected %s, got %s", test.expected, err.Error())
}
})
}
}
De las cuatro letras no válidas tomamos la U como ejemplo, pero podrían ser: la I, la Ñ y la O.
Sin embargo, para hacer pasar el test, lo que hacemos es asegurarnos que el anterior se va a cumplir. Lo más fácil es implementar eso de forma separada:
package nif
import (
"errors"
"regexp"
)
func NewNif(candidate string) error {
const maxlength = 9
if len(candidate) != maxlength {
return errors.New("bad format")
}
valid := regexp.MustCompile(`(?i)^[0-9XYZ].*`)
if !valid.MatchString(candidate) {
return errors.New("bad start format")
}
valid = regexp.MustCompile(`(?i)^.\d{7}.*`)
if !valid.MatchString(candidate) {
return errors.New("bad middle format")
}
return errors.New("invalid end format")
}
Compactando el algoritmo
Con esto pasa el test y nos encontramos con una situación familiar que ya hemos resuelto antes: tenemos que convertir los errores en más genéricos con la ayuda temporal de un control extra en el test:
package nif
import "testing"
func TestShouldFailIfCandidateIsInvalid(t *testing.T) {
tests := []struct {
name string
example string
expected string
}{
{
"should fail if too long",
"01234567891011",
"bad format",
},
{
"should fail if too short",
"01234",
"bad format",
},
{
"should fail if starts with a letter other than X, Y, Z",
"A12345678",
"bad start format",
},
{
"should fail if doesn't have 7 digit in the middle",
"0123X567R",
"bad middle format",
},
{
"should fail if doesn't end with a valid control letter",
"01234567U",
"invalid end format",
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
err := NewNif(test.example)
if err.Error() != test.expected && err.Error() != "bad format" {
t.Errorf("Expected %s, got %s", test.expected, err.Error())
}
})
}
}
Hacemos el cambio en los mensajes de error en el código de producción:
package nif
import (
"errors"
"regexp"
)
func NewNif(candidate string) error {
const maxlength = 9
if len(candidate) != maxlength {
return errors.New("bad format")
}
valid := regexp.MustCompile(`(?i)^[0-9XYZ].*`)
if !valid.MatchString(candidate) {
return errors.New("bad format")
}
valid = regexp.MustCompile(`(?i)^.\d{7}.*`)
if !valid.MatchString(candidate) {
return errors.New("bad format")
}
return errors.New("invalid end format")
}
Ahora unificamos la expresión regular y las condicionales:
package nif
import (
"errors"
"regexp"
)
func NewNif(candidate string) error {
const maxlength = 9
if len(candidate) != maxlength {
return errors.New("bad format")
}
valid := regexp.MustCompile(`(?i)^[0-9XYZ]\d{7}.*`)
if !valid.MatchString(candidate) {
return errors.New("bad format")
}
return errors.New("invalid end format")
}
Todavía podemos hacer un cambio pequeño pero importante. La última parte de la expresión regular .* está para cumplir el requisito de que se haga match de toda la cadena, pero realmente no necesitamos el cuantificador, ya que nos basta un carácter:
package nif
import (
"errors"
"regexp"
)
func NewNif(candidate string) error {
const maxlength = 9
if len(candidate) != maxlength {
return errors.New("bad format")
}
valid := regexp.MustCompile(`(?i)^[0-9XYZ]\d{7}.$`)
if !valid.MatchString(candidate) {
return errors.New("bad format")
}
return errors.New("invalid end format")
}
Y esto nos revela un detalle, la expresión regular hace match únicamente en cadenas de exactamente nueve caracteres, por lo que la validación inicial de la longitud resulta innecesaria:
package nif
import (
"errors"
"regexp"
)
func NewNif(candidate string) error {
valid := regexp.MustCompile(`(?i)^[0-9XYZ]\d{7}.$`)
if !valid.MatchString(candidate) {
return errors.New("bad format")
}
return errors.New("invalid end format")
}
Tanto camino recorrido para desandarlo. Sin embargo, al principio no sabíamos esto y es ahí donde está el valor del proceso.
Por último, cambiamos el test para reflejar los cambios y volver a quitar nuestro apoyo temporal:
package nif
import "testing"
func TestShouldFailIfCandidateIsInvalid(t *testing.T) {
tests := []struct {
name string
example string
expected string
}{
{
"should fail if too long",
"01234567891011",
"bad format",
},
{
"should fail if too short",
"01234",
"bad format",
},
{
"should fail if starts with a letter other than X, Y, Z",
"A12345678",
"bad format",
},
{
"should fail if doesn't have 7 digit in the middle",
"0123X567R",
"bad format",
},
{
"should fail if doesn't end with a valid control letter",
"01234567U",
"invalid end format",
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
err := NewNif(test.example)
if err.Error() != test.expected {
t.Errorf("Expected %s, got %s", test.expected, err.Error())
}
})
}
}
Terminando la validación estructural
Necesitamos un nuevo test para terminar la parte de la validación estructural. Los tests existentes nos garantizarían la corrección de los strings, pero la siguiente validación ya implica el algoritmo para calcular la letra de control.
El test que necesitamos ahora controla que no podemos usar un NIF estructuralmente válido, pero en el que la letra de control sea incorrecta. Al enunciar la kata pusimos algunos ejemplos, como 00000000S. Este es el test:
package nif
import "testing"
func TestShouldFailIfCandidateIsInvalid(t *testing.T) {
tests := []struct {
name string
example string
expected string
}{
{
"should fail if too long",
"01234567891011",
"bad format",
},
{
"should fail if too short",
"01234",
"bad format",
},
{
"should fail if starts with a letter other than X, Y, Z",
"A12345678",
"bad format",
},
{
"should fail if doesn't have 7 digit in the middle",
"0123X567R",
"bad format",
},
{
"should fail if doesn't end with a valid control letter",
"01234567U",
"invalid end format",
},
{
"should fail if doesn't end with the right control letter",
"00000000S",
"bad control letter",
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
err := NewNif(test.example)
if err.Error() != test.expected {
t.Errorf("Expected %s, got %s", test.expected, err.Error())
}
})
}
}
Y he aquí el código que lo hace pasar:
package nif
import (
"errors"
"regexp"
)
func NewNif(candidate string) error {
valid := regexp.MustCompile(`(?i)^[0-9XYZ]\d{7}.$`)
if !valid.MatchString(candidate) {
return errors.New("bad format")
}
valid = regexp.MustCompile(`(?i).*[^UIOÑ0-9]$`)
if !valid.MatchString(candidate) {
return errors.New("invalid end format")
}
return errors.New("bad control letter")
}
Y, cómo no, toca refactorizar.
Compactando la validación
Este refactor es bastante obvio, pero tenemos que volver a proteger el test temporalmente:
package nif
import "testing"
func TestShouldFailIfCandidateIsInvalid(t *testing.T) {
tests := []struct {
name string
example string
expected string
}{
{
"should fail if too long",
"01234567891011",
"bad format",
},
{
"should fail if too short",
"01234",
"bad format",
},
{
"should fail if starts with a letter other than X, Y, Z",
"A12345678",
"bad format",
},
{
"should fail if doesn't have 7 digit in the middle",
"0123X567R",
"bad format",
},
{
"should fail if doesn't end with a valid control letter",
"01234567U",
"invalid end format",
},
{
"should fail if doesn't end with the right control letter",
"00000000S",
"bad control letter",
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
err := NewNif(test.example)
if err.Error() != test.expected && err.Error() != "bad format" {
t.Errorf("Expected %s, got %s", test.expected, err.Error())
}
})
}
}
Hacemos más general el error para poder unificar las expresiones regulares y las condicionales:
package nif
import (
"errors"
"regexp"
)
func NewNif(candidate string) error {
valid := regexp.MustCompile(`(?i)^[0-9XYZ]\d{7}.$`)
if !valid.MatchString(candidate) {
return errors.New("bad format")
}
valid = regexp.MustCompile(`(?i).*[^UIOÑ0-9]$`)
if !valid.MatchString(candidate) {
return errors.New("bad format")
}
return errors.New("bad control letter")
}
Y hacemos ahora la unificación, mientras los tests siguen pasando:
package nif
import (
"errors"
"regexp"
)
func NewNif(candidate string) error {
valid := regexp.MustCompile(`(?i)^[0-9XYZ]\d{7}[^UIOÑ0-9]$`)
if !valid.MatchString(candidate) {
return errors.New("bad format")
}
return errors.New("bad control letter")
}
Con esto terminamos la validación de la estructura y nos quedaría implementar el algoritmo mod23. Pero para eso necesitamos un pequeño cambio de enfoque.
Seamos optimistas
El algoritmo es, de hecho, muy sencillo: obtener un resto (de dividir por 23) y buscar la posición indicada por el resultado en una tabla. Es fácil de implementar en una sola iteración. Sin embargo, vamos a hacerlo más lentamente.
Hasta ahora nuestros tests eran pesimistas porque esperaban ejemplos incorrectos de NIF para poder pasar. Nuestros tests ahora tienen que ser optimistas, es decir, van a esperar que le pasemos ejemplos de NIF válidos.
En este punto introduciremos un cambio. Si recuerdas, de momento solo estamos devolviendo el error y la interfaz final de la función devolverá el string validado como un tipo NIF que vamos a crear para la ocasión.
Es decir, tenemos que cambiar el código para que devuelva algo, y que ese algo sea de un tipo que todavía no existe.
Para hacer este cambio sin romper los tests vamos a hacer una técnica de refactor un tanto rebuscada.
Cambiando la interfaz pública
En primer lugar, extraemos el cuerpo de NewNif a otra función:
package nif
import (
"errors"
"regexp"
)
func NewNif(candidate string) error {
return FullNewNif(candidate)
}
func FullNewNif(candidate string) error {
valid := regexp.MustCompile(`(?i)^[0-9XYZ]\d{7}[^UIOÑ0-9]$`)
if !valid.MatchString(candidate) {
return errors.New("bad format")
}
return errors.New("bad control letter")
}
Los tests siguen pasando. Ahora introducimos una variable:
package nif
import (
"errors"
"regexp"
)
func NewNif(candidate string) error {
err := FullNewNif(candidate)
return err
}
func FullNewNif(candidate string) error {
valid := regexp.MustCompile(`(?i)^[0-9XYZ]\d{7}[^UIOÑ0-9]$`)
if !valid.MatchString(candidate) {
return errors.New("bad format")
}
return errors.New("bad control letter")
}
Con esto podemos hacer que FullNewNif devuelva el string sin afectar al test porque queda encapsulado dentro de NewNif.
package nif
import (
"errors"
"regexp"
)
func NewNif(candidate string) error {
_, err := FullNewNif(candidate)
return err
}
func FullNewNif(candidate string) (string, error) {
valid := regexp.MustCompile(`(?i)^[0-9XYZ]\d{7}[^UIOÑ0-9]$`)
if !valid.MatchString(candidate) {
return "", errors.New("bad format")
}
return candidate, errors.New("bad control letter")
}
Los tests siguen pasando y casi hemos acabado. En el test cambiamos el uso de NewNif por FullNewNif.
package nif
import "testing"
func TestShouldFailIfCandidateIsInvalid(t *testing.T) {
tests := []struct {
name string
example string
expected string
}{
{
"should fail if too long",
"01234567891011",
"bad format",
},
{
"should fail if too short",
"01234",
"bad format",
},
{
"should fail if starts with a letter other than X, Y, Z",
"A12345678",
"bad format",
},
{
"should fail if doesn't have 7 digit in the middle",
"0123X567R",
"bad format",
},
{
"should fail if doesn't end with a valid control letter",
"01234567U",
"invalid end format",
},
{
"should fail if doesn't end with the right control letter",
"00000000S",
"bad control letter",
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
_, err := FullNewNif(test.example)
if err.Error() != test.expected && err.Error() != "bad format" {
t.Errorf("Expected %s, got %s", test.expected, err.Error())
}
})
}
}
Siguen pasando los tests. Ahora la función devuelve los dos parámetros que queríamos y no hemos roto los tests. Podemos eliminar la función NewNif original.
package nif
import (
"errors"
"regexp"
)
func FullNewNif(candidate string) (string, error) {
valid := regexp.MustCompile(`(?i)^[0-9XYZ]\d{7}[^UIOÑ0-9]$`)
if !valid.MatchString(candidate) {
return "", errors.New("bad format")
}
return candidate, errors.New("bad control letter")
}
Y usar las herramientas del IDE para cambiar el nombre de la función FullNewNif a NewNif.
package nif
import (
"errors"
"regexp"
)
func NewNif(candidate string) (string, error) {
valid := regexp.MustCompile(`(?i)^[0-9XYZ]\d{7}[^UIOÑ0-9]$`)
if !valid.MatchString(candidate) {
return "", errors.New("bad format")
}
return candidate, errors.New("bad control letter")
}
Ahora sí
Nuestro objetivo ahora es empujar la implementación del algoritmo mod23. Esta vez los tests esperan que la cadena sea válida. Además, queremos forzar que se devuelva el tipo Nif en lugar de string.
func TestShouldCreateNifTypeWithValidCandidate(t *testing.T) {
tests := []struct {
name string
example string
}{
{"should accept mod23 being 0", "00000023T"},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
nif, err := NewNif(test.example)
if nif != Nif(test.example) {
t.Errorf("Expected Nif(%s), got %s", test.example, nif)
}
if err != nil {
t.Errorf("Unexpected error %s", err.Error())
}
})
}
}
En un primer paso cambiamos el código de producción para introducir y usar el tipo Nif:
package nif
import (
"errors"
"regexp"
)
type Nif string
func NewNif(candidate string) (Nif, error) {
valid := regexp.MustCompile(`(?i)^[0-9XYZ]\d{7}[^UIOÑ0-9]$`)
if !valid.MatchString(candidate) {
return "", errors.New("bad format")
}
return "", errors.New("bad control letter")
}
Ahora el test estará fallando porque no hemos validado nada todavía. Para hacerlo pasar añadimos un condicional:
package nif
import (
"errors"
"regexp"
)
type Nif string
func NewNif(candidate string) (Nif, error) {
valid := regexp.MustCompile(`(?i)^[0-9XYZ]\d{7}[^UIOÑ0-9]$`)
if !valid.MatchString(candidate) {
return "", errors.New("bad format")
}
if candidate == "00000023T" {
return Nif(candidate), nil
}
return "", errors.New("bad control letter")
}
Una nota sobre Go es que los tipos custom no pueden tener valor nil, sino vacío. Por eso en caso de error devolvemos string vacío.
Avanzando el algoritmo
De momento no hay muchos motivos para hacer refactor, así que vamos a introducir un test que nos ayude a avanzar un poco. En principio, queremos lograr que nos impulse a separar la parte numérica de la letra de control.
Una posibilidad sería testear otro NIF que acabe con la letra T, como el 00000046T.
func TestShouldCreateNifTypeWithValidCandidate(t *testing.T) {
tests := []struct {
name string
example string
}{
{"should accept mod23 being 0", "00000023T"},
{"should accept mod23 being 0 letter T", "00000046T"},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
nif, err := NewNif(test.example)
if nif != Nif(test.example) {
t.Errorf("Expected Nif(%s), got %s", test.example, nif)
}
if err != nil {
t.Errorf("Unexpected error %s", err.Error())
}
})
}
}
Para hacer pasar el test, podemos hacer esta implementación sencilla:
package nif
import (
"errors"
"regexp"
)
type Nif string
func NewNif(candidate string) (Nif, error) {
valid := regexp.MustCompile(`(?i)^[0-9XYZ]\d{7}[^UIOÑ0-9]$`)
if !valid.MatchString(candidate) {
return "", errors.New("bad format")
}
if candidate == "00000023T" {
return Nif(candidate), nil
}
if candidate == "00000046T" {
return Nif(candidate), nil
}
return "", errors.New("bad control letter")
}
Y ahora empezamos a refactorizar.
Más refactor
En el código de producción podemos ver lo que hay de diferente y de común entre los ejemplos. En ambos la letra de control es T y la parte numérica es divisible entre 23, por lo que su mod23 será 0.
Ahora podemos hacer el refactor. Un primer paso.
package nif
import (
"errors"
"regexp"
)
type Nif string
func NewNif(candidate string) (Nif, error) {
valid := regexp.MustCompile(`(?i)^[0-9XYZ]\d{7}[^UIOÑ0-9]$`)
if !valid.MatchString(candidate) {
return "", errors.New("bad format")
}
control := string(candidate[8])
if control == "T" {
return Nif(candidate), nil
}
return "", errors.New("bad control letter")
}
Y, después de ver pasar los tests, el segundo paso:
package nif
import (
"errors"
"regexp"
"strconv"
)
type Nif string
func NewNif(candidate string) (Nif, error) {
valid := regexp.MustCompile(`(?i)^[0-9XYZ]\d{7}[^UIOÑ0-9]$`)
if !valid.MatchString(candidate) {
return "", errors.New("bad format")
}
control := string(candidate[8])
numeric, _ := strconv.Atoi(candidate[0:8])
modulus := numeric % 23
if control == "T" && modulus == 0 {
return Nif(candidate), nil
}
return "", errors.New("bad control letter")
}
Con este cambio los tests pasan y acepta todos los NIF válidos acabados en T.
Validando más letras de control
En este tipo de algoritmos no tiene mucho sentido intentar validar todas las letras de control, pero podemos introducir una más para forzarnos a entender cómo debería evolucionar el código ahora. Probaremos con una nueva letra:
package nif
import "testing"
func TestShouldFailIfCandidateIsInvalid(t *testing.T) {
tests := []struct {
name string
example string
expected string
}{
{
"should fail if too long",
"01234567891011",
"bad format",
},
{
"should fail if too short",
"01234",
"bad format",
},
{
"should fail if starts with a letter other than X, Y, Z",
"A12345678",
"bad format",
},
{
"should fail if doesn't have 7 digit in the middle",
"0123X567R",
"bad format",
},
{
"should fail if doesn't end with a valid control letter",
"01234567U",
"invalid end format",
},
{
"should fail if doesn't end with the right control letter",
"00000000S",
"bad control letter",
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
_, err := NewNif(test.example)
if err.Error() != test.expected && err.Error() != "bad format" {
t.Errorf("Expected %s, got %s", test.expected, err.Error())
}
})
}
}
func TestShouldCreateNifTypeWithValidCandidate(t *testing.T) {
tests := []struct {
name string
example string
}{
{"should accept mod23 being 0", "00000000T"},
{"should accept mod23 being 0 letter T", "00000023T"},
{"should accept mod23 being 1 letter R", "00000024R"},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
nif, err := NewNif(test.example)
if nif != Nif(test.example) {
t.Errorf("Expected Nif(%s), got %s", test.example, nif)
}
if err != nil {
t.Errorf("Unexpected error %s", err.Error())
}
})
}
}
Ya tenemos este test fallando, así que vamos a hacer una implementación muy sencilla:
package nif
import (
"errors"
"regexp"
"strconv"
)
type Nif string
func NewNif(candidate string) (Nif, error) {
valid := regexp.MustCompile(`(?i)^[0-9XYZ]\d{7}[^UIOÑ0-9]$`)
if !valid.MatchString(candidate) {
return "", errors.New("bad format")
}
control := string(candidate[8])
numeric, _ := strconv.Atoi(candidate[0:8])
modulus := numeric % 23
if control == "T" && modulus == 0 {
return Nif(candidate), nil
}
if control == "R" && modulus == 1 {
return Nif(candidate), nil
}
return "", errors.New("bad control letter")
}
Esto ya nos da una idea de por dónde van los tiros: un mapa entre letras de control y el resto al dividir por 23. Sin embargo, es frecuente que los strings puedan funcionar como arrays en muchos lenguajes, por lo que nos basta tener un string con todas las letras de control ordenadas y acceder a la letra en la posición indicada por el módulo para saber cuál es la correcta.
Un refactor para más simplicidad
Primero implementamos una versión simple de esta idea:
package nif
import (
"errors"
"regexp"
"strconv"
)
type Nif string
func NewNif(candidate string) (Nif, error) {
valid := regexp.MustCompile(`(?i)^[0-9XYZ]\d{7}[^UIOÑ0-9]$`)
if !valid.MatchString(candidate) {
return "", errors.New("bad format")
}
controlMap := "TR"
control := candidate[8]
numeric, _ := strconv.Atoi(candidate[0:8])
modulus := numeric % 23
if control == controlMap[modulus] {
return Nif(candidate), nil
}
return "", errors.New("bad control letter")
}
Ya tenemos una primera versión. Luego añadiremos la lista completa de letras, pero podemos intentar arreglar un poco el código actual. Primero hacemos que controlMap sea constante:
package nif
import (
"errors"
"regexp"
"strconv"
)
type Nif string
func NewNif(candidate string) (Nif, error) {
valid := regexp.MustCompile(`(?i)^[0-9XYZ]\d{7}[^UIOÑ0-9]$`)
if !valid.MatchString(candidate) {
return "", errors.New("bad format")
}
const controlMap = "TR"
control := candidate[8]
numeric, _ := strconv.Atoi(candidate[0:8])
modulus := numeric % 23
if control == controlMap[modulus] {
return Nif(candidate), nil
}
return "", errors.New("bad control letter")
}
En realidad podríamos extraer toda la parte del cálculo del módulo a otra función. Primero reorganizamos el código para controlar mejor la extracción:
package nif
import (
"errors"
"regexp"
"strconv"
)
type Nif string
func NewNif(candidate string) (Nif, error) {
valid := regexp.MustCompile(`(?i)^[0-9XYZ]\d{7}[^UIOÑ0-9]$`)
if !valid.MatchString(candidate) {
return "", errors.New("bad format")
}
control := candidate[8]
const controlMap = "TR"
numeric, _ := strconv.Atoi(candidate[0:8])
modulus := numeric % 23
shouldBe := controlMap[modulus]
if control == shouldBe {
return Nif(candidate), nil
}
return "", errors.New("bad control letter")
}
Recuerda verificar que pasan los tests. Ahora extraemos la función:
package nif
import (
"errors"
"regexp"
"strconv"
)
type Nif string
func NewNif(candidate string) (Nif, error) {
valid := regexp.MustCompile(`(?i)^[0-9XYZ]\d{7}[^UIOÑ0-9]$`)
if !valid.MatchString(candidate) {
return "", errors.New("bad format")
}
control := candidate[8]
if control == shouldHaveControl(candidate) {
return Nif(candidate), nil
}
return "", errors.New("bad control letter")
}
func shouldHaveControl(candidate string) uint8 {
const controlMap = "TR"
numeric, _ := strconv.Atoi(candidate[0:8])
modulus := numeric % 23
return controlMap[modulus]
}
Y podemos compactar el código un poco más, mientras que añadimos las demás letras de control. A primera vista parece “trampa”, pero en el fondo no es más que generalizar un algoritmo que se podría enunciar como “toma la letra que hay en la posición dada por el mod23 de la parte numérica”.
package nif
import (
"errors"
"regexp"
"strconv"
)
type Nif string
func NewNif(candidate string) (Nif, error) {
valid := regexp.MustCompile(`(?i)^[0-9XYZ]\d{7}[^UIOÑ0-9]$`)
if !valid.MatchString(candidate) {
return "", errors.New("bad format")
}
if candidate[8] == shouldHaveControl(candidate) {
return Nif(candidate), nil
}
return "", errors.New("bad control letter")
}
func shouldHaveControl(candidate string) uint8 {
const controlMap = "TRWAGMYFPDXBNJZSQVHLCKE"
numeric, _ := strconv.Atoi(candidate[0:8])
modulus := numeric % 23
return controlMap[modulus]
}
Con esto ya podemos validar todos los NIF, excepto los NIE, que empiezan por las letras X, Y o Z.
Dar soporte a NIE
Ahora que hemos implementado el algoritmo general vamos a tratar sus excepciones, que no son tanto. Los NIE comienzan con una letra que a efectos del cálculo se reemplaza con un número.
El test que parece más evidente en este punto es el siguiente:
func TestShouldCreateNifTypeWithValidCandidate(t *testing.T) {
tests := []struct {
name string
example string
}{
{"should accept mod23 being 0", "00000000T"},
{"should accept mod23 being 0 letter T", "00000023T"},
{"should accept mod23 being 1 letter R", "00000024R"},
{"should accept NIE starting with X", "X0000023T"},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
nif, err := NewNif(test.example)
if nif != Nif(test.example) {
t.Errorf("Expected Nif(%s), got %s", test.example, nif)
}
if err != nil {
t.Errorf("Unexpected error %s", err.Error())
}
})
}
}
El caso X0000023T es equivalente a 00000023T, ¿afectará eso al resultado del test?
Ejecutamos el test y… ¿Sorpresa? El test pasa. Esto ocurre porque la conversión que hacemos en esta línea genera un error que actualmente estamos ignorando, pero permite que la parte numérica siga siendo equivalente a 23, cuyo mod23 es 0 y le corresponde igualmente la letra T.
numeric, _ := strconv.Atoi(candidate[0:8])
En otros lenguajes la conversión no falla, pero asume la X como 0 al realizar la conversión.
En cualquier caso eso nos abre dos posibles caminos:
- anular este test y refactorizar el código de producción para tratar el error y que el test falle cuando lo volvamos a incluir
- probar otro ejemplo que sí pueda fallar (
Y0000000Z) y hacer el cambio después
Posiblemente, para este caso la segunda opción sería más que suficiente, ya que con nuestras validaciones estructurales ya garantizaríamos que el error no tiene posibilidad de aparecer una vez que la función esté completamente desarrollada.
Sin embargo, podría ser interesante introducir la gestión del error. Manejar los errores, incluyendo los que nunca podrían llegar a pasar, es siempre una buena práctica.
Así que, anulemos el test e introduzcamos un refactor para manejar el error:
func TestShouldCreateNifTypeWithValidCandidate(t *testing.T) {
tests := []struct {
name string
example string
}{
{"should accept mod23 being 0", "00000000T"},
{"should accept mod23 being 0 letter T", "00000023T"},
{"should accept mod23 being 1 letter R", "00000024R"},
//{"should accept NIE starting with X", "X0000023X"},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
nif, err := NewNif(test.example)
if nif != Nif(test.example) {
t.Errorf("Expected Nif(%s), got %s", test.example, nif)
}
if err != nil {
t.Errorf("Unexpected error %s", err.Error())
}
})
}
}
Aquí el refactor. En este caso, gestiono el error provocando un panic, que no es la mejor manera de gestionar un error, pero que nos permite hacer que el test pueda fallar y obligarnos a implementar la solución.
package nif
import (
"errors"
"regexp"
"strconv"
)
type Nif string
func NewNif(candidate string) (Nif, error) {
valid := regexp.MustCompile(`(?i)^[0-9XYZ]\d{7}[^UIOÑ0-9]$`)
if !valid.MatchString(candidate) {
return "", errors.New("bad format")
}
if candidate[8] == shouldHaveControl(candidate) {
return Nif(candidate), nil
}
return "", errors.New("bad control letter")
}
func shouldHaveControl(candidate string) uint8 {
const controlMap = "TRWAGMYFPDXBNJZSQVHLCKE"
numeric, err := strconv.Atoi(candidate[0:8])
if err != nil {
panic("Numeric part contains letters")
}
modulus := numeric % 23
return controlMap[modulus]
}
Al ejecutar los tests, comprobamos que siguen en verde. Pero si reactivamos el último test vemos cómo falla:
func TestShouldCreateNifTypeWithValidCandidate(t *testing.T) {
tests := []struct {
name string
example string
}{
{"should accept mod23 being 0", "00000000T"},
{"should accept mod23 being 0 letter T", "00000023T"},
{"should accept mod23 being 1 letter R", "00000024R"},
{"should accept NIE starting with X", "X0000023X"},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
nif, err := NewNif(test.example)
if nif != Nif(test.example) {
t.Errorf("Expected Nif(%s), got %s", test.example, nif)
}
if err != nil {
t.Errorf("Unexpected error %s", err.Error())
}
})
}
}
Y esto ya nos obliga a introducir un tratamiento para estos casos. Básicamente, es reemplazar X por 0:
package nif
import (
"errors"
"regexp"
"strconv"
"strings"
)
type Nif string
func NewNif(candidate string) (Nif, error) {
valid := regexp.MustCompile(`(?i)^[0-9XYZ]\d{7}[^UIOÑ0-9]$`)
if !valid.MatchString(candidate) {
return "", errors.New("bad format")
}
if candidate[8] == shouldHaveControl(candidate) {
return Nif(candidate), nil
}
return "", errors.New("bad control letter")
}
func shouldHaveControl(candidate string) uint8 {
const controlMap = "TRWAGMYFPDXBNJZSQVHLCKE"
var numPart = candidate[0:8]
if string(candidate[0]) == "X" {
numPart = strings.Replace(numPart, "X", "0", 1)
}
numeric, err := strconv.Atoi(numPart)
if err != nil {
panic("Numeric part contains letters")
}
modulus := numeric % 23
return controlMap[modulus]
}
Se puede refactorizar usando un Replacer:
package nif
import (
"errors"
"regexp"
"strconv"
"strings"
)
type Nif string
func NewNif(candidate string) (Nif, error) {
valid := regexp.MustCompile(`(?i)^[0-9XYZ]\d{7}[^UIOÑ0-9]$`)
if !valid.MatchString(candidate) {
return "", errors.New("bad format")
}
if candidate[8] == shouldHaveControl(candidate) {
return Nif(candidate), nil
}
return "", errors.New("bad control letter")
}
func shouldHaveControl(candidate string) uint8 {
const controlMap = "TRWAGMYFPDXBNJZSQVHLCKE"
var numPart = candidate[0:8]
re := strings.NewReplacer("X", "0")
numeric, err := strconv.Atoi(re.Replace(numPart))
if err != nil {
panic("Numeric part contains letters")
}
modulus := numeric % 23
return controlMap[modulus]
}
En este punto podríamos hacer un test para forzarnos a introducir el resto de reemplazos. Es barato, aunque en el fondo no es muy necesario por lo que comentamos antes: podemos interpretar esta parte del algoritmo como “reemplazar las letras iniciales X, Y y Z por los números 0, 1 y 2, respectivamente”:
package nif
import "testing"
func TestShouldFailIfCandidateIsInvalid(t *testing.T) {
tests := []struct {
name string
example string
expected string
}{
{
"should fail if too long",
"01234567891011",
"bad format",
},
{
"should fail if too short",
"01234",
"bad format",
},
{
"should fail if starts with a letter other than X, Y, Z",
"A12345678",
"bad format",
},
{
"should fail if doesn't have 7 digit in the middle",
"0123X567R",
"bad format",
},
{
"should fail if doesn't end with a valid control letter",
"01234567U",
"invalid end format",
},
{
"should fail if doesn't end with the right control letter",
"00000000S",
"bad control letter",
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
_, err := NewNif(test.example)
if err.Error() != test.expected && err.Error() != "bad format" {
t.Errorf("Expected %s, got %s", test.expected, err.Error())
}
})
}
}
func TestShouldCreateNifTypeWithValidCandidate(t *testing.T) {
tests := []struct {
name string
example string
}{
{"should accept mod23 being 0", "00000000T"},
{"should accept mod23 being 0 letter T", "00000023T"},
{"should accept mod23 being 1 letter R", "00000024R"},
{"should accept NIE starting with X", "X0000000T"},
{"should accept NIE starting with Y", "Y0000000Z"},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
nif, err := NewNif(test.example)
if nif != Nif(test.example) {
t.Errorf("Expected Nif(%s), got %s", test.example, nif)
}
if err != nil {
t.Errorf("Unexpected error %s", err.Error())
}
})
}
}
Solo es necesario añadir los pares correspondientes:
package nif
import (
"errors"
"regexp"
"strconv"
"strings"
)
type Nif string
func NewNif(candidate string) (Nif, error) {
valid := regexp.MustCompile(`(?i)^[0-9XYZ]\d{7}[^UIOÑ0-9]$`)
if !valid.MatchString(candidate) {
return "", errors.New("bad format")
}
if candidate[8] == shouldHaveControl(candidate) {
return Nif(candidate), nil
}
return "", errors.New("bad control letter")
}
func shouldHaveControl(candidate string) uint8 {
const controlMap = "TRWAGMYFPDXBNJZSQVHLCKE"
var numPart = candidate[0:8]
re := strings.NewReplacer("X", "0",
"Y", "1",
"Z", "2")
numeric, err := strconv.Atoi(re.Replace(numPart))
if err != nil {
panic("Numeric part contains letters")
}
modulus := numeric % 23
return controlMap[modulus]
}
Después de un rato de refactor, esta sería una posible solución:
package nif
import (
"errors"
"regexp"
"strconv"
"strings"
)
type Nif string
func NewNif(candidate string) (Nif, error) {
valid := regexp.MustCompile(`(?i)^[0-9XYZ]\d{7}[^UIOÑ0-9]$`)
if !valid.MatchString(candidate) {
return "", errors.New("bad format")
}
if candidate[8] != controlLetterFor(candidate) {
return "", errors.New("bad control letter")
}
return Nif(candidate), nil
}
func controlLetterFor(candidate string) uint8 {
const controlMap = "TRWAGMYFPDXBNJZSQVHLCKE"
position, err := controlPosition(candidate[0:8])
if err != nil {
panic("Numeric part contains letters")
}
return controlMap[position]
}
func controlPosition(numPart string) (int, error) {
re := strings.NewReplacer("X", "0", "Y", "1", "Z", "2")
numeric, err := strconv.Atoi(re.Replace(numPart))
return numeric % 23, err
}
Qué hemos aprendido con esta kata
- Utilizar sad paths para mover el desarrollo
- Utilizar table tests en Go reduciendo el coste de añadir nuevos tests
- Una técnica para cambiar los errores devueltos por otro más general sin romper los tests
- Una técnica para cambiar la interfaz pública del código de producción sin romper los tests
Referencias
- Is Go object-oriented?1
14 La fase de refactor
En capítulos anteriores, mencionamos las leyes de TDD. Originalmente, estas leyes eran dos, en la formulación de Kent Beck:
- No escribir una línea de código sin antes tener un test automático que falle
- Eliminar la duplicación
En esencia, lo que Kent Beck proponía es definir primero una pequeña parte de la especificación mediante un test, implementar un algoritmo muy pequeño que la satisfaga y, a continuación, revisar el código en busca de casos de duplicación para refactorizarlos en un algoritmo más general y flexible.
Y eso es, más o menos, como define Martin Fowler el ciclo Red-Green-Refactor:
- Escribe un test para el siguiente fragmento de funcionalidad que deseas añadir
- Escribe el código de producción necesario para que el test pase
- Refactoriza el código, tanto el nuevo como el anterior, para que esté bien estructurado
Este enunciado parece dar por sentado que el refactor es, por así decir, el final de cada etapa del proceso. Pero, paradójicamente, si interpretamos el ciclo al pie de la letra caeremos en una mala práctica.
La función del refactor en TDD
Por lo general, en Test Driven Development se favorece que tanto los tests como los cambios en el código de producción sean lo más pequeños posible. Este enfoque minimalista es beneficioso porque nos permite trabajar con poca carga cognitiva en cada ciclo, mientras aprendemos y alcanzamos una mayor y más profunda comprensión del problema, aplazando decisiones hasta un momento en que estemos mejor informadas para afrontarlas.
Normalmente, los pequeños pasos en TDD nos permiten hacer cambios de código muy sencillos cada vez. Muchas veces estos cambios son obvios y nos llevan a implementaciones que podríamos considerar ingenuas. Sin embargo, por muy sencillas o bastas que nos parezcan, estas implementaciones hacen pasar los tests y, por tanto, cumplen las especificaciones. Podríamos entregar ese código si es el caso porque el comportamiento ha sido desarrollado.
La fase de refactor está precisamente para hacer evolucionar esas implementaciones ingenuas a mejores diseños teniendo la red de seguridad que nos proporcionan los tests que están pasando.
Que refactors ejecutar
En cada ciclo es posible realizar diversos refactors. Obviamente, en las primeras fases serán más pequeños e incluso es posible que nos parezca que no son necesarios. Sin embargo, es conveniente aprovechar la oportunidad cuando se presenta.
Podemos hacer muchos tipos de refactors, entre otros:
- Introducir constantes para reemplazar valores mágicos.
- Cambiar nombres de variables y parámetros para reflejar mejor sus intenciones.
- Extraer métodos privados.
- Extraer condicionales a métodos cuando se vuelvan complejas.
- Aplanar estructuras condicionales anidadas.
- Extraer ramas de condicionales a métodos privados.
- Extraer funcionalidad a colaboradores.
Límites del refactor
En ocasiones, un exceso de refactor puede llevarnos a que la implementación se complique y sea difícil avanzar en el proceso de TDD. Esto ocurre cuando introducimos ciertos patrones de forma prematura, sin que el desarrollo esté todavía terminado. Sería un refactor prematuro parecido a la optimización prematura, generando un código difícil de mantener.
Podríamos decir que hay dos modalidades de refactor implicadas:
- Una de alcance limitado aplicable en cada ciclo red-green-refactor cuya función es facilitar la legibilidad, sostenibilidad y capacidad de evolución del algoritmo en desarrollo.
- La otra que tendrá lugar una vez que hemos completado toda la funcionalidad y cuyo objetivo es introducir un diseño más evolucionado y orientado a patrones.
Otra cuestión interesante es la introducción de características exclusivas o propias del lenguaje, que en principio también convendría posponer hasta esa fase final. ¿Por qué dejarlas para este momento? Precisamente porque pueden limitar nuestra capacidad de refactorizar un código si todavía no tenemos seguridad acerca de hacia dónde podría evolucionar.
Por ejemplo, en Ruby esta construcción:
def greet(name = nil)
if name.nil?
name = 'my friend'
end
"Hello, #{name}"
end
Podría refactorizarse, y de hecho se recomienda, de esta forma que me parece realmente bonita:
def greet(name = nil)
name = 'my friend' if name.nil?
"Hello, #{name}"
end
En este caso, la estructura representa la idea de asignar un valor por defecto a la variable, algo que podríamos conseguir también de este modo, el cual es común a otros lenguajes:
def greet(name = 'my friend')
"Hello, #{name}"
end
Las tres variantes hacen pasar los tests, pero cada una de ellas nos coloca en una posición ligeramente distinta de cara a los futuros requerimientos.
Por ejemplo, supongamos que nuestro próximo requerimiento nos pide poder introducir varios nombres. Una posible solución para eso es usar splat parameters, es decir, que la función admita un número indefinido de parámetros que luego se presentarán dentro del método como un array. En Ruby esto se expresa así:
def greet(*name)
#
end
Esta declaración, por ejemplo, es incompatible con la tercera variante, ya que el splat operator no admite un valor por defecto y tendremos que reimplementar ese paso, lo que nos llevará de nuevo a utilizar una de las otras variantes.
En principio no parece que sea un gran inconveniente, pero implica deshacer toda la lógica que venga determinada por esa estructura y, según el momento de desarrollo en que nos encontremos puede llevarnos incluso a callejones sin salida.
En las otras opciones, es un poco menos inconveniente. Además de cambiar la signatura lo único que tenemos que modificar es la pregunta (empty? por nil?) y el valor por defecto que, en lugar de un string, pasa a ser un array de string. Por supuesto, para finalizar tenemos que hacer un join de la colección para poder mostrarlo en el saludo.
def greet(*name)
if name.empty?
name = ['my friend']
end
names = name.join(', ')
"Hello, #{names}"
end
O la versión rubyficada:
def greet(*name)
name = ['my friend'] if name.empty?
names = name.join(', ')
"Hello, #{names}"
end
Aparte de eso, sería necesario en este punto un refactor del nombre del parámetro que exprese más claramente su nuevo significado:
def greet(*people)
people = ['my friend'] if people.empty?
names = people.join(', ')
"Hello, #{names}"
end
Así que como recomendación general es conveniente buscar un equilibrio entre los refactors que nos ayudan a mantener el código limpio y legible de aquellos que podríamos considerar como sobreingeniería. Una implementación un poco menos refinada puede ser más fácil de cambiar que una muy evolucionada a medida que se introducen nuevos tests.
No sobre refactorices antes de tiempo.
Cuando es el momento de hacer refactor
Para hacer refactor la condición sine qua non es que todos los tests existentes estén pasando. En este momento nos interesa analizar el estado de la implementación y aplicar los refactors que mejor le vayan.
Si un test está en rojo nos indica que una parte de la especificación no está conseguida y, por lo tanto, debemos trabajar en eso y no en el refactor.
Pero hay un caso especial: cuando añadimos un nuevo test que falla y nos damos cuenta de que necesitamos un refactor previo para poder implementar la solución más obvia o sencilla para ese test.
¿Cómo actuamos en este caso? Pues tenemos que dar un paso atrás.
El paso atrás en el ciclo Red-Green-Refactor
Supongamos un ejemplo sencillo. Vamos a iniciar la Greeting kata de testdouble. Empezamos con un test con el que definir la interfaz:
require 'rspec'
RSpec.describe 'A simple greeting' do
it 'should greet a person' do
expect(greet('Fran')).to eq('Hello, Fran')
end
end
Nuestro siguiente paso es crear la implementación más sencilla para que el test pase, cosa que podríamos hacer así:
def greet(name)
'Hello, Fran'
end
El siguiente requerimiento es que maneje el caso de que no se proporcione nombre, en cuyo caso debe ofrecer alguna fórmula anónima como la que ponemos de ejemplo en este test:
require 'rspec'
def greet(name)
'Hello, Fran'
end
RSpec.describe 'A simple greeting' do
it 'should greet a person' do
expect(greet('Fran')).to eq('Hello, Fran')
end
it 'should greet even if no name provided' do
expect(greet).to eq('Hello, my friend')
end
end
El test falla en primer lugar porque el argumento no es opcional. Pero es que además no se usa en la implementación actual y necesitamos usarlo para hacer lo más obvio que requiere este test. Tenemos que ejecutar varios pasos preparatorios antes de poder realizar la implementación, a saber:
- Hacer opcional el parámetro
name - Usar el parámetro en el valor de retorno
El caso es que con el nuevo requerimiento tenemos nueva información que nos sería útil para refactorizar lo desarrollado gracias al primer test. Sin embargo, como tenemos un nuevo test que falla, no deberíamos hacer refactor, por lo que eliminamos o anulamos el test anterior. Por ejemplo, comentándolo:
require 'rspec'
def greet(name)
'Hello, Fran'
end
RSpec.describe 'A simple greeting' do
it 'should greet a person' do
expect(greet('Fran')).to eq('Hello, Fran')
end
# it 'should greet even if no name provided' do
# expect(greet).to eq('Hello, my friend')
# end
end
Al hacer así, volvemos a tener los tests en verde y podemos aplicar los cambios necesarios, que no alteran el comportamiento implementado hasta el momento.
Hacemos opcional el parámetro del nombre.
def greet(name = nil)
'Hello, Fran'
end
Aquí empezamos a dar uso al parámetro:
def greet(name)
"Hello, #{name}"
end
Esto nos ha permitido pasar de nuestra primera implementación tosca a una lo bastante flexible con la que el test sigue pasando y estamos en mejores condiciones para volver a introducir el siguiente test:
require 'rspec'
def greet(name = nil)
"Hello, #{name}"
end
RSpec.describe 'A simple greeting' do
it 'should greet a person' do
expect(greet('Fran')).to eq('Hello, Fran')
end
it 'should greet even if no name provided' do
expect(greet).to eq('Hello, my friend')
end
end
Obviamente, el test falla, pero la razón del fallo es justamente que nos falta código que resuelva el requerimiento. Lo único que tenemos que hacer es comprobar si recibimos un nombre o no, y actuar en consecuencia.
def greet(name = nil)
if name.nil?
name = 'my friend'
end
"Hello, #{name}"
end
En cierto modo, resulta que la información del futuro, o sea, el nuevo test que planteamos para introducir la siguiente funcionalidad, afecta al pasado, es decir al estado adecuado del código para poder continuar, y nos obliga a considerar la profundidad del refactor necesario antes de afrontar el nuevo ciclo. En esta situación, lo mejor es volver al último test que pasaba, anulando el nuevo, y trabajar en el refactor hasta estar mejor preparadas para continuar avanzando.
15 Bowling game
La fase de refactor
En las katas anteriores, por lo general, los ciclos de TDD se ejecutaban de forma bastante fluida.
Sin embargo, es posible que hayas notado que, en algún momento, hacer pasar un nuevo test implicaba un cierto refactor del código de producción antes de poder afrontar los cambios necesarios para hacer pasar el test.
La kata que vamos a practicar ahora, además de ser una de las clásicas, tiene la particularidad de que casi cada nueva funcionalidad que añadimos, cada nuevo test, require un refactor relativamente grande del algoritmo. Eso nos pone en un dilema: no podemos estar refactorizando si el test no está en verde.
O dicho de otro modo: en ocasiones nos encontraremos que el nuevo test nos proporciona una información que no teníamos antes y que nos muestra una oportunidad de refactor que debemos afrontar antes de implementar la parte nueva de funcionalidad.
Por eso, con la kata Bowling Game, aprenderemos cómo manejar esta situación y dar un paso atrás para refactorizar el código de producción con lo aprendido al pensar en el nuevo test.
En cierto modo, la información del futuro nos ayudará a cambiar el pasado.
Historia
La kata Bowling es muy conocida. Se la debemos a Robert C. Martin, aunque una versión muy popular es la de Ron Jeffreys en el libro Adventures in C#
Enunciado
La kata consiste en crear un programa para calcular las puntuaciones del juego de los Bolos, aunque para evitar complicarla mucho solo se calcula el resultado final y no se hacen validaciones sobre las puntuaciones.
Si no tienes familiaridad con el juego y su sistema de puntuación, aquí van las reglas que es necesario conocer:
- En cada juego, el jugador o jugadora tiene 10 turnos, llamados frames.
- Dentro de cada frame, se dispone de dos intentos para tumbar los 10 bolos (eso hace un total de 20 intentos o lanzamientos de bola en todo el juego).
- En cada intento, se cuentan los bolos tumbados y la puntuación del frame es la suma de ambos intentos.
- Si no se tira ningún bolo es un Gutter.
- Si no se han tirado todos los bolos en los dos intentos esa será la puntuación. Por ejemplo 3 + 5 = 8 puntos en el frame.
- Si se han tumbado los 10 bolos en el frame (por ejemplo 4 + 6), a eso se le llama spare y se obtiene un bonus que será la puntuación del siguiente lanzamiento, el primero del siguiente frame (10 del frame actual + 3 del siguiente lanzamiento = 13). Esto es, la puntuación final de un spare se calcula después del siguiente lanzamiento y, por así decir, ese lanzamiento se cuenta dos veces (una como bonus y otra normal).
- Si se han tumbado los 10 bolos en un solo lanzamiento es un strike y en ese caso, el bonus es la puntuación del siguiente frame (por ejemplo, 10 + (3 + 4) = 17).
- En el caso de que esto se produzca en el último frame, se hacen uno o dos lanzamientos extras según sea necesario.
Orientaciones para resolverla
La Bowling Game es una kata interesante por el reto que plantea el tratamiento de los spares y strikes. Cuando detectamos uno de estos casos, tenemos que consultar el resultado de los siguientes lanzamientos por lo que necesitamos conservar la historia de la partida.
Esto nos obligará a cambiar el algoritmo varias veces de una forma un tanto radical, lo que nos pone ante el problema de cómo gestionar estos cambios sin romper los ciclos de TDD, es decir, refactorizando el código de producción mientras se mantienen los tests pasando.
Para entender mejor lo que queremos decir, la situación sería la siguiente:
Después de un par de ciclos comenzamos a testear por el caso spare. En ese punto nos damos cuenta de que necesitamos hacer un cambio relativamente grande al modo en que estábamos calculando la puntuación total. En último término, lo que ocurre es que tenemos que refactorizar mientras un test no pasa. Pero es contradictorio con la definición de la fase de refactor que exige que todos los tests estén pasando.
La solución, por suerte, es muy sencilla: dar un paso atrás.
Una vez que sabemos que queremos refactorizar el algoritmo, nos basta comentar el nuevo test para desactivarlo y, con el test anterior pasando, refactorizar el código de producción. Cuando lo tengamos, volvemos a traer a la vida el nuevo test y desarrollamos el nuevo comportamiento.
Enlaces de interés sobre la kata Bowling Game
16 Resolviendo la kata Bowling Game
Enunciado de la kata
La kata consiste en crear un programa para calcular las puntuaciones de un jugador en un juego de los Bolos, aunque para evitar complicarla mucho solo se calcula el resultado final y no se hacen validaciones sobre las puntuaciones.
Un breve recordatorio de las reglas:
- Cada juego tiene 10 turnos de 2 lanzamientos cada uno.
- En cada turno se cuentan los bolos que han caído y ese número es la puntuación
- 0 puntos es un gutter
- Si se tiran todos los bolos entre los dos intentos es un spare, y se suma como bonus la puntuación del siguiente lanzamiento
- Si se tiran todos los bolos en el primer lanzamiento es un strike, y se suma como bonus la puntuación de los siguientes dos lanzamientos
- Si el strike o el spare se logran en el último frame habrá lanzamientos extra
Lenguaje y enfoque
Para hacer esta kata he escogido Ruby y RSpec. Posiblemente, notes que tengo cierta preferencia por los frameworks de test de la familia *Spec, pero es que han sido diseñados pensando en TDD, considerando el test como especificación lo que ayuda mucho a salirse del marco de pensar en los tests como QA.
Dicho eso, no hay ningún problema en usar cualquier otro framework de testing, como los de la familia *Unit.
Por otro lado, emplearemos orientación a objetos.
Iniciando el juego
A estas alturas, el primer test debería ser suficiente para forzarnos a definir e instanciar la clase:
require 'rspec'
RSpec.describe 'A Bowling Game' do
it 'should start a new game' do
BowlingGame.new
end
end
El test fallará, obligándonos a escribir el código de producción mínimo para que llegue a pasar.
class BowlingGame
end
Y una vez que hemos hecho pasar el test, movemos la clase a su propio archivo y la requerimos:
require 'rspec'
require_relative '../src/bowling_game'
RSpec.describe 'A Bowling Game' do
it 'should start a new game' do
BowlingGame.new
end
end
Estamos listas para el siguiente paso.
Lancemos la bola
Para que nuestro BowlingGame sea útil necesitaremos al menos dos cosas:
- Una forma de indicar el resultado de un lanzamiento, pasando el número de bolos derribado, que sería un command. Un command provoca un efecto en el estado de un objeto, pero no devuelve nada por lo que necesitamos una vía alternativa de observar ese efecto.
- Una forma de obtener la puntuación en un momento dado, que sería una query. Una query devuelve una respuesta, por lo que podemos verificar que es la que esperamos.
Puede que te preguntes: ¿Cuál de las dos deberíamos atacar primero?
No hay una regla fija, pero una forma de verlo puede ser la siguiente:
Los métodos query devuelven un resultado y su efecto puede testearse, pero hay que tener en cuenta en este punto asegurarnos de que la respuesta esperada no nos dificultará crear nuevos tests que fallen.
Por contra, los métodos command podemos introducirlos con un mínimo de código, sin tener que estar pendientes de sus efectos en futuros tests, salvo asegurarnos de que los parámetros que reciban son válidos.
Así que vamos a empezar introduciendo un método para lanzar la bola, que simplemente espera recibir el número de bolos derribado, que puede ser 0. Pero para forzar eso debemos escribir un test primero:
require 'rspec'
require_relative '../src/bowling_game'
RSpec.describe 'A Bowling Game' do
it 'should start a new game' do
game = BowlingGame.new
end
it 'should roll a ball knocking down 0 pins' do
game = BowlingGame.new
game.roll 0
end
end
Y el código suficiente para hacer que el test pase es simplemente definir el método. Básicamente, lo que tenemos es que podemos comunicarle a BowlingGame que hemos lanzado la bola.
class BowlingGame
def roll(pins_down)
end
end
Hora de refactorizar
En esta kata vamos a prestar especial atención a la fase de refactor. Hay que buscar un equilibrio para que ciertos refactors no nos condicionen las posibilidades de hacer evolucionar el código. Del mismo modo que la optimización prematura es un smell, la sobre ingeniería prematura también lo es.
El código de producción no ofrece todavía ninguna oportunidad de refactor, pero los tests empiezan a mostrar un patrón. El objeto game podría vivir como variable de instancia e inicializarse en un método setup de la especificación o test case. En este caso, usamos before.
require 'rspec'
require_relative '../src/bowling_game'
RSpec.describe 'A Bowling Game' do
before do
@game = BowlingGame.new
end
it 'should start a new game' do
game = BowlingGame.new
end
it 'should roll a ball knocking down 0 pins' do
@game.roll 0
end
end
Y esto hace que el primer test sea redundante:
require 'rspec'
require_relative '../src/bowling_game'
RSpec.describe 'A Bowling Game' do
before do
@game = BowlingGame.new
end
it 'should roll a ball knocking down 0 pins' do
@game.roll 0
end
end
Con esto la especificación será más manejable.
Contando los puntos
Toca introducir un método para poder saber el marcador del juego. Lo reclamamos mediante un test que falle:
require 'rspec'
require_relative '../src/bowling_game'
RSpec.describe 'A Bowling Game' do
before do
@game = BowlingGame.new
end
it 'should roll a ball knocking down 0 pins' do
@game.roll 0
end
it 'should score after a gutter roll' do
@game.roll 0
expect(@game.score).to eq(0)
end
end
El test fallará porque no existe el método score.
class BowlingGame
def roll(pins_down)
end
def score
end
end
Y seguirá fallando porque tiene que devolver 0. Lo mínimo para lograr que pase es:
class BowlingGame
def roll(pins_down)
end
def score
0
end
end
El peor lanzador del mundo
Muchas soluciones de la kata van directamente a este punto donde vamos a empezar a definir el comportamiento de BowlingGame tras los 20 lanzamientos. Nosotros hemos escogido un camino con pasos más pequeños y vamos a ver qué implica.
Nuestro siguiente test intentará hacer posible obtener un marcador tras 20 lanzamientos. Una forma de hacerlo es simularlos y lo más sencillo sería que todos ellos fuesen fallidos, es decir, que no tirasen ningún bolo con lo que el marcador final sería 0.
Este parece un buen test para empezar:
require 'rspec'
require_relative '../src/bowling_game'
RSpec.describe 'A Bowling Game' do
before do
@game = BowlingGame.new
end
it 'should roll a ball knocking down 0 pins' do
@game.roll 0
end
it 'should score after a gutter roll' do
@game.roll 0
expect(@game.score).to eq(0)
end
it 'should score a gutter game' do
20.times do
@game.roll 0
end
expect(@game.score).to eq(0)
end
end
Pero no lo es. Lo ejecutamos y pasa a la primera.
Este test no nos obliga a introducir cambios en el código de producción porque no falla. En el fondo es el mismo test que teníamos antes. Sin embargo, en algunos sentidos es un test mejor, ya que nuestro objetivo es que score nos devuelva los resultados tras la totalidad de lanzamientos.
Organizando el código
Simplemente, eliminamos el test anterior por redundante, ya que ese comportamiento estaría implícito en el que acabamos de definir.
require 'rspec'
require_relative '../src/bowling_game'
RSpec.describe 'A Bowling Game' do
before do
@game = BowlingGame.new
end
it 'should roll a ball knocking down 0 pins' do
@game.roll 0
end
it 'should score a gutter game' do
20.times do
@game.roll 0
end
expect(@game.score).to eq(0)
end
end
Como el test no nos ha requerido escribir código de producción, necesitamos un test que sí falle.
Enseñando a contar a nuestro juego
Lo mejor sería esperar un resultado distinto a cero en score para vernos obligadas a implementar nuevo código de producción. De todos los resultados posibles de un juego completo de bolos quizá el más sencillo de probar sea el caso en el que todos los lanzamientos acaban con un único bolo derribado. De este modo, esperamos que la puntuación final sea 20, y no hay posibilidad de que se generen puntos o tiradas extra.
require 'rspec'
require_relative '../src/bowling_game'
RSpec.describe 'A Bowling Game' do
before do
@game = BowlingGame.new
end
it 'should roll a ball knocking down 0 pins' do
@game.roll 0
end
it 'should score a gutter game' do
20.times do
@game.roll 0
end
expect(@game.score).to eq(0)
end
it 'should score all ones' do
20.times do
@game.roll 1
end
expect(@game.score).to eq(20)
end
end
Este test ya falla porque no hay nada que acumule los puntos obtenidos en cada lanzamiento. Por tanto, necesitamos tener esa variable, que se inicie a cero y que vaya acumulando los resultados.
Pero… un momento. Eso ¿no son muchas cosas?
Un paso atrás para llegar más lejos
Repasemos, para pasar el test que tenemos ahora fallando necesitamos:
- Añadir una variable en la clase para almacenar las puntuaciones
- Iniciarla a 0
- Acumular en ella los resultados
Son muchas cosas para añadir en un solo ciclo mientras tenemos un test fallando.
El caso es que, en realidad, podríamos olvidar este test un momento y volver al estado anterior cuando estábamos todavía en verde. Para ello comentamos el nuevo test de modo que no se ejecute.
require 'rspec'
require_relative '../src/bowling_game'
RSpec.describe 'A Bowling Game' do
before do
@game = BowlingGame.new
end
it 'should roll a ball knocking down 0 pins' do
@game.roll 0
end
it 'should score a gutter game' do
20.times do
@game.roll 0
end
expect(@game.score).to eq(0)
end
# it 'should score all ones' do
# 20.times do
# @game.roll 1
# end
# expect(@game.score).to eq(20)
# end
end
Y ahora procedemos al refactor. Empezamos cambiando la constante 0 por una variable:
class BowlingGame
def roll(pins_down)
end
def score
@score = 0
end
end
Podemos mejorar este código, guardando en la variable los puntos obtenidos en el lanzamiento. Este código sigue haciendo pasar el test y es un cambio mínimo:
class BowlingGame
def roll(pins_down)
@score = pins_down
end
def score
@score
end
end
Recuperando un test anulado
Ahora sí que lanzamos el cuarto test y vemos de nuevo que falla:
require 'rspec'
require_relative '../src/bowling_game'
RSpec.describe 'A Bowling Game' do
before do
@game = BowlingGame.new
end
it 'should roll a ball knocking down 0 pins' do
@game.roll 0
end
it 'should score a gutter game' do
20.times do
@game.roll 0
end
expect(@game.score).to eq(0)
end
it 'should score all ones' do
20.times do
@game.roll 1
end
expect(@game.score).to eq(20)
end
end
El cambio necesario en el código es más pequeño ahora. Tenemos que iniciar la variable en construcción, de modo que cada juego empieza en cero y va acumulando puntos. Fíjate que aparte del constructor nos basta con añadir un signo +.
class BowlingGame
def initialize
@score = 0
end
def roll(pins_down)
@score += pins_down
end
def score
@score
end
end
De nuevo en verde, sabiendo que ya acumulamos los puntos.
Poniéndonos más cómodas
Al observar los tests vemos que puede ser útil tener un método para lanzar varias veces la bola con el mismo resultado. Así que lo extraemos y, por supuesto, lo utilizamos:
require 'rspec'
require_relative '../src/bowling_game'
RSpec.describe 'A Bowling Game' do
before do
@game = BowlingGame.new
end
it 'should roll a ball knocking down 0 pins' do
@game.roll 0
end
it 'should score a gutter game' do
roll_many 20, 0
expect(@game.score).to eq(0)
end
it 'should score all ones' do
roll_many 20, 1
expect(@game.score).to eq(20)
end
def roll_many(times, pins_down)
times.times do
@game.roll pins_down
end
end
end
Cómo manejar un spare
Ahora que ya sabemos que nuestro BowlingGame es capaz de acumular los puntos obtenidos en cada lanzamiento es momento de seguir avanzando. Podemos empezar a tratar casos especiales como por ejemplo, cómo se procesa un spare, es decir, tumbar los diez bolos con dos lanzamientos en un frame.
Así que escribimos un test que simule esa situación. Lo más sencillo es imaginar que el spare ocurre en el primer frame y que el resultado del tercer lanzamiento es el bonus. Para que sea más fácil, el resto de lanzamientos hasta completar el juego serán 0, con lo que no introducimos puntuaciones extrañas.
He aquí un test posible:
require 'rspec'
require_relative '../src/bowling_game'
RSpec.describe 'A Bowling Game' do
before do
@game = BowlingGame.new
end
it 'should roll a ball knocking down 0 pins' do
@game.roll 0
end
it 'should score a gutter game' do
roll_many 20, 0
expect(@game.score).to eq(0)
end
it 'should score all ones' do
roll_many 20, 1
expect(@game.score).to eq(20)
end
it 'should score an spare' do
@game.roll 5
@game.roll 5
@game.roll 3
roll_many 17, 0
expect(@game.score).to eq(16)
end
def roll_many(times, pins_down)
times.times do
@game.roll pins_down
end
end
end
El test falla porque score nos devuelve 13 puntos cuando deberían ser 16. Ahora mismo no existe un mecanismo que cuente el lanzamiento posterior al spare como bonus.
El problema es que nos hace falta contar los puntos no por lanzamiento, sino por frame, para poder saber si un frame ha dado un spare o no y actuar en consecuencia. Además, ya no nos basta con ir sumando los puntos, sino que debemos pasar la responsabilidad del recuento al método score, de modo que roll se limite a almacenar los parciales y sea score quien gestione la lógica de calcular por frame.
De nuevo nos vemos en la necesidad de cambiar primero la estructura del código sin cambiar el comportamiento antes de introducir el nuevo test. Por tanto, anulamos este test y refactorizamos con el anterior como red de seguridad para introducir el concepto de frame en el recuento.
Introduciendo el concepto de frame
Primero regresamos al test anterior, anulando temporalmente el que está fallando:
require 'rspec'
require_relative '../src/bowling_game'
RSpec.describe 'A Bowling Game' do
before do
@game = BowlingGame.new
end
it 'should roll a ball knocking down 0 pins' do
@game.roll 0
end
it 'should score a gutter game' do
roll_many 20, 0
expect(@game.score).to eq(0)
end
it 'should score all ones' do
roll_many 20, 1
expect(@game.score).to eq(20)
end
# it 'should score an spare' do
# @game.roll 5
# @game.roll 5
# @game.roll 3
# roll_many 17, 0
# expect(@game.score).to eq(16)
# end
def roll_many(times, pins_down)
times.times do
@game.roll pins_down
end
end
end
Vamos por el refactor. En primer lugar, cambiamos el nombre de la variable:
class BowlingGame
def initialize
@rolls = 0
end
def roll(pins_down)
@rolls += pins_down
end
def score
@rolls
end
end
Los tests siguen pasando. Ahora cambiamos su significado y movemos la suma a score:
class BowlingGame
def initialize
@rolls = []
end
def roll(pins_down)
@rolls.push pins_down
end
def score
score = 0
@rolls.each do |roll|
score += roll
end
score
end
end
Comprobamos que los tests siguen pasando. Puede ser buen momento para introducir el concepto de frame. Sabemos que hay un máximo de 10 frames.
class BowlingGame
def initialize
@rolls = []
end
def roll(pins_down)
@rolls.push pins_down
end
def score
score = 0
roll = 0
10.times do
frame_score = @rolls[roll] + @rolls[roll+1]
score += frame_score
roll += 2
end
score
end
end
Con este cambio los tests siguen pasando y ya tenemos acceso a la puntuación por frame. Parece que estamos listos para volver a introducir el test anterior.
Seguimos manejando el spare
Volvemos a activar el test que falla.
require 'rspec'
require_relative '../src/bowling_game'
RSpec.describe 'A Bowling Game' do
before do
@game = BowlingGame.new
end
it 'should roll a ball knocking down 0 pins' do
@game.roll 0
end
it 'should score a gutter game' do
roll_many 20, 0
expect(@game.score).to eq(0)
end
it 'should score all ones' do
roll_many 20, 1
expect(@game.score).to eq(20)
end
it 'should score an spare' do
@game.roll 5
@game.roll 5
@game.roll 3
roll_many 17, 0
expect(@game.score).to eq(16)
end
def roll_many(times, pins_down)
times.times do
@game.roll pins_down
end
end
end
Ahora estamos en mejor disposición para introducir el comportamiento deseado con un cambio bastante pequeño:
class BowlingGame
def initialize
@rolls = []
end
def roll(pins_down)
@rolls.push pins_down
end
def score
score = 0
roll = 0
10.times do
frame_score = @rolls[roll] + @rolls[roll + 1]
if frame_score == 10
frame_score += @rolls[roll + 2]
end
score += frame_score
roll += 2
end
score
end
end
Añadiendo un bloque if es suficiente para hacer pasar el test.
Eliminando números mágicos y otros refactors
En este punto en que ya tenemos los tests pasando podemos hacer varias mejoras en el código. Vamos por partes:
Demos significado a algunos números mágicos en el código de producción:
class BowlingGame
def initialize
@rolls = []
end
def roll(pins_down)
@rolls.push pins_down
end
FRAMES_IN_A_GAME = 10
ALL_PINS_DOWN = 10
def score
score = 0
roll = 0
FRAMES_IN_A_GAME.times do
frame_score = @rolls[roll] + @rolls[roll + 1]
if frame_score == ALL_PINS_DOWN
frame_score += @rolls[roll + 2]
end
score += frame_score
roll += 2
end
score
end
end
El cálculo de la puntuación en el frame podría extraerse a un método y ahorrarnos la variable temporal de paso:
class BowlingGame
def initialize
@rolls = []
end
def roll(pins_down)
@rolls.push pins_down
end
FRAMES_IN_A_GAME = 10
ALL_PINS_DOWN = 10
def score
score = 0
roll = 0
FRAMES_IN_A_GAME.times do
score += frame_score(roll)
roll += 2
end
score
end
private
def frame_score(roll)
frame_score = @rolls[roll] + @rolls[roll + 1]
if frame_score == ALL_PINS_DOWN
frame_score += @rolls[roll + 2]
end
frame_score
end
end
Podemos darle significado a la suma de los puntos en cada lanzamiento del frame, así como a la pregunta de si se trata de un spare o no, y rubyficar un poco el código:
class BowlingGame
def initialize
@rolls = []
end
def roll(pins_down)
@rolls.push pins_down
end
FRAMES_IN_A_GAME = 10
ALL_PINS_DOWN = 10
def score
score = 0
roll = 0
FRAMES_IN_A_GAME.times do
frame_score = base_frame_score(roll)
frame_score += @rolls[roll + 2] if spare? frame_score
score += frame_score
roll += 2
end
score
end
private
def spare?(frame_score)
frame_score == ALL_PINS_DOWN
end
def base_frame_score(roll)
@rolls[roll] + @rolls[roll + 1]
end
end
Lo cierto es que esto nos está pidiendo a gritos extraer todo a una clase Frame, pero ahora no lo vamos a hacer, pues podríamos caer en un smell por exceso de diseño.
Por otro lado, mirando el test, podemos detectar algunos puntos de mejora. Como ser más explícitos en el ejemplo:
require 'rspec'
require_relative '../src/bowling_game'
RSpec.describe 'A Bowling Game' do
before do
@game = BowlingGame.new
end
it 'should roll a ball knocking down 0 pins' do
@game.roll 0
end
it 'should score a gutter game' do
roll_many 20, 0
expect(@game.score).to eq(0)
end
it 'should score all ones' do
roll_many 20, 1
expect(@game.score).to eq(20)
end
it 'should score an spare' do
roll_spare
@game.roll 3
roll_many 17, 0
expect(@game.score).to eq(16)
end
def roll_many(times, pins_down)
times.times do
@game.roll pins_down
end
end
def roll_spare
@game.roll 5
@game.roll 5
end
end
Y con esto damos por terminado el refactor. A continuación, queremos tratar el caso del strike.
Strike!
Strike es conseguir tumbar todos los bolos en un único lanzamiento. En ese caso, el bonus consiste en los puntos obtenidos en los siguientes dos lanzamientos. El próximo test nos propone un ejemplo de eso:
require 'rspec'
require_relative '../src/bowling_game'
RSpec.describe 'A Bowling Game' do
before do
@game = BowlingGame.new
end
it 'should roll a ball knocking down 0 pins' do
@game.roll 0
end
it 'should score a gutter game' do
roll_many 20, 0
expect(@game.score).to eq(0)
end
it 'should score all ones' do
roll_many 20, 1
expect(@game.score).to eq(20)
end
it 'should score an spare' do
roll_spare
@game.roll 3
roll_many 17, 0
expect(@game.score).to eq(16)
end
it 'should score an strike' do
@game.roll(10)
@game.roll(4)
@game.roll(3)
roll_many 17, 0
expect(@game.score).to eq(24)
end
def roll_many(times, pins_down)
times.times do
@game.roll pins_down
end
end
def roll_spare
@game.roll 5
@game.roll 5
end
end
En esta ocasión el test falla porque el código de producción calcula un total de 17 puntos (los 10 del strike más los 7 de los dos siguientes lanzamientos). Sin embargo, debería contar esos 7 dos veces: el bonus y la puntuación normal.
Ahora mismo tenemos todo lo necesario en el código de producción y, en principio, no tenemos que volver atrás. Tan solo introducir los cambios necesarios. Fundamentalmente, nos interesa detectar que se ha realizado el strike.
class BowlingGame
def initialize
@rolls = []
end
def roll(pins_down)
@rolls.push pins_down
end
FRAMES_IN_A_GAME = 10
ALL_PINS_DOWN = 10
def score
score = 0
roll = 0
FRAMES_IN_A_GAME.times do
if @rolls[roll] == 10
frame_score = 10 + @rolls[roll + 1] + @rolls[roll + 2]
roll += 1
else
frame_score = base_frame_score roll
frame_score += @rolls[roll + 2] if spare? frame_score
roll += 2
end
score += frame_score
end
score
end
private
def spare?(frame_score)
frame_score == ALL_PINS_DOWN
end
def base_frame_score(roll)
@rolls[roll] + @rolls[roll + 1]
end
end
Reorganizando el conocimiento del juego
El código de producción que tenemos ahora nos permite pasar los tests y, por tanto, estamos en disposición de arreglar su estructura.
Empecemos haciendo algunas cosas más explícitas sobre el strike:
class BowlingGame
def initialize
@rolls = []
end
def roll(pins_down)
@rolls.push pins_down
end
FRAMES_IN_A_GAME = 10
ALL_PINS_DOWN = 10
def score
score = 0
roll = 0
FRAMES_IN_A_GAME.times do
if strike? roll
frame_score = 10 + base_frame_score(roll + 1)
roll += 1
else
frame_score = base_frame_score roll
frame_score += @rolls[roll + 2] if spare? frame_score
roll += 2
end
score += frame_score
end
score
end
private
def strike?(roll)
@rolls[roll] == ALL_PINS_DOWN
end
def spare?(frame_score)
frame_score == ALL_PINS_DOWN
end
def base_frame_score(roll)
@rolls[roll] + @rolls[roll + 1]
end
end
La estructura de cálculo de la puntuación del frame resulta poco clara, así que vamos a volver atrás y dejarlo también más expresivo:
class BowlingGame
def initialize
@rolls = []
end
def roll(pins_down)
@rolls.push pins_down
end
FRAMES_IN_A_GAME = 10
ALL_PINS_DOWN = 10
def score
score = 0
roll = 0
FRAMES_IN_A_GAME.times do
if strike? roll
frame_score = 10 + base_frame_score(roll + 1)
roll += 1
elsif spare? base_frame_score roll
frame_score = 10 + @rolls[roll + 2]
roll += 2
else
frame_score = base_frame_score roll
roll += 2
end
score += frame_score
end
score
end
private
def strike?(roll)
@rolls[roll] == ALL_PINS_DOWN
end
def spare?(frame_score)
frame_score == ALL_PINS_DOWN
end
def base_frame_score(roll)
@rolls[roll] + @rolls[roll + 1]
end
end
Este refactor deja en evidencia que strike? y spare? tienen una estructura diferente, lo que dificulta su comprensión y su manejo. Cambiamos spare para igualarlos y de paso quitamos también números mágicos.
class BowlingGame
def initialize
@rolls = []
end
def roll(pins_down)
@rolls.push pins_down
end
FRAMES_IN_A_GAME = 10
ALL_PINS_DOWN = 10
def score
score = 0
roll = 0
FRAMES_IN_A_GAME.times do
if strike? roll
frame_score = ALL_PINS_DOWN + base_frame_score(roll + 1)
roll += 1
elsif spare? roll
frame_score = ALL_PINS_DOWN + @rolls[roll + 2]
roll += 2
else
frame_score = base_frame_score roll
roll += 2
end
score += frame_score
end
score
end
private
def strike?(roll)
ALL_PINS_DOWN == @rolls[roll]
end
def spare?(roll)
ALL_PINS_DOWN == base_frame_score(roll)
end
def base_frame_score(roll)
@rolls[roll] + @rolls[roll + 1]
end
end
Ahora podemos extraer métodos que hagan más explícitos los cálculos:
class BowlingGame
def initialize
@rolls = []
end
def roll(pins_down)
@rolls.push pins_down
end
FRAMES_IN_A_GAME = 10
ALL_PINS_DOWN = 10
def score
score = 0
roll = 0
FRAMES_IN_A_GAME.times do
if strike? roll
frame_score = strike_score roll
roll += 1
elsif spare? roll
frame_score = spare_score roll
roll += 2
else
frame_score = base_frame_score roll
roll += 2
end
score += frame_score
end
score
end
private
def spare_score(roll)
ALL_PINS_DOWN + @rolls[roll + 2]
end
def strike_score(roll)
ALL_PINS_DOWN + base_frame_score(roll + 1)
end
def strike?(roll)
ALL_PINS_DOWN == @rolls[roll]
end
def spare?(roll)
ALL_PINS_DOWN == base_frame_score(roll)
end
def base_frame_score(roll)
@rolls[roll] + @rolls[roll + 1]
end
end
La mejor jugadora del mundo
En principio, el desarrollo que tenemos es suficiente. Sin embargo, nos conviene tener algún test que lo certifique. Por ejemplo, este nuevo test corresponde a un juego perfecto: todos los lanzamientos son strikes:
require 'rspec'
require_relative '../src/bowling_game'
RSpec.describe 'A Bowling Game' do
before do
@game = BowlingGame.new
end
it 'should roll a ball knocking down 0 pins' do
@game.roll 0
end
it 'should score a gutter game' do
roll_many 20, 0
expect(@game.score).to eq(0)
end
it 'should score all ones' do
roll_many 20, 1
expect(@game.score).to eq(20)
end
it 'should score an spare' do
roll_spare
@game.roll 3
roll_many 17, 0
expect(@game.score).to eq(16)
end
it 'should score an strike' do
@game.roll(10)
@game.roll(4)
@game.roll(3)
roll_many 17, 0
expect(@game.score).to eq(24)
end
def roll_many(times, pins_down)
times.times do
@game.roll pins_down
end
end
it 'should score perfect game' do
roll_many 12, 10
expect(@game.score).to eq(300)
end
def roll_spare
@game.roll 5
@game.roll 5
end
end
Al ejecutarlo, el test pasa, lo que nos confirma que BowlingGame funciona como esperamos.
Con todos los test pasando y la funcionalidad completamente implementada, podemos hacer evolucionar el código hacia un mejor diseño. En el siguiente ejemplo hemos extraído una clase Rolls que básicamente es un array al que le hemos añadido los métodos de cálculo de puntos que habíamos ido extrayendo:
class Rolls<Array
ALL_PINS_DOWN = 10
def spare_score(roll)
ALL_PINS_DOWN + self[roll + 2]
end
def strike_score(roll)
ALL_PINS_DOWN + base_frame_score(roll + 1)
end
def strike?(roll)
ALL_PINS_DOWN == self[roll]
end
def spare?(roll)
ALL_PINS_DOWN == base_frame_score(roll)
end
def base_frame_score(roll)
self[roll] + self[roll + 1]
end
end
class BowlingGame
def initialize
@rolls = Rolls.new
end
def roll(pins_down)
@rolls.push pins_down
end
FRAMES_IN_A_GAME = 10
def score
score = 0
roll = 0
FRAMES_IN_A_GAME.times do
if @rolls.strike? roll
frame_score = @rolls.strike_score roll
roll += 1
elsif @rolls.spare? roll
frame_score = @rolls.spare_score roll
roll += 2
else
frame_score = @rolls.base_frame_score roll
roll += 2
end
score += frame_score
end
score
end
end
Qué hemos aprendido con esta kata
- El refactor es la etapa del diseño en TDD clásica, es el momento en que una vez que hemos implementado un comportamiento, reorganizamos el código para que se exprese mejor.
- Hay que aprovechar las oportunidades de refactor en cuanto las detectamos.
- Refactorizamos tanto el test como el código de producción.
17 Greeting
Una kata funcional para dominarlas todas
El concepto de función pura me parece muy interesante para Test Driven Development porque nos fuerza a pensar en un comportamiento que debe evolucionar mientas que lo único que podemos saber sobre él desde el punto de vista del test son sus inputs y sus outputs actuales. Esto es común a todo desarrollo en TDD clásico, dado que se basa en tests de caja negra. O sea, no tenemos en cuenta cómo es la implementación de la unidad que estamos desarrollando, sino cómo interactuamos con ella a través de su interfaz pública.
Por eso te la propongo como ejercicio final de esta serie, porque ayuda a ejercitar todas las cosas que hemos aprendido con las anteriores, añadiendo una restricción extra para forzarnos a no utilizar los recursos de que dispondríamos en orientación a objetos, como podría ser mantener un estado o extrayendo comportamiento a dependencias.
Además, dado que los requisitos cambian en cada iteración, nos fuerza a hacer refactors constantemente para poder introducir los cambios necesarios de comportamiento.
Historia
Esta kata no es muy conocida. La he encontrado en TestDouble, donde se menciona como autor a Nick Gauthier.
Enunciado
El enunciado de esta kata es muy simple. Se trata de crear una función pura greet() que devuelva un string con un saludo. Se le pasa como parámetro el nombre de la persona a la que saludar.
Seguidamente, se van añadiendo requisitos que nos obligarán a extender el algoritmo para darles soporte únicamente a través de la entrada y salida de esta función. Para cada requisito se nos proporciona un ejemplo. Son los siguientes:
| Requisitos | input | output |
|---|---|---|
| 1. Interpolar nombre en un saludo sencillo | “Bob” | Hello, Bob. |
| 2. Si no se pasa nombre, retornar alguna fórmula genérica | null | Hello, my friend. |
| 3. Si nos gritan, contestar con un grito | “JERRY” | HELLO, JERRY! |
| 4. Manejar dos nombres | “Jill”, “Jane” | Hello, Jill and Jane. |
| 5. Manejar cualquier número de nombras, con coma estilo Oxford | “Amy”, “Brian”, “Charlotte” | Hello, Amy, Brian, and Charlotte. |
| 6. Permitir mezclar nombres normales y gritados, pero separar las respuestas. | “Amy”, “BRIAN”, “Charlotte” | Hello, Amy and Charlotte. AND HELLO BRIAN! |
| 7. Si un nombre contiene una coma, separarlo | “Bob”, “Charlie, Dianne” | Hello, Bob, Charlie, and Dianne. |
| 8. Permitir escapar las comas de #7 | “Bob”, “"Charlie, Dianne" | Hello, Bob and Charlie, Dianne. |
Orientaciones para resolverla
Parte del interés de esta kata reside en trabajar con un requerimiento cada vez, por lo que es importante no adelantarse e ir uno por uno.
La dificultad es resolverla sin crear unidades extra, solo a través de la interfaz greet().Cada uno de los requerimientos nos permite construir un test que nos fuerce a extender el comportamiento, aunque podríamos crear cuantos tests nos parezcan necesarios.
Por otro lado, es muy importante el paso atrás del que hablábamos en la kata Bowling. Al resolver un requisito, haciendo pasar el test correspondiente, nos veremos en la necesidad de preparar el terreno para poder implementar el siguiente, manteniendo todos los tests actuales pasando.
En resumen:
- Céntrate en un requisito cada vez, en el orden propuesto.
- Una vez logrado, refactoriza para facilitar la consecución del siguiente requisito: haz que el cambio sea fácil (eso puede ser difícil) y luego haz el cambio fácil, como diría Kent Beck.
Enlaces de interés sobre la kata Greetings
- Greetings Kata1
18 Resolviendo la kata Greetings
Enunciado de la kata
El enunciado de esta kata es muy simple. Se trata de crear una función pura greet() que devuelva un string con un saludo. Se le pasa como parámetro el nombre de la persona a la que saludar.
Seguidamente, se van añadiendo requisitos que nos obligarán a extender el algoritmo para darles soporte únicamente a través de la entrada y salida de esta función. Para cada requisito se nos proporciona un ejemplo. Son los siguientes:
| Requisitos | input | output |
|---|---|---|
| 1. Interpolar nombre en un saludo sencillo | “Bob” | Hello, Bob. |
| 2. Si no se pasa nombre, retornar alguna fórmula genérica | null | Hello, my friend. |
| 3. Si nos gritan, contestar con un grito | “JERRY” | HELLO, JERRY! |
| 4. Manejar dos nombres | “Jill”, “Jane” | Hello, Jill and Jane. |
| 5. Manejar cualquier número de nombras, con coma estilo Oxford | “Amy”, “Brian”, “Charlotte” | Hello, Amy, Brian, and Charlotte. |
| 6. Permitir mezclar nombres normales y gritados, pero separar las respuestas. | “Amy”, “BRIAN”, “Charlotte” | Hello, Amy and Charlotte. AND HELLO BRIAN! |
| 7. Si un nombre contiene una coma, separarlo | “Bob”, “Charlie, Dianne” | Hello, Bob, Charlie, and Dianne. |
| 8. Permitir escapar las comas de #7 | “Bob”, “\“Charlie, Dianne\”” | Hello, Bob and Charlie, Dianne. |
Lenguaje y enfoque
Esta kata la vamos a resolver en Scala con el framework FunSite. La escribiremos usando un enfoque funcional.
Saludo básico
La forma en que se presenta esta kata nos proporciona prácticamente todos los casos de test que necesitamos. A estas alturas creo que podemos dar un salto relativamente grande para empezar.
Este es nuestro primer test en el que suponemos que la función será un método de la clase Greetings en el package greetings.
import greetings.Greetings
import org.scalatest.FunSuite
class GreetingTest extends FunSuite {
test("Require the function") {
assert(Greetings.greet("Bob") === "Hello, Bob.")
}
}
En cualquier caso, al usar lenguajes que son muy estrictos en el tipado muchas veces no podríamos empezar por tests más pequeños, pues el propio compilador nos obligaría a introducir más código. Pero, por otra parte, el tipado estricto nos permite ignorar con seguridad esos mismos tests. De hecho, puedes considerar que el sistema de tipado estricto es, en cierto modo, un sistema de testing.
El test fallará, como era de esperar. En este caso crearemos el código mínimo necesario para hacerlo pasar de una sola vez:
package greetings
object Greetings {
def greet(value: String): String = {
"Hello, Bob."
}
}
Scala no nos permite definir la función sin argumentos y usarla pasándole alguno, por lo que nos vemos obligadas a incorporarlo en la signatura. Por lo demás, devolvemos el string esperado por el test para que se ponga en verde.
Saludo genérico
El segundo caso es gestionar la situación en que no nos pasan ningún nombre, por lo que el saludo deberá ser genérico.
import greetings.Greetings
import org.scalatest.FunSuite
class GreetingTest extends FunSuite {
test("Require the function") {
assert(Greetings.greet("Bob") === "Hello, Bob.")
}
test("Act when name is null") {
assert(Greetings.greet() === "Hello, my friend.")
}
}
Lo primero que observamos es que el test fallará debido a que greet espera un parámetro que no le pasamos. Esto nos está indicando que debería ser opcional.
Nuestra primera intención sería corregir eso y permitir que se pueda pasar un parámetro opcional. Pero hay que tener en cuenta que si lo hacemos, el test seguirá fallando.
Por tanto, lo que vamos a hacer es descartar de momento este último test y refactorizar el código que tenemos mientras mantenemos el primer test pasando.
Usar el parámetro
Desactivamos el test:
import org.scalatest.FunSuite
class GreetingTest extends FunSuite {
test("Require the function") {
assert(Greetings.greet("Bob") === "Hello, Bob.")
}
// test("Act when name is null") {
// assert(Greetings.greet() === "Hello, my friend.")
// }
}
Y hacemos el refactor. En Scala es posible poner valores por defecto eliminando la necesidad de pasar un parámetro.
package greetings
object Greetings {
def greet(name: String = "Bob"): String = {
"Hello, Bob."
}
}
Nos faltaría hacer un uso efectivo del parámetro, en este caso mediante una interpolación.
package greetings
object Greetings {
def greet(name: String = "Bob"): String = {
s"Hello, $name."
}
}
Un saludo genérico
Volvemos a activar el segundo test para poder implementar el requisito número dos, que consiste en permitir un saludo genérico si no se pasan valores:
import greetings.Greetings
import org.scalatest.FunSuite
class GreetingTest extends FunSuite {
test("Require the function") {
assert(Greetings.greet("Bob") === "Hello, Bob.")
}
test("Act when name is null") {
assert(Greetings.greet() === "Hello, my friend.")
}
}
El test no pasará, pero el cambio necesario para que sí lo haga es muy sencillo:
package greetings
object Greetings {
def greet(name: String = "my friend"): String = {
s"Hello, $name."
}
}
Es muy importante fijarse en este detalle. El cambio que hemos realizado ha sido muy pequeño, pero para que pudiese ser pequeño hemos hecho antes el refactor protegiéndonos con el test anterior. Es muy habitual intentar hacer ese refactor con el nuevo test fallando, pero esa es una mala práctica porque si refactorizamos mientras el test falla no podemos tener seguridad sobre lo que estamos haciendo.
Responder a gritos
Este tercer test introduce el nuevo requisito de responder de manera diferente a los nombres expresados por completo en mayúsculas:
import greetings.Greetings
import org.scalatest.FunSuite
class GreetingTest extends FunSuite {
test("Require the function") {
assert(Greetings.greet("Bob") === "Hello, Bob.")
}
test("Act when name is null") {
assert(Greetings.greet() === "Hello, my friend.")
}
test("Should manage shout") {
assert(Greetings.greet("JERRY") === "HELLO, JERRY!")
}
}
Nos aseguramos de que el test falla por el motivo correcto antes de pasar a escribir el código de producción. Este es un enfoque posible:
package greetings
object Greetings {
def greet(name: String = "my friend"): String = {
if (name.toUpperCase == name) {
return s"HELLO, $name!"
}
s"Hello, $name."
}
}
Llegadas a este punto vamos a ver qué oportunidades tenemos de hacer refactor. Esto nos lleva a esta solución tan sencilla:
package greetings
object Greetings {
def greet(name: String = "my friend"): String = {
if (name.toUpperCase() == name) s"HELLO, $name!" else s"Hello, $name."
}
}
De momento no hay mucho más que podamos hacer con la información que tenemos hasta ahora por lo que vamos a examinar el siguiente requisito.
Poder saludar a dos personas
El requisito cuatro nos pide manejar dos nombres, lo que cambia ligeramente la cadena de saludo. Por supuesto, nos proporciona un ejemplo con el que hacer un test.
import greetings.Greetings
import org.scalatest.FunSuite
class GreetingTest extends FunSuite {
test("Require the function") {
assert(Greetings.greet("Bob") === "Hello, Bob.")
}
test("Act when name is null") {
assert(Greetings.greet() === "Hello, my friend.")
}
test("Should manage shout") {
assert(Greetings.greet("JERRY") === "HELLO, JERRY!")
}
test("Should manage two names") {
assert(Greetings.greet("Jill", "Jane") === "Hello, Jill and Jane.")
}
}
Es posible que al escribir el test el propio IDE te haya advertido de que no es correcto pasar dos argumentos cuando la signatura de la función solo permite uno, que además es opcional. Si no es así, la ejecución del test fallará al no poder compilar.
Como ya hemos visto en otras ocasiones la mejor forma de afrontar esto es retroceder al test anterior y hacer un refactor con el que prevenir el problema. Así que anulamos temporalmente el test que acabamos de introducir.
Preparándose para varios nombres
import greetings.Greetings
import org.scalatest.FunSuite
class GreetingTest extends FunSuite {
test("Require the function") {
assert(Greetings.greet("Bob") === "Hello, Bob.")
}
test("Act when name is null") {
assert(Greetings.greet() === "Hello, my friend.")
}
test("Should manage shout") {
assert(Greetings.greet("JERRY") === "HELLO, JERRY!")
}
// test("Should manage two names") {
// assert(Greetings.greet("Jill", "Jane") === "Hello, Jill and Jane.")
// }
}
Y refactorizamos a una implementación que nos permita introducir dos parámetros. La forma más fácil de hacerlo es usando splat parameters. Sin embargo, eso nos forzará a cambiar el algoritmo, ya que los parámetros se presentarán como un objeto Seq de String. Además de eso, cambiamos el nombre del parámetro.
package greetings
object Greetings {
def greet(person: String*): String = {
if (person.isEmpty) return "Hello, my friend."
val name = person.last
if (name.toUpperCase() == name) s"HELLO, $name!" else s"Hello, $name."
}
}
Esta es una reimplementación ingenua, suficiente para permitirnos pasar el test, pero que podríamos desarrollar a un estilo más propio del lenguaje. Una de las mejores cosas que nos proporciona TDD es justamente esta facilidad para que podamos bosquejar implementaciones funcionales, aunque sean toscas, pero que nos ayudan a reflexionar sobre el problema y experimentar soluciones alternativas.
Para mejorarla un poco vamos primero a extraer la condición del if a una función anidada, con lo que no solo es más expresiva, sino también más fácil de reutilizar llegado el caso:
package greetings
object Greetings {
def greet(person: String*): String = {
def isShouting(name: String): Boolean = {
name.toUpperCase() == name
}
if (person.isEmpty) return "Hello, my friend."
val name = person.last
if (isShouting(name)) s"HELLO, $name!" else s"Hello, $name."
}
}
La cuestión ahora, ¿nos conviene retomar el cuarto test o deberíamos seguir con el refactor para dar soporte a los cambios que necesitamos?
Un refactor antes de seguir
El último refactor nos ha permitido dar soporte a una lista de nombres, pero necesitaríamos cambiar el enfoque para poder manejar listas de nombres gritando.
Hasta ahora distinguimos si hay que gritar cuando montamos el saludo. Sin embargo, es posible que nos interese separar primero los nombres en función si han de ser gritados o no.
Así que lo que hacemos es repartir la lista de nombres en dos, según si son gritados o no, y adaptamos el resto del código a eso.
package greetings
object Greetings {
def greet(person: String*): String = {
def isShouting(name: String): Boolean = {
name.toUpperCase() == name
}
if (person.isEmpty) return "Hello, my friend."
val (shout, normal) = person.partition(isShouting)
if (normal.nonEmpty)
s"Hello, ${normal.last}."
else if (shout.nonEmpty)
s"HELLO, ${shout.last}!"
else ""
}
}
Con esto deberíamos estar mejor preparadas para afrontar el cuarto test, así que lo reactivamos.
Reintroduciendo un test
Al volver a activar el cuarto test ocurre lo que podíamos predecir: se hará el saludo a una sola persona, que será precisamente la última de las dos.
import greetings.Greetings
import org.scalatest.FunSuite
class GreetingTest extends FunSuite {
test("Require the function") {
assert(Greetings.greet("Bob") === "Hello, Bob.")
}
test("Act when name is null") {
assert(Greetings.greet() === "Hello, my friend.")
}
test("Should manage shout") {
assert(Greetings.greet("JERRY") === "HELLO, JERRY!")
}
test("Should manage two names") {
assert(Greetings.greet("Jill", "Jane") === "Hello, Jill and Jane.")
}
}
El resultado es:
Es decir, el test falla por la razón correcta, indicándonos que tenemos que introducir un cambio que se ocupe de procesar la lista de nombres y concatenarla. Gracias a los refactors anteriores es fácil de introducir:
package greetings
object Greetings {
def greet(person: String*): String = {
def isShouting(name: String): Boolean = {
name.toUpperCase() == name
}
if (person.isEmpty) return "Hello, my friend."
val (shout, normal) = person.partition(isShouting)
if (normal.nonEmpty)
s"Hello, ${normal.mkString(" and ")}."
else if (shout.nonEmpty)
s"HELLO, ${shout.last}!"
else ""
}
}
Es importante fijarse en que en este punto no intentamos adelantarnos a los próximos requisitos, sino que resolvemos el problema actual. Solo cuando introduzcamos el próximo test y con ello aprendamos cosas nuevas sobre el comportamiento que estamos implementando en la función nos plantearemos volver atrás a refactorizar los cambios previos que podamos necesitar.
Manejar un número indeterminado de nombres
El quinto requisito consiste en manejar un número indeterminado de nombres, con un pequeño cambio en el formato del saludo. Introducimos un nuevo test que lo especifica:
import greetings.Greetings
import org.scalatest.FunSuite
class GreetingTest extends FunSuite {
test("Require the function") {
assert(Greetings.greet("Bob") === "Hello, Bob.")
}
test("Act when name is null") {
assert(Greetings.greet() === "Hello, my friend.")
}
test("Should manage shout") {
assert(Greetings.greet("JERRY") === "HELLO, JERRY!")
}
test("Should manage two names") {
assert(Greetings.greet("Jill", "Jane") === "Hello, Jill and Jane.")
}
test("Should manage several names") {
assert(Greetings.greet("Amy", "Brian", "Charlotte") === "Hello, Amy, Brian, and Charl\
otte.")
}
}
El resultado del test es:
Expected :"Hello, Amy[, Brian,] and Charlotte."
Actual :"Hello, Amy[ and Brian] and Charlotte."
Podemos empezar por el siguiente cambio:
package greetings
object Greetings {
def greet(person: String*): String = {
def isShouting(name: String): Boolean = {
name.toUpperCase() == name
}
if (person.isEmpty) return "Hello, my friend."
val (shout, normal) = person.partition(isShouting)
if (normal.nonEmpty)
s"Hello, ${normal.mkString(", ")}."
else if (shout.nonEmpty)
s"HELLO, ${shout.last}!"
else ""
}
}
Esto rompe el test anterior y tampoco pasa el nuevo, que nos indica que el último elemento de la lista requiere un trato especial:
Hagamos eso literalmente, es decir: separemos el último elemento:
package greetings
object Greetings {
def greet(person: String*): String = {
def isShouting(name: String): Boolean = {
name.toUpperCase() == name
}
if (person.isEmpty) return "Hello, my friend."
val (shout, normal) = person.partition(isShouting)
if (normal.nonEmpty)
s"Hello, ${normal.init.mkString(", ")}, and ${normal.last}."
else if (shout.nonEmpty)
s"HELLO, ${shout.last}!"
else ""
}
}
Sin embargo, este cambio hace pasar el último test, a la vez que provoca que fallen el anterior y el primero. El problema es que en el caso del saludo normal y el del saludo a dos personas no pueden seguir el mismo patrón. Estamos destapando un agujero para tapar otro.
Puesto que estamos haciendo fallar tests que ya estaban pasando lo mejor es que volvamos al punto del código en que los cuatro tests anteriores se cumplían.
package greetings
object Greetings {
def greet(person: String*): String = {
def isShouting(name: String): Boolean = {
name.toUpperCase() == name
}
if (person.isEmpty) return "Hello, my friend."
val (shout, normal) = person.partition(isShouting)
if (normal.nonEmpty)
s"Hello, ${normal.mkString(" and ")}."
else if (shout.nonEmpty)
s"HELLO, ${shout.last}!"
else ""
}
}
Lo que nos indica este recorrido de ida y vuelta es que hay dos tipos de casos que tienen tratamiento diferente.
- Listas de 2 o menos nombres.
- Listas de más de 2 nombres.
Lo más sencillo es reconocer eso y abrazarlo en el propio código:
package greetings
object Greetings {
def greet(person: String*): String = {
def isShouting(name: String): Boolean = {
name.toUpperCase() == name
}
if (person.isEmpty) return "Hello, my friend."
val (shout, normal) = person.partition(isShouting)
if (normal.nonEmpty)
if (normal.length <= 2)
s"Hello, ${normal.mkString(" and ")}."
else
s"Hello, ${normal.init.mkString(", ")}, and ${normal.last}."
else if (shout.nonEmpty)
s"HELLO, ${shout.last}!"
else ""
}
}
De nuevo, una implementación tosca e ingenua nos permite hacer pasar todos los tests, acudiendo a un mecanismo tan simple como es el de posponer la generalización. Es ahora, al haber logrado el comportamiento deseado cuando podemos intentar a analizar el problema y buscar un algoritmo más general.
Como queremos centrarnos en la parte del algoritmo que concatena los nombres dentro del saludo vamos a hacer primero el siguiente refactor, extrayendo a una función inline el bloque de código que nos interesa:
package greetings
object Greetings {
def greet(person: String*): String = {
def isShouting(name: String): Boolean = {
name.toUpperCase() == name
}
if (person.isEmpty) return "Hello, my friend."
val (shout, normal) = person.partition(isShouting)
def concatenate = {
if (normal.length <= 2)
s"${normal.mkString(" and ")}."
else
s"${normal.init.mkString(", ")}, and ${normal.last}."
}
if (normal.nonEmpty)
s"Hello, ${concatenate}"
else if (shout.nonEmpty)
s"HELLO, ${shout.last}!"
else ""
}
}
Lo más interesante es haber aislado específicamente la concatenación de nombres. Vamos a hacer un par de cambios más. Ahora mismo actuamos directamente sobre la secuencia normal que está en el ámbito de la función greet y, por tanto, es global dentro de la función concatenate:
package greetings
object Greetings {
def greet(person: String*): String = {
def isShouting(name: String): Boolean = {
name.toUpperCase() == name
}
if (person.isEmpty) return "Hello, my friend."
val (shout, normal) = person.partition(isShouting)
def concatenate(names: Seq[String]) = {
if (names.length <= 2)
s"${names.mkString(" and ")}"
else
s"${names.init.mkString(", ")}, and ${names.last}"
}
if (normal.nonEmpty)
s"Hello, ${concatenate(normal)}."
else if (shout.nonEmpty)
s"HELLO, ${shout.last}!"
else ""
}
}
Tras habernos asegurado de que los tests siguen pasando, vamos a hacer explícitos los diferentes casos que se tratan. Ahora mismo, la lista de un solo nombre queda cubierta de forma implícita por el caso de dos nombres. Nuestro objetivo es tratar de entender mejor las regularidades en los tres supuestos:
package greetings
object Greetings {
def greet(person: String*): String = {
def isShouting(name: String): Boolean = {
name.toUpperCase() == name
}
if (person.isEmpty) return "Hello, my friend."
val (shout, normal) = person.partition(isShouting)
def concatenate(names: Seq[String]) = {
if (names.length == 1)
s"${names.last}"
else if (names.length == 2)
s"${names.mkString(" and ")}"
else
s"${names.init.mkString(", ")}, and ${names.last}"
}
if (normal.nonEmpty)
s"Hello, ${concatenate(normal)}."
else if (shout.nonEmpty)
s"HELLO, ${shout.last}!"
else ""
}
}
Demos un pequeño paso más en el caso de dos nombres:
package greetings
object Greetings {
def greet(person: String*): String = {
def isShouting(name: String): Boolean = {
name.toUpperCase() == name
}
if (person.isEmpty) return "Hello, my friend."
val (shout, normal) = person.partition(isShouting)
def concatenate(names: Seq[String]) = {
if (names.length == 1)
s"${names.last}"
else if (names.length == 2)
s"${names.head} and ${names.last}"
else
s"${names.init.mkString(", ")}, and ${names.last}"
}
if (normal.nonEmpty)
s"Hello, ${concatenate(normal)}."
else if (shout.nonEmpty)
s"HELLO, ${shout.last}!"
else ""
}
}
En Scala esto se puede expresar de manera más sucinta usando match... case:
package greetings
object Greetings {
def greet(person: String*): String = {
def isShouting(name: String): Boolean = {
name.toUpperCase() == name
}
def concatenate(names: Seq[String]) = {
names.length match {
case 1 => s"${names.last}"
case 2 => s"${names.head} and ${names.last}"
case _ => s"${names.init.mkString(", ")}, and ${names.last}"
}
}
if (person.isEmpty) return "Hello, my friend."
val (shout, normal) = person.partition(isShouting)
if (normal.nonEmpty)
s"Hello, ${concatenate(normal)}."
else if (shout.nonEmpty)
s"HELLO, ${shout.last}!"
else ""
}
}
Y un poquito más:
package greetings
object Greetings {
def greet(person: String*): String = {
def isShouting(name: String): Boolean = {
name.toUpperCase() == name
}
def concatenate(names: Seq[String]) = {
s"${names.length match {
case 1 => ""
case 2 => s"${names.head} and "
case _ => s"${names.init.mkString(", ")}, and "
}}${names.last}"
}
if (person.isEmpty) return "Hello, my friend."
val (shout, normal) = person.partition(isShouting)
if (normal.nonEmpty)
s"Hello, ${concatenate(normal)}."
else if (shout.nonEmpty)
s"HELLO, ${shout.last}!"
else ""
}
}
Gritar a los gritones, pero solo a ellos
En el test anterior nos hemos enfrentado al problema de generalizar el algoritmo para cualquier número de casos y hacerlo más expresivo sin romper la funcionalidad conseguida hasta aquel momento. Toca introducir un nuevo requisito mediante un nuevo test:
import greetings.Greetings
import org.scalatest.FunSuite
class GreetingTest extends FunSuite {
test("Require the function") {
assert(Greetings.greet("Bob") === "Hello, Bob.")
}
test("Act when name is null") {
assert(Greetings.greet() === "Hello, my friend.")
}
test("Should manage shout") {
assert(Greetings.greet("JERRY") === "HELLO, JERRY!")
}
test("Should manage two names") {
assert(Greetings.greet("Jill", "Jane") === "Hello, Jill and Jane.")
}
test("Should manage several names") {
assert(Greetings.greet("Amy", "Brian", "Charlotte") === "Hello, Amy, Brian, and Charl\
otte.")
}
test("Should shout to shouters") {
assert(Greetings.greet("Amy", "BRIAN", "Charlotte") === "Hello, Amy and Charlotte. AN\
D HELLO, BRIAN!")
}
}
Este test falla, como cabría esperar. Es interesante que ya nos habíamos preparado para este caso y tratábamos los saludos “gritones” de forma separada. Por lo que deducimos del ejemplo, podríamos aplicar el mismo tratamiento que a los “no gritones”, teniendo en cuenta que pueden aparecer los dos casos simultáneamente. Después de un par de intentos, llegamos a esto:
package greetings
object Greetings {
def greet(person: String*): String = {
def isShouting(name: String): Boolean = {
name.toUpperCase() == name
}
def concatenate(names: Seq[String]) = {
s"${names.length match {
case 1 => ""
case 2 => s"${names.head} and "
case _ => s"${names.init.mkString(", ")}, and "
}}${names.last}"
}
if (person.isEmpty) return "Hello, my friend."
val (shout, normal) = person.partition(isShouting)
s"${if (normal.nonEmpty) s"Hello, ${concatenate(normal)}." else ""}${if (shout.nonEmp\
ty) s"${if (normal.nonEmpty) " AND " else ""}HELLO, ${concatenate(shout)}!" else ""}"
}
}
Separar nombres que contienen comas
El siguiente requisito que se nos pide es separar los nombres que contienen comas. Para hacernos una idea esto viene siendo como permitir pasar los nombres con un número indeterminado de strings como en forma de un único string conteniendo varios nombres. Esto no altera realmente el modo en que generamos el saludo, sino más bien al modo en que preparamos los datos recibidos.
Nos toca, por tanto, añadir un test que ejemplifique el nuevo requisito:
import greetings.Greetings
import org.scalatest.FunSuite
class GreetingTest extends FunSuite {
test("Require the function") {
assert(Greetings.greet("Bob") === "Hello, Bob.")
}
test("Act when name is null") {
assert(Greetings.greet() === "Hello, my friend.")
}
test("Should manage shout") {
assert(Greetings.greet("JERRY") === "HELLO, JERRY!")
}
test("Should manage two names") {
assert(Greetings.greet("Jill", "Jane") === "Hello, Jill and Jane.")
}
test("Should manage several names") {
assert(Greetings.greet("Amy", "Brian", "Charlotte") === "Hello, Amy, Brian, and Charl\
otte.")
}
test("Should shout to shouters") {
assert(Greetings.greet("Amy", "BRIAN", "Charlotte") === "Hello, Amy and Charlotte. AN\
D HELLO, BRIAN!")
}
test("Should separate names with comma") {
assert(Greetings.greet("Bob", "Charlie, Dianne") === "Hello, Bob, Charlie, and Dianne\
.")
}
}
Ejecutamos el test para comprobar que no pasa y nos planteamos cómo resolver este nuevo caso.
En principio, podríamos recorrer la lista de personas y hacer un split de cada una de ellas por la coma. Como esto generará una colección de colecciones, la aplanamos. En Scala hay métodos para todo eso:
package greetings
object Greetings {
def greet(person: String*): String = {
def isShouting(name: String): Boolean = {
name.toUpperCase() == name
}
def concatenate(names: Seq[String]) = {
s"${names.length match {
case 1 => ""
case 2 => s"${names.head} and "
case _ => s"${names.init.mkString(", ")}, and "
}}${names.last}"
}
if (person.isEmpty) return "Hello, my friend."
val personsList = person.flatMap(name => name.split(",").map(_.trim))
val (shout, normal) = personsList.partition(isShouting)
s"${if (normal.nonEmpty) s"Hello, ${concatenate(normal)}." else ""}${if (shout.nonEmp\
ty) s"${if (normal.nonEmpty) " AND " else ""}HELLO, ${concatenate(shout)}!" else ""}"
}
}
Y he aquí que el test pasa sin problemas.
Una vez que hemos visto que la solución funciona, refactorizamos un poco el código:
package greetings
object Greetings {
def greet(person: String*): String = {
def isShouting(name: String): Boolean = {
name.toUpperCase() == name
}
def concatenate(names: Seq[String]) = {
s"${names.length match {
case 1 => ""
case 2 => s"${names.head} and "
case _ => s"${names.init.mkString(", ")}, and "
}}${names.last}"
}
if (person.isEmpty) return "Hello, my friend."
val (shout, normal) = person
.flatMap(_.split(",").map(_.trim))
.partition(isShouting)
s"${if (normal.nonEmpty) s"Hello, ${concatenate(normal)}." else ""}${if (shout.nonEmp\
ty) s"${if (normal.nonEmpty) " AND " else ""}HELLO, ${concatenate(shout)}!" else ""}"
}
}
Escapar comas
El octavo requisito consiste en permitir que se evite el comportamiento anterior si la entrada de texto está escapada. Veamos el caso en forma de test:
import greetings.Greetings
import org.scalatest.FunSuite
class GreetingTest extends FunSuite {
test("Require the function") {
assert(Greetings.greet("Bob") === "Hello, Bob.")
}
test("Act when name is null") {
assert(Greetings.greet() === "Hello, my friend.")
}
test("Should manage shout") {
assert(Greetings.greet("JERRY") === "HELLO, JERRY!")
}
test("Should manage two names") {
assert(Greetings.greet("Jill", "Jane") === "Hello, Jill and Jane.")
}
test("Should manage several names") {
assert(Greetings.greet("Amy", "Brian", "Charlotte") === "Hello, Amy, Brian, and Charl\
otte.")
}
test("Should shout to shouters") {
assert(Greetings.greet("Amy", "BRIAN", "Charlotte") === "Hello, Amy and Charlotte. AN\
D HELLO, BRIAN!")
}
test("Should separate names with comma") {
assert(Greetings.greet("Bob", "Charlie, Dianne") === "Hello, Bob, Charlie, and Dianne\
.")
}
test("Should not separate names with comma if escaped") {
assert(Greetings.greet("Bob", "\"Charlie, Dianne\"") === "Hello, Bob and Charlie, Dia\
nne.")
}
}
De nuevo, esto afecta a la preparación de los datos antes de montar el saludo. La solución que se nos ocurre es detectar primero la situación de que la cadena viene escapada y reemplazar la coma por un carácter arbitrario antes de hacer el split. Una vez hecho, restauramos la coma original.
En este caso, lo hacemos mediante una expresión regular, reemplazando por el símbolo # y restituyéndolo después.
package greetings
object Greetings {
def greet(person: String*): String = {
def isShouting(name: String): Boolean = {
name.toUpperCase() == name
}
def concatenate(names: Seq[String]) = {
s"${names.length match {
case 1 => ""
case 2 => s"${names.head} and "
case _ => s"${names.init.mkString(", ")}, and "
}}${names.last}"
}
if (person.isEmpty) return "Hello, my friend."
val escaped = "^\"([^,]+),(.+)\"$".r
val personsList = person
.map(input => escaped.replaceAllIn(input, "$1#$2"))
.flatMap(_.split(",").map(_.trim))
.map(_.replace("#", ","))
val (shout, normal) = personsList.partition(isShouting)
s"${if (normal.nonEmpty) s"Hello, ${concatenate(normal)}." else ""}${if (shout.nonEmp\
ty) s"${if (normal.nonEmpty) " AND " else ""}HELLO, ${concatenate(shout)}!" else ""}"
}
}
Con esto completamos todos los requisitos. Podemos hacer un pequeño refactor:
package greetings
object Greetings {
def greet(person: String*): String = {
def isShouting(name: String): Boolean = {
name.toUpperCase() == name
}
def concatenate(names: Seq[String]) = {
s"${names.length match {
case 1 => ""
case 2 => s"${names.head} and "
case _ => s"${names.init.mkString(", ")}, and "
}}${names.last}"
}
if (person.isEmpty) return "Hello, my friend."
val escaped = "^\"([^,]+),(.+)\"$".r
val (shout, normal) = person
.map(input => escaped.replaceAllIn(input, "$1#$2"))
.flatMap(_.split(",").map(_.trim))
.map(_.replace("#", ","))
.partition(isShouting)
s"${if (normal.nonEmpty) s"Hello, ${concatenate(normal)}." else ""}${if (shout.nonEmp\
ty) s"${if (normal.nonEmpty) " AND " else ""}HELLO, ${concatenate(shout)}!" else ""}"
}
}
Una de las cosas que llama la atención en esta kata es que el enfoque funcional hace que cambios de comportamiento relativamente grandes se puedan conseguir mediante cambios comparativamente pequeños en el código de producción.
Qué hemos aprendido con esta kata
- En esta kata hemos aprendido a posponer la generalización hasta tener más información sobre el algoritmo que estamos desarrollando
- Hemos aplicado las técnicas aprendidas en katas anteriores
- Hemos comprobado que un sistema de tipos estrictos nos permite ahorrarnos algunos tests
Outside-in TDD
La metodología outside-in TDD intenta potenciar el carácter comunicativo de la programación orientada a objetos, poniendo énfasis en los mensajes entre objetos colaboradores y prestando atención al diseño del sistema.
Para ello, comienza desde el exterior del mismo, creando un test de aceptación que describe lo que se va a desarrollar y estableciendo un doble ciclo en el que vamos alternando entre el nivel de aceptación y el unitario. En el nivel unitario se diseña la colaboración entre objetos, decidiendo la atribución de responsabilidades en cada fase de la iteración. Para ello, se usan dobles de test, mocks, fijando ciertas expectativas sobre ellos.
El autor más destacado en este enfoque es Sandro Mancuso, que la introduce en varias publicaciones y conferencias1.
Outside-in TDD no contradice el enfoque clásico, pero propone una metodología más aplicable al desarrollo de software en condiciones reales y le da contexto, poniendo énfasis en las necesidades de diseño.
Por otro lado, es posible realizar un outside-in siguiendo las reglas clásicas, buscando el diseño durante las fases de refactor. No es habitual encontrar ejemplos. Uno de ellos es este del propio Sandro Mancuso con la Rover kata2, aunque no se trata de una aplicación completa.
19 Enfoques en TDD
La metodología Test Driven Development se basa en un conjunto relativamente reducido de reglas o principios. Pero un aspecto que no se define explícitamente es el modo en que esto puede aplicarse a diferentes situaciones de desarrollo.
Así, por ejemplo, es muy evidente la forma en que podemos dirigir mediante tests el desarrollo de una clase o una función. Una buena parte de las katas de este libro y, en general, las katas de iniciación a TDD, hacen exactamente eso. El problema viene con el salto al mundo real, un momento en el que muchas personas no consiguen encontrar rendimiento a la introducción de TDD en su proceso de desarrollo.
La cuestión clave es que una historia de usuario no consiste normalmente en desarrollar una clase e integrarla en el código existente, sino que lo normal es desarrollar features que implican un conjunto de componentes, incluyendo algún tipo de interfaz al mundo exterior (UI, API), así como casos de uso, entidades y servicios de dominio, entre otros.
Esto genera una pregunta muy simple: ¿por dónde empezar?
Las diferentes formas de responder a esta pregunta podrían clasificarse en tres, no tan separadas entre sí como se podría pensar. De hecho, no son excluyentes.
TDD Clásico o Detroit School
Este enfoque recibe ambos nombres debido a ser, por así decir, el modelo original de TDD propuesto por los fundadores del paradigma Extreme Programming (Kent Beck, Ward Cunningham, Ron Jeffries), surgido en el contexto del proyecto Chrysler Comprehensive Compensation System en Detroit.
Habitualmente desde este enfoque un proyecto complejo se abordaría definiendo las unidades de software necesarias y creando cada una de ellas mediante un proceso estándar de TDD.
Por poner un ejemplo muy simplista. Imagina que nuestra tarea es diseñar un endpoint de una API.
Esto supondría crear, al menos, un controlador, un caso de uso, una o dos entidades y sus correspondientes repositorios.
En este enfoque clásico de TDD, una vez determinados los componentes necesarios iríamos creándolos en orden de dependencia, empezando por las entidades de dominio y avanzando hacia afuera. Es decir, si para construir una unidad, necesito usar otra unidad, construiré primero esta última. Puesto que las dependencias apuntan hacia el dominio, lo adecuado sería comenzar resolviendo el problema en la capa de dominio e ir “saliendo” hacia las capas más externas.
Algunos rasgos que caracterizan este modelo son:
- Se testea contra las API públicas de las unidades, usando black box testing (test de caja negra). Esto implica que en el test no hacemos asunciones sobre el modo en que está implementada la unidad.
- Hincapié especialmente en la fase de refactor, que es la fase en la que se introduce el diseño. Se debe refactorizar en cuanto tenemos tests en verde y por pequeña que parezca la oportunidad.
- Minimiza el uso de dobles de test, limitándolos fundamentalmente a las fronteras de arquitectura.
- Desarrollo desde dentro hacia fuera. Prioriza la identificación y desarrollo de la lógica de dominio.
- Se centra en el estado y outcomes de los objetos y sus métodos.
Este enfoque aporta los beneficios esperables de TDD:
- Trabajar en incrementos pequeños y manejables.
- Generar una red de seguridad con abundantes tests de regresión.
- Posibilidad de refactorizar la implementación con gran seguridad.
En el lado de los inconvenientes habría que señalar:
- Los tests no ayudan realmente a dirigir el diseño, sino la implementación de las unidades. El diseño se hace durante la fase de refactor y puede dar lugar a la extracción de colaboradores de una unidad que se testean a través de la interfaz pública de esta.
- Se corre el riesgo de crear unidades de software muy grandes, algo que se puede afrontar aplicando refactor de manera intensa, particularmente extrayendo a métodos privados y a colaboradores en cuanto sea posible.
- Se corre también el riesgo de crear funcionalidad no necesaria en las unidades más internas al no tener claras las necesidades de los componentes que dependen de ellas. Contradice un poco el principio de segregación de interfaces, que justamente promueve que sean definidas por las necesidades de sus consumidores.
- Puede dar problemas en la integración de los componentes.
Outside-in, London School o mockista
Su origen está también en la comunidad extreme programming, pero en este caso la londinense. El nombre viene de que promueve una metodología basada en comenzar a partir de las necesidades de los consumidores de un sistema.
En general, la metodología outside-in, defiende que un proyecto complejo se abordaría definiendo su interfaz más externa y trabajando hacia adentro, descubriendo y definiendo en el camino las unidades necesarias con la ayuda de dobles.
Algunos rasgos que caracterizan este modelo son:
- Se testean las interacciones entre las unidades, lo que conocemos como white box testing. Es decir las aserciones verifican los mensajes que unos componentes envían a otros.
- La fase de refactor es menos importante y el diseño se hace con el test en rojo.
- Los dobles de tests se usan de manera generosa, en cada momento se decide qué colaboradores maneja una unidad y se crean dobles para descubrir y establecer sus interfaces. Las clases reales se implementan posteriormente mediante un proceso TDD clásico en el que las dependencias se doblan primero y se implementan después. Por esta razón también se conoce este enfoque como Mockist TDD.
- El desarrollo va desde fuera hacia dentro, protegido por un test de aceptación.
- Se centra en la comunicación entre objetos, por lo que se podría considerar incluso un enfoque más OOP, en el sentido original de Alan Kay.
Beneficios
- Nos proporciona un enfoque de trabajo que encaja especialmente bien en equipos multidisciplinares y tiene más orientación a negocio.
- Reduce o elimina los problemas de integración del producto final.
- Reduce la probabilidad de escribir código innecesario, las interfaces son más compactas.
- Introduce la consideración del diseño desde el principio del proceso de desarrollo.
- Prestamos más atención a las interacciones entre objetos. Tener que usar primero los dobles para diseñar sus interfaces nos ayuda a que sean más concisas y fáciles de manejar.
- Encaja muy bien en la metodología Behavior Driven Development.
Inconvenientes
- El coste del refactor es más alto porque se centra en interacciones y los tests tienden a ser más frágiles por acoplamiento a la implementación. Sin embargo, hay que pensar que estas interacciones son necesarias y, sobre todo, han sido diseñadas y decididas por nosotras, por lo que son implementaciones razonablemente estables.
Behavior Driven Development
Se podría decir que si empezamos Outside-in development desde un paso más externo, nos encontramos con Behavior Driven Development.
TDD en sus dos escuelas principales es una metodología centrada en el proceso técnico de desarrollar software. Pero BDD da un paso más allá integrando el negocio en el desarrollo.
Esquemáticamente sigue siendo TDD. Se comienza con un test y el desarrollo es impulsado por nuevos tests. La diferencia es que en BDD nos preguntamos por comportamientos o features en los que estamos interesadas y las describimos en lenguaje de negocio con ejemplos. De hecho, existe un lenguaje estructurado para ello: gherkin.
Estas descripciones se traducen en forma de tests de aceptación y se desarrollan a partir de ahí, utilizando una metodología bastante similar a Outside-in que, a su vez, puede utilizar el enfoque clásico de TDD cuando toca implementar las unidades concretas de software. Con todo, el tipo de tests unitarios favorecidos por BDD tienden a usar un estilo “especificación mediante ejemplos” en oposición a aserciones.
En la práctica BDD es Outside-in TDD pero tomando como punto de partida a las personas interesadas en el software y sus necesidades, no los contratos o requisitos técnicos de la implementación.
Existen herramientas específicas para este enfoque, siendo la más conocida Cucumber, en Ruby, y que tiene ports para otros lenguajes. Estas herramientas sirven para convertir los documentos Gherkin en tests ejecutables. Pero a partir de este punto ya entramos en metodología outside-in.
Entonces, ¿qué enfoque seguir? Y ¿Cómo aprender TDD a la luz de estos enfoques?
Como se decía al principio del capítulo, el aprendizaje de TDD clásico mediante katas puede ser difícil de transferir a la práctica cotidiana en un problema real de desarrollo. Sin embargo, es un aprendizaje necesario antes de introducirse al enfoque Outside-in que resulta mucho más realista en varios aspectos.
Outside-in no excluye el enfoque clásico, pero lo pone en contexto, mientras nos proporciona un enfoque de diseño dirigido por tests al que se podrían aplicar grosso modo los mismos principios de TDD: empezar con un test, escribir el mínimo código de producción para que el test pase y refactorizar la solución si hay oportunidad.
Al fin y al cabo se trata de herramientas y lo importante es tenerlas a mano para utilizarlas cuando nos resulten más apropiadas. En el trabajo real, diría que lo importante es poder mezclar estilos a conveniencia. En una tarea concreta puede que empecemos con un estilo clásico, pero al llegar a cierto punto introduzcamos Mocks para no salirnos del foco de un determinado flujo y poder centrarnos en los detalles más tarde.
Es más difícil encontrar katas en las que se pueda usar un enfoque outside-in. Por lo general son más largas y complejas, aunque también es posible adaptar algunas katas clásicas para practicar este enfoque.
Un plan de formación en TDD podría estructurarse de la siguiente forma:
- Iniciación con katas clásicas
- Perfeccionamiento con katas en forma agile-kata
- Katas outside-in
- Perfeccionamiento con agile-kata complejas
Referencias
- Does TDD lead to good design1
- A case for Outside-in Development2
- Detroit School TDD3
- London school TDD4
- Extreme programming: origins5
- The failures of “intro to TDD”6
- Endo-Testing: Unit Testing with Mock Objects (PDF)7
- The London School of Test Driven Development8
- Outside-In development with Double Loop TDD9
- “Tell, Don’t Ask” Object Oriented Design10
20 Proyecto Todo-List
En esta parte de desarrollo con enfoque outside-in, realizaremos un pequeño proyecto que consiste en una API para una aplicación de lista de tareas.
Queremos implementar las siguientes funcionalidades:
US 1
- As a User
- I want to add tasks to a to-do list
- So that, I can organize my task
US 2
- As a User
- I want to see the task in my to-do list
- So that, I can know what I have to do next
US 3
- As a User
- I want to check a task when it is done
- So that, I can see my progress
Ejemplos para tests
- Write a test that fails (done)
- Write Production code that makes the test pass
- Refactor if there is opportunity
Endpoints, payloads y respuestas
POST /api/todo
[task:Write a test that fails]
201. Created
POST /api/todo
[task:Write Production code that makes the test pass]
201. Created
POST /api/todo
[task:Refactor if there is opportunity]
201. Created
PATCH /api/todo/1
[done:true]
200. Ok
GET /api/todo
[√] 1. Write a test that fails
[ ] 2. Write Production code that makes the test pass
[ ] 3. Refactor if there is opportunity
200. Ok
Para simplificar, la lista de tareas que esperamos es un array de strings, con los datos de las tareas formateados.
Diseño
Para desarrollar outside-in es necesario hacer un cierto diseño previo. Por supuesto, no se trata de generar todas las especificaciones de los componentes hasta el mínimo detalle, sino de plantear una idea general del modelo de arquitectura que vamos a seguir y los grandes componentes que esperamos desarrollar.
Esto nos ayudará a ubicar los distintos elementos y comprender sus relaciones y dependencias. Nos proporciona un contexto de cómo funciona el ciclo de la aplicación y cómo se organizan y comunican sus componentes.
Capas
Nuestra aplicación se organizará en capas:
- Dominio: contiene las entidades del dominio que son el corazón mismo de la aplicación y en la que se representan los conceptos, procesos y reglas de negocio.
- Aplicación: los distintos casos de uso de la aplicación, representando las intenciones de sus consumidoras
-
Infraestructura: las implementaciones concretas necesarias para que la aplicación funciones. A su vez, esta capa tiene diversos puertos:
- Puntos de entrada, como puede ser el Api, que contiene los controladores que se encargan de interaccionar con las consumidoras. En su caso aquí también residirían los comandos de consola y otros.
- Persistencia: los adaptadores de las tecnologías de persistencia que necesitamos para implementar el repositorio.
- En caso necesario, otros adaptadores.
- Vendor o Lib, contienen los recursos de terceros que necesita la aplicación para funcionar.
Las dependencias apuntan siempre hacia el dominio.
Flujo de la aplicación
Al hacer una request HTTP a un endpoint, un controlador recoge los datos necesarios y los pasa a una instancia del caso de uso correspondiente. Recoge la respuesta, si la hay, y la transforma para entregarla a la consumidora.
El caso de uso instancia o reclama del repositorio las entidades de dominio que sean necesarias y utiliza los servicios de dominio para realizar su tarea.
Los casos de uso pueden adoptar la forma de comands o queries. En el primer caso, provocan un efecto en el sistema. En el segundo, devuelven una respuesta. Para acomodar la respuesta a la demanda del controlador, pueden usar algún tipo de transformador de datos, de modo que los objetos de dominio no llegan nunca al controlador, sino una representación. Mediante un patrón Strategy podemos hacer que el controlador decida en qué representación concreta está interesado.
Arquitectura
Construiremos la aplicación usando el enfoque de arquitectura hexagonal1 con una estructura de tres capas: dominio, aplicación e infrastructura, tal como hemos detallado un poco más arriba.El desarrollo comenzará con un test de aceptación, que actúa como consumidor de la API, lo que nos llevará a implementar los controladores, en primer lugar,
Este es un esquema genérico del tipo de arquitectura que tenemos en mente al desarrollar esta aplicación.
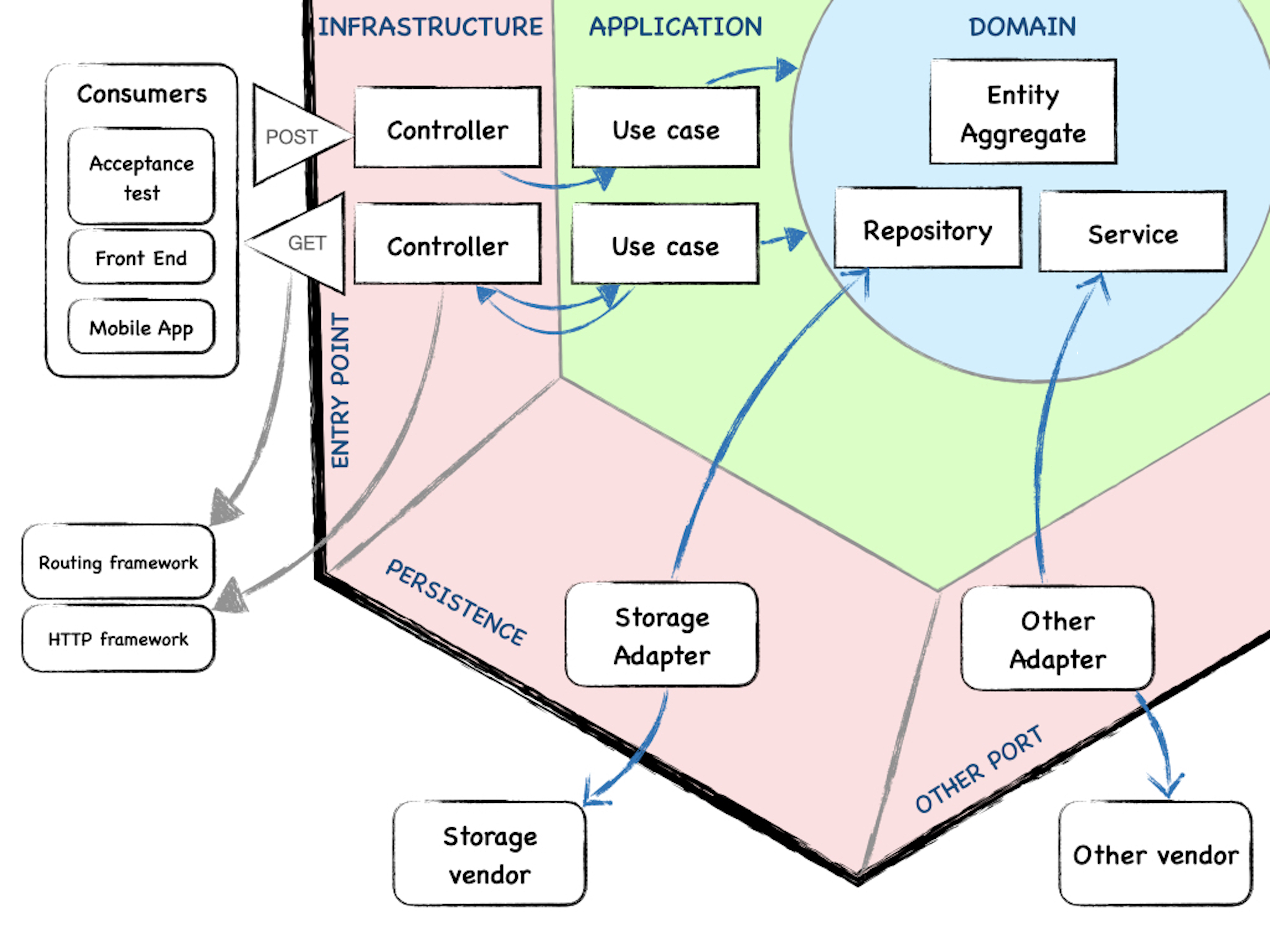
21 Outside-in mockista
Outside-in TDD, también llamado mockist o London school, es una aproximación al desarrollo dirigido por tests que busca implementar features en el software partiendo de un test de aceptación y procediendo hacia el interior del software.
En lugar de diseñar el sistema en la fase de refactoring, como hace el enfoque clásico, la aproximación outside-in lo hace durante la fase en rojo, es decir, cuando el test de aceptación todavía está fallando. El desarrollo estará terminado cuando el test de aceptación pasa. A medida que tenemos que implementar componentes, estos se desarrollan con un estilo clásico.
Así por ejemplo, en el desarrollo de una API, primero se escribiría un test de aceptación contra la API, como si el test fuese un consumidor más de ese API. El siguiente paso sería diseñar y testear el controlador, luego el caso de uso, y luego los servicios y entidades manejados por ese caso de uso, hasta llegar al dominio de la aplicación. En todos los casos haríamos mocks de las dependencias, de modo que estaríamos testeando los mensajes entre objetos de la aplicación.
Para hacerlo, la metodología se basa en dos ciclos:
- Ciclo test de aceptación. Se trata de un test que describe la feature completa en el nivel end to end, usando implementaciones reales de los componentes del sistema, excepto aquellas que definen límites del mismo. Los fallos de los test en este nivel nos sirven como guía para saber qué es lo próximo que tenemos que desarrollar.
- Ciclo de tests unitarios. Una vez que tenemos un fallo en el test de aceptación que nos indica qué tenemos que desarrollar, daremos un paso hacia el interior del sistema y usaremos tests unitarios para desarrollar el componente correspondiente, mockeando aquellos colaboradores o dependencias que este pueda necesitar. Cuando terminamos, volvemos al ciclo del test de aceptación para encontrar el que será nuestro próximo objetivo.
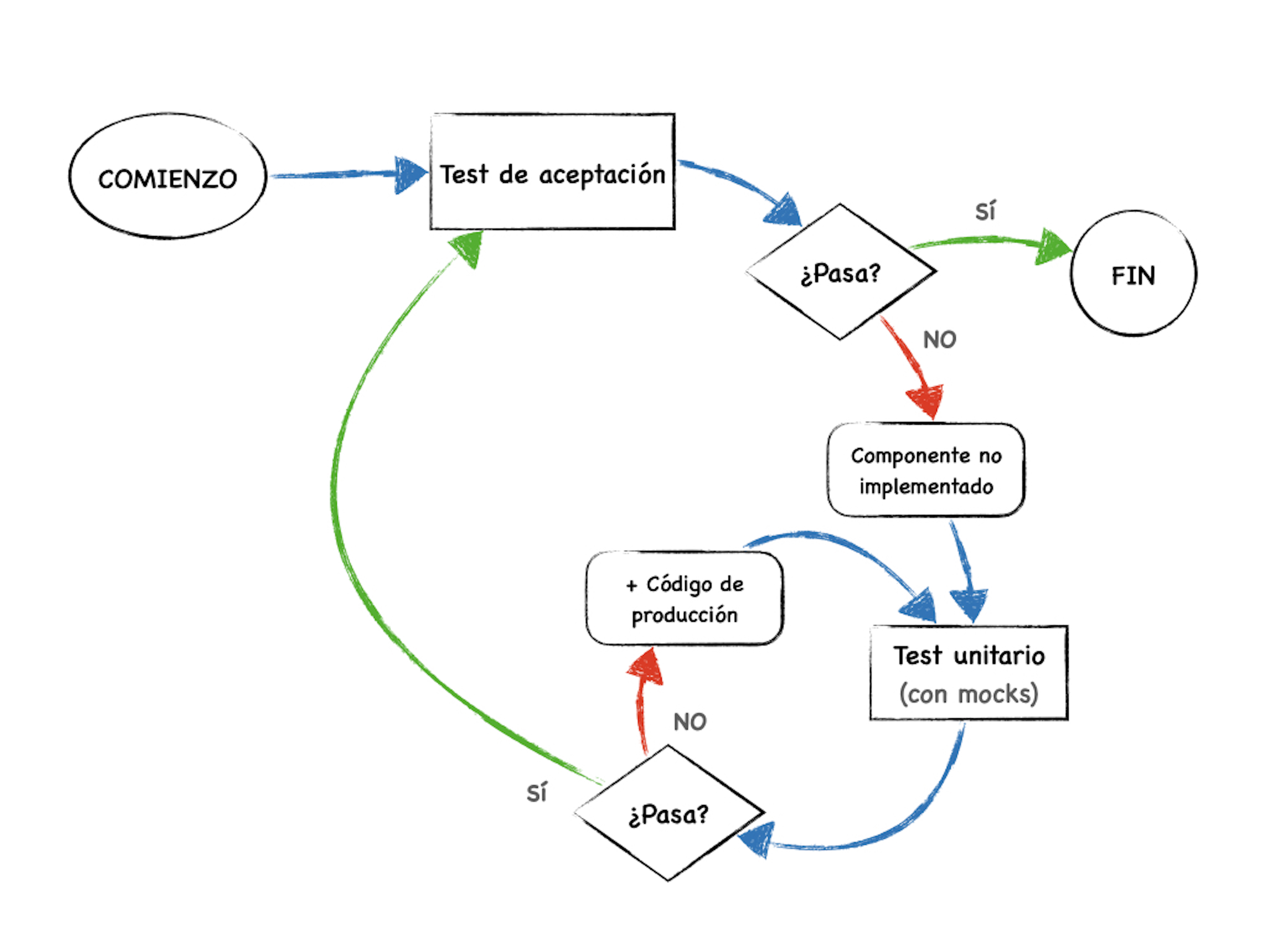
Desarrollo
En esta ocasión vamos a desarrollar la kata en PHP, usando este repositorio, ya que contiene una instalación preparada de PHP y Symfony, lo que nos proporciona un framework HTTP con el que empezar a desarrollar:
https://github.com/franiglesias/tb
En el repositorio ya tenemos un test básico que utilizaremos como punto de partida:
namespace App\Tests\Katas\TodoList;
use Symfony\Bundle\FrameworkBundle\Test\WebTestCase;
class TodoListAcceptanceTest extends WebTestCase
{
protected function setUp(): void
{
$this->resetRepositoryData();
}
protected function tearDown(): void
{
$this->resetRepositoryData();
}
private function resetRepositoryData(): void
{
if (file_exists('repository.data')) {
unlink('repository.data');
}
}
}
Diseñando el test de aceptación
Necesitamos un test de aceptación que describa cómo tiene que funcionar la aplicación. Para ello tenemos un ejemplo. Estas son las tareas que vamos a poner en nuestra lista:
1. Write a test that fails (done)
2. Write Production code that makes the test pass
3. Refactor if there is opportunity
Los pasos que el test tiene que ejecutar, por tanto, son anotar las tres tareas, marcar la primera como hecha y ser capaz de mostrarnos la lista. Estas operaciones son:
POST /api/todo
payload: [task:Write a test that fails]
POST /api/todo
payload: [task:Write Production code that makes the test pass]
POST /api/todo
payload: [task:Refactor if there is opportunity]
PATCH /api/todo/1
payload: [done:true]
GET /api/todo
Response:
[√] 1. Write a test that fails
[ ] 2. Write Production code that makes the test pass
[ ] 3. Refactor if there is opportunity
Para simplificar, la respuesta será una representación de cada tarea en una línea de texto con el formato que se puede ver arriba.
Empezando por el final: cuál será el resultado esperado
Para empezar a diseñar nuestro test, comenzamos por el final, es decir, por la llamada para recuperar la lista de tareas y que representa el resultado que esperamos obtener al final del proceso. A partir de ahí iremos reproduciendo los pasos previos necesarios para llegar a ese estado.
/** @test */
public function shouldAllowAddingTaskCompleteAndRetrieveTheList(): void
{
$expectedList = [
'[√] 1. Write a test that fails',
'[ ] 2. Write Production code that makes the test pass',
'[ ] 3. Refactor if there is opportunity',
];
$client = self::createClient();
$client->request('GET', '/api/todo');
$response = $client->getResponse();
$list = json_decode($response->getContents(), true);
self::assertEquals(Response::HTTP_OK, $response->getStatusCode());
self::assertEquals($list, $expectedList);
}
Para llegar a este punto, necesitaríamos haber hecho una petición a la API por cada tarea y una petición más para marcar una tarea como completada. De este modo, el test completo quedaría así:
/** @test */
public function shouldAllowAddingTaskCompleteAndRetrieveTheList(): void
{
$expectedList = [
'[√] 1. Write a test that fails',
'[ ] 2. Write Production code that makes the test pass',
'[ ] 3. Refactor if there is opportunity',
];
$client = self::createClient();
$taskDescription = 'Write a test that fails';
$client->request(
'POST',
'/api/todo',
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['task' => $taskDescription])
);
$taskDescription = 'Write Production code that makes the test pass';
$client->request(
'POST',
'/api/todo',
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['task' => $taskDescription])
);
$taskDescription = 'Refactor if there is opportunity';
$client->request(
'POST',
'/api/todo',
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['task' => $taskDescription])
);
$taskId = 1;
$client->request(
'PATCH',
'/api/todo/'.$taskId,
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['done' => true])
);
$client->request('GET', '/api/todo');
$response = $client->getResponse();
$list = json_decode($response->getContent(), true);
self::assertEquals($list, $expectedList);
}
Si lo ejecutamos empezaremos a ver fallos acerca de problemas de la configuración del framework. Lo primero que tenemos que hacer es conseguir que el test falle por el motivo correcto, que no es otro, sino que al pedir la lista de tareas la respuesta $list no sea la que esperamos. Por lo tanto, primero iremos resolviendo estos problemas hasta lograr que el test se ejecute.
Resolviendo los detalles necesarios en el framework
El primer error nos dice que no hay ningún controlador en la ubicación esperada por el framework. En nuestro caso, además de eso, queremos montar una solución con una arquitectura limpia. Según eso, los controladores del API deberían estar en la capa de Infraestructura, por lo que vamos a cambiar la configuración de services.yaml de Symfony de modo que espere encontrar los controladores en otra ruta. En concreto, yo prefiero ponerlos en:
src/Infrastructure/EntryPoint/Api/Controller
Por tanto, services.yaml quedará así:
# controllers are imported separately to make sure services can be injected
# as action arguments even if you don't extend any base controller class
App\Infrastructure\EntryPoint\Api\Controller\:
resource: '../src/Infrastructure/EntryPoint/Api/Controller'
tags: ['controller.service_arguments']
Si ejecutamos el test de nuevo, veremos que el mensaje de error ha cambiado, lo cual indica que hemos intervenido de manera correcta. Ahora nos indica que no hay controladores en el nuevo lugar definido, así que vamos a crear una clase TodoListController en la ubicación: \App\Infrastructure\EntryPoint\Api\Controller\TodoListController.
Y de momento, la dejamos así. Ejecutamos el test para ver qué nos dice. Tenemos dos tipos de mensajes. Por una parte, varias excepciones que nos indican que no se encuentran las rutas de los endpoints, las cuales no hemos definido todavía.
Por otra parte, el test nos indica que la llamada al endpoint devuelve null y, por tanto, no tenemos todavía la lista de tareas.
Así que necesitamos que nuestro controlador sea capaz de gestionar estas rutas antes de nada. La primera ruta que no encuentra es la de POST /api/todo, con la que añadimos tareas a la lista. Para ello, introduciremos una entrada en el archivo routes.yaml.
api_add_task:
path: /api/todo
controller: App\Infrastructure\EntryPoint\Api\Controller\TodoListController::addTask
methods: ['POST']
Una vez añadida la ruta, ejecutamos de nuevo el test de aceptación. Lo adecuado es lanzar el test con cada cambio para confirmar que falla por el motivo esperado. En este caso, esperamos que nos diga que no tenemos un método addTask en TodoListController, y lo tenemos que añadir para avanzar.
namespace App\Infrastructure\EntryPoint\Api\Controller;
class TodoListController
{
public function addTask()
{
throw new \RuntimeException(sprintf('Implement %s::%s', __CLASS__, __METHOD__));
}
}
Como puedes ver, en el método lanzo una excepción que me permitirá ver cuando se está llamando al controlador real. De este modo, sabré con seguridad si es lo que tengo que implementar a continuación. Esta técnica se la he visto a Sandro Mancuso en su vídeo sobre Outside-in y me parece muy útil. En algunas ocasiones el propio compilador o intérprete podría señalar este falta de implementación, pero hacerlo explícito hará que todo sea más fácil para nosotras.
Al relanzar el test, el primer error nos dice literalmente que hay que implementar el método addTask.
Y esto nos lleva al ciclo de tests unitarios.
Primer test unitario
El primer test unitario nos introduce un paso hacia el interior de la aplicación. El test de aceptación ejercita el código desde fuera de la aplicación, mientras que el controlador se encuentra en la capa de Infraestructura. Lo que vamos a hacer es desarrollar el controlador con un test unitario, pero en lugar de usar el enfoque clásico, que consiste en implementar una solución y luego usar la etapa de refactor para diseñar los componentes, empezaremos por este punto.
Es decir, lo que queremos hacer es diseñar qué componentes queremos que use el controlador para devolver una respuesta, mockearlos en el test, implementando solo el código propio del controlador.
En este ejemplo, voy a suponer que cada controlador invoca un caso de uso en la capa de aplicación. Para que se entienda mejor no usaré un bus de comandos como haría en una aplicación real, sino que invocaré directamente los casos de uso.
Este es mi primer test unitario:
namespace App\Tests\Infrastructure\EntryPoint\Api\Controller;
use App\Infrastructure\EntryPoint\Api\Controller\TodoListController;
use PHPUnit\Framework\TestCase;
use Symfony\Component\HttpFoundation\Request;
use Symfony\Component\HttpFoundation\Response;
class TodoListControllerTest extends TestCase
{
/** @test */
public function shouldAddTask(): void
{
$addTask = $this->createMock(AddTaskHandler::class);
$addTask
->expects(self::once())
->method('execute')
->with('Task Description');
$todoListController = new TodoListController($addTask);
$request = new Request(
[],
[],
[],
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['task' => 'Task Description'], JSON_THROW_ON_ERROR)
);
$response = $todoListController->addTask($request);
self::assertEquals(Response::HTTP_CREATED, $response->getStatusCode());
}
}
Por un lado, en el test simulamos una request con un payload JSON, que será la que nos proporcione los datos necesarios. El mock de AddTaskHandler simula que simplemente llamamos a su método execute pasándole como parámetro la descripción de la tarea proporcionada en la llamada al endpoint.
Gracias al uso de mocks no tenemos que preocuparnos de qué pasa más adentro en la aplicación. Lo que estamos testando es el modo en el que el controlador obtiene los datos relevantes y se los pasa al caso de uso para que este haga lo que tenga que hacer. Si no hay ningún problema, el controlador retornará una respuesta 201, indicando que el recurso ha sido creado. No nos vamos a ocupar en este ejemplo de todos los posibles fallos que podrían ocurrir, pero puedes hacerte una idea de cómo se gestionaría.
Ahora ejecutamos el test TodoListController para asegurar que falla por las razones esperadas: que no se llama a AddTaskHandler y que no se devuelve el código HTTP 201.
En este caso, el primer error es que no tenemos una clase AddTaskHandler que mockear, así que la creamos. La vamos a poner en App\Application.
Tiramos de nuevo el test, que nos indicará que no existe un método execute que se pueda mockear. Lo añadimos, pero dejamos que lance una excepción para decirnos que no está implementado. Veremos la utilidad de ello dentro de un rato, porque en este test no se va a ejecutar en realidad.
namespace App\Application;
class AddTaskHandler
{
public function execute(string $taskDescription)
{
throw new \RuntimeException(sprintf('Implement %s::%s', __CLASS__, __METHOD__));
}
}
En cambio, si todo ha ido bien, en este punto el test nos pedirá que implementemos el método addTask del controlador, que es el punto al que queríamos llegar.
namespace App\Infrastructure\EntryPoint\Api\Controller;
use App\Application\AddTaskHandler;
use Symfony\Component\HttpFoundation\JsonResponse;
use Symfony\Component\HttpFoundation\Request;
use Symfony\Component\HttpFoundation\Response;
class TodoListController
{
private AddTaskHandler $addTask;
public function __construct(AddTaskHandler $addTask)
{
$this->addTask = $addTask;
}
public function addTask(Request $request): Response
{
$body = json_decode($request->getContent(), true);
$this->addTask->execute($body['task']);
return new JsonResponse('', Response::HTTP_CREATED);
}
}
Este código hace pasar el test. Puesto que es relativamente sencillo no vamos a hacerlo en pasos muy pequeños a fin de avanzar más rápido con la explicación.
Vamos a aprovechar que el test está en verde para refactorizarlo un poco. Sabemos que tendremos que añadir más tests en este TestCase y que habrá que instanciar el controlador varias veces, así que vamos a hacernos la vida un poco más fácil para el futuro próximo. Tras asegurarnos de que sigue pasando, el test queda así:
namespace App\Tests\Infrastructure\EntryPoint\Api\Controller;
use App\Application\AddTaskHandler;
use App\Infrastructure\EntryPoint\Api\Controller\TodoListController;
use PHPUnit\Framework\TestCase;
use Symfony\Component\HttpFoundation\Request;
use Symfony\Component\HttpFoundation\Response;
class TodoListControllerTest extends TestCase
{
private AddTaskHandler $addTaskHandler;
private TodoListController $todoListController;
protected function setUp(): void
{
$this->addTaskHandler = $this->createMock(AddTaskHandler::class);
$this->todoListController = new TodoListController($this->addTaskHandler);
}
/** @test */
public function shouldAddTask(): void
{
$this->addTaskHandler
->expects(self::once())
->method('execute')
->with('Task Description');
$request = new Request(
[],
[],
[],
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['task' => 'Task Description'], JSON_THROW_ON_ERROR)
);
$response = $this->todoListController->addTask($request);
self::assertEquals(Response::HTTP_CREATED, $response->getStatusCode());
}
}
Es momento de volver a ejecutar el test de aceptación.
De vuelta en el ciclo de aceptación
Ahora que el test TodoListController está pasando, ya no tenemos más trabajo que hacer en este nivel, así que volvemos al test de aceptación para ver si sigue fallando algo y qué es lo que falla.
En este punto, lo que nos dice es que AddTaskHandler::execute no está implementada. ¿Recuerdas la excepción que pusimos antes? Pues eso nos dice que tenemos que movernos un nivel más adentro y ponernos en la capa de Aplicación para desarrollar el caso de uso. Por supuesto, con un test unitario.
Como hemos dicho antes, en outside-in diseñamos en la fase de test en rojo y mockeamos los componentes que la unidad actual pueda utilizar como colaboradores. Normalmente, no haremos dobles de entidades. En este caso, lo que esperamos del caso de uso es:
- Que cree una nueva tarea, modelada con una entidad de dominio
Task - Que la persista en un repositorio
- La tarea tiene que adquirir un ID, el cual será proporcionado por el repositorio.
Esto indica que el caso de uso tendrá una dependencia, el repositorio TaskRepository, y que empezaremos a modelar las tareas con una entidad Task. Este es el test.
namespace App\Tests\Application;
use App\Application\AddTaskHandler;
use PHPUnit\Framework\TestCase;
class AddTaskHandlerTest extends TestCase
{
/** @test */
public function shouldAddATaskToRepository(): void
{
$taskRepository = $this->createMock(TaskRepository::class);
$task = new Task(1, 'Task Description');
$taskRepository
->method('nextId')
->willReturn(1);
$taskRepository
->expects(self::once())
->method('store')
->with($task);
$addTaskHandler = new AddTaskHandler($taskRepository);
$addTaskHandler->execute('Task Description');
}
}
Lo ejecutamos y nos irá diciendo qué tenemos que hacer.
Lo primero será crear TaskRepository para poder mockearlo. En este caso, el repositorio se define como interfaz en la capa de dominio, como ya sabemos. Así que empezamos por ahí.
namespace App\Domain;
interface TaskRepository
{
}
Lo siguiente será la entidad Task, que también está en el dominio.
namespace App\Domain;
class Task
{
private int $id;
private string $description;
public function __construct(int $id, string $description)
{
$this->id = $id;
$this->description = $description;
}
}
De momento, me limito a crear lo básico, ya veremos lo que el desarrollo nos va pidiendo.
El siguiente error nos indica que no tenemos un método nextId en TaskRepository, así que lo introducimos en la interfaz.
namespace App\Domain;
interface TaskRepository
{
public function nextId(): int;
}
Y tampoco tenemos un método store. Lo mismo:
namespace App\Domain;
interface TaskRepository
{
public function nextId(): int;
public function store(Task $task): void;
}
Por último, al invocar el método execute, nos lanza la consabida excepción de que no tiene código, indicando que ya hemos preparado todo lo necesario hasta ahora, así que vamos a implementar por fin.
namespace App\Application;
use App\Domain\Task;
use App\Domain\TaskRepository;
class AddTaskHandler
{
private TaskRepository $taskRepository;
public function __construct(TaskRepository $taskRepository)
{
$this->taskRepository = $taskRepository;
}
public function execute(string $taskDescription): void
{
$id = $this->taskRepository->nextId();
$task = new Task($id, $taskDescription);
$this->taskRepository->store($task);
}
}
Con este código, el test pasa. Ya no tenemos nada más que hacer aquí, salvo ver si podemos refactorizar alguna cosa. En el test vemos algunos detalles que se pueden mejorar, para hacerlo todo más fácil de entender:
namespace App\Tests\Application;
use App\Application\AddTaskHandler;
use App\Domain\Task;
use App\Domain\TaskRepository;
use PHPUnit\Framework\TestCase;
class AddTaskHandlerTest extends TestCase
{
private const NEW_TASK_ID = 1;
private const NEW_TASK_DESCRIPTION = 'Task Description';
/** @test */
public function shouldAddATaskToRepository(): void
{
$task = new Task(self::NEW_TASK_ID, self::NEW_TASK_DESCRIPTION);
$taskRepository = $this->createMock(TaskRepository::class);
$taskRepository
->method('nextId')
->willReturn(self::NEW_TASK_ID);
$taskRepository
->expects(self::once())
->method('store')
->with($task);
$addTaskHandler = new AddTaskHandler($taskRepository);
$addTaskHandler->execute(self::NEW_TASK_DESCRIPTION);
}
}
Volvamos al test de aceptación, a ver qué ocurre.
Nueva visita al test de aceptación
Al ejecutar de nuevo el test de aceptación, nos indica que aunque tenemos una interfaz para TaskRepository no hemos definido ninguna implementación concreta, por lo que el test no se ejecuta. Es hora de desarrollar una.
Teniendo en cuenta que estamos creando una API REST necesitamos que las tareas que almacenemos persistan entre llamadas, por lo que en principio un repositorio en memoria no nos valdrá. En nuestro caso usaremos un vendor, que se encuentra en el repositorio que estamos usando como base para este desarrollo. Se trata de la clase FileStorageEngine. Simplemente, guarda los objetos en un archivo, de modo que simulamos una base de datos real, cuya persistencia es suficiente para ejecutar el test.
namespace App\Lib;
class FileStorageEngine
{
private string $filePath;
public function __construct($filePath)
{
$this->filePath = $filePath;
}
public function loadObjects(string $class): array
{
if (!file_exists($this->filePath)) {
return [];
}
$file = fopen($this->filePath, 'rb');
$objects = unserialize(fgets($file), ['allowed_classes' => [$class]]);
fclose($file);
return $objects;
}
public function persistObjects(array $objects): void
{
$file = fopen($this->filePath, 'wb');
fwrite($file, serialize($objects));
fclose($file);
}
}
Vamos entonces a escribir tests unitarios para desarrollar un repositorio de tareas que utilice FileStorageEngine.
namespace App\Tests\Infrastructure\Persistence;
use App\Domain\Task;
use App\Infrastructure\Persistence\FileTaskRepository;
use App\Lib\FileStorageEngine;
use PHPUnit\Framework\TestCase;
class FileTaskRepositoryTest extends TestCase
{
/** @test */
public function shouldBeAbleToStoreTasks(): void
{
$task = new Task(1, 'TaskDescription');
$storageEngine = $this->createMock(FileStorageEngine::class);
$storageEngine
->method('loadObjects')
->with(Task::class)
->willReturn([]);
$storageEngine
->expects(self::once())
->method('persistObjects')
->with(['1' => $task]);
$taskRepository = new FileTaskRepository($storageEngine);
$taskRepository->store($task);
}
}
Al ejecutar el test, nos dice que no tenemos un FileTaskRepository, así que empezamos a construirlo. Al fallar, el test nos irá indicando qué tenemos que hacer. Y este es el resultado:
namespace App\Infrastructure\Persistence;
use App\Domain\Task;
use App\Domain\TaskRepository;
use App\Lib\FileStorageEngine;
class FileTaskRepository implements TaskRepository
{
private FileStorageEngine $storageEngine;
public function __construct(FileStorageEngine $storageEngine)
{
$this->storageEngine = $storageEngine;
}
public function store(Task $task): void
{
$tasks = $this->storageEngine->loadObjects(Task::class);
$tasks[$task->id()] = $task;
$this->storageEngine->persistObjects($tasks);
}
public function nextId(): int
{
throw new \RuntimeException('Implement nextId() method.');
}
}
De nuevo, nos hemos saltado algunos baby steps para llegar a la implementación deseada. Una vez que el test pasa, volveremos al test de aceptación.
El test ahora nos indica que nos falta por implementar el método nextId en FileTaskRepository. Así que volveremos al test unitario.
En principio lo que vamos a hacer es simplemente devolver como nuevo id el número de tareas guardadas más uno. Esto no funcionará bien en el caso de que lleguemos a borrar tareas, pero por el momento será suficiente. Este es el test:
/** @test */
public function shouldProvideNextIdentity(): void
{
$storageEngine = $this->createMock(FileStorageEngine::class);
$storageEngine
->method('loadObjects')
->with(Task::class)
->willReturn([]);
$taskRepository = new FileTaskRepository($storageEngine);
$id = $taskRepository->nextId();
self::assertEquals(1, $id);
}
Y esta, la implementación:
public function nextId(): int
{
$tasks = $this->storageEngine->loadObjects(Task::class);
return count($tasks) + 1;
}
Sería necesario añadir un par de casos más para verificarlo, pero lo dejaremos así para avanzar más rápido ahora.
Finalizando la primera historia de usuario
Si lanzamos ahora el test de aceptación, veremos que el error que aparece es que no tenemos ruta para el endpoint en el que marcamos una tarea como completada. Esto quiere decir que la primera de nuestras User Stories está terminada: ya se pueden añadir tareas en la lista.
Hemos ido desde el exterior de la aplicación hasta los detalles de implementación y cada paso estaba cubierto por tests. Lo cierto es que hemos podido completar mucho trabajo, pero aún nos queda camino por delante.
Y el primer paso debería sonarnos familiar. Tenemos que definir la ruta al endpoint, el controlador, un nuevo caso de uso y la interacción con el repositorio de tareas. En routes.yaml añadimos la ruta:
api_add_task:
path: /api/todo
controller: App\Infrastructure\EntryPoint\Api\Controller\TodoListController::addTask
methods: ['POST']
api_mark_task_completed:
path: /api/todo/{taskid}
controller: App\Infrastructure\EntryPoint\Api\Controller\TodoListController::markTaskCo\
mpleted
methods: ['PATCH']
Añadimos un método a TodoListController:
namespace App\Infrastructure\EntryPoint\Api\Controller;
use App\Application\AddTaskHandler;
use Symfony\Component\HttpFoundation\JsonResponse;
use Symfony\Component\HttpFoundation\Request;
use Symfony\Component\HttpFoundation\Response;
class TodoListController
{
private AddTaskHandler $addTask;
public function __construct(AddTaskHandler $addTask)
{
$this->addTask = $addTask;
}
public function addTask(Request $request): Response
{
$payload = json_decode($request->getContent(), true);
$this->addTask->execute($payload['task']);
return new JsonResponse('', Response::HTTP_CREATED);
}
public function markTaskCompleted(int $taskid, Request $request): Response
{
throw new \RuntimeException(sprintf('Implement %s::%s', __CLASS__, __METHOD__));
}
}
Al añadir este código y ejecutar el test de aceptación el mensaje de error nos pide implementar el nuevo método. Así que nos vamos a TodoListControllerTest y añadimos el siguiente test:
namespace App\Tests\Infrastructure\EntryPoint\Api\Controller;
use App\Application\AddTaskHandler;
use App\Infrastructure\EntryPoint\Api\Controller\TodoListController;
use PHPUnit\Framework\TestCase;
use Symfony\Component\HttpFoundation\Request;
use Symfony\Component\HttpFoundation\Response;
class TodoListControllerTest extends TestCase
{
private AddTaskHandler $addTaskHandler;
private TodoListController $todoListController;
private MarkTaskCompletedHandler $markTaskCompletedHandler;
protected function setUp(): void
{
$this->addTaskHandler = $this->createMock(AddTaskHandler::class);
$this->markTaskCompletedHandler = $this->createMock(MarkTaskCompletedHandler::cla\
ss);
$this->todoListController = new TodoListController(
$this->addTaskHandler,
$this->markTaskCompletedHandler
);
}
/** @test */
public function shouldAddTask(): void
{
$this->addTaskHandler
->expects(self::once())
->method('execute')
->with('Task Description');
$request = new Request(
[],
[],
[],
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['task' => 'Task Description'], JSON_THROW_ON_ERROR)
);
$response = $this->todoListController->addTask($request);
self::assertEquals(Response::HTTP_CREATED, $response->getStatusCode());
}
/** @test */
public function shouldMarkATaskCompleted(): void
{
$this->markTaskCompletedHandler
->expects(self::once())
->method('execute')
->with(1);
$request = new Request(
[],
[],
[],
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['done' => true], JSON_THROW_ON_ERROR)
);
$taskId = 1;
$response = $this->todoListController->markTaskCompleted($taskId, $request);
self::assertEquals(Response::HTTP_OK, $response->getStatusCode());
}
}
Este test fallará porque no hemos definido MarkTaskCompletedHandler, así que iremos ejecutando el test y respondiendo a los distintos errores hasta que falle por las razones correctas y, posteriormente, implementar lo necesario para que pase.
namespace App\Application;
class MarkTaskCompletedHandler
{
public function execute(int $taskId, bool $done): void
{
throw new \RuntimeException(sprintf('Implement %s::%s', __CLASS__, __METHOD__));
}
}
Una vez que hemos añadido el código básico del caso de uso, podemos empezar a implementar el controlador, que quedará así:
namespace App\Infrastructure\EntryPoint\Api\Controller;
use App\Application\AddTaskHandler;
use App\Application\MarkTaskCompletedHandler;
use Symfony\Component\HttpFoundation\JsonResponse;
use Symfony\Component\HttpFoundation\Request;
use Symfony\Component\HttpFoundation\Response;
class TodoListController
{
private AddTaskHandler $addTask;
private MarkTaskCompletedHandler $markTaskCompleted;
public function __construct(
AddTaskHandler $addTask,
MarkTaskCompletedHandler $markTaskCompleted
)
{
$this->addTask = $addTask;
$this->markTaskCompleted = $markTaskCompleted;
}
public function addTask(Request $request): Response
{
$payload = json_decode($request->getContent(), true);
$this->addTask->execute($payload['task']);
return new JsonResponse('', Response::HTTP_CREATED);
}
public function markTaskCompleted(int $taskid, Request $request): Response
{
$payload = json_decode($request->getContent(), true);
$done = $payload['done'];
$this->markTaskCompleted->execute($taskid, $done);
return new JsonResponse('', Response::HTTP_OK);
}
}
Y con esto hacemos pasar el test TodoListControllerTest. Es momento de lanzar de nuevo el test de aceptación para que nos diga qué tenemos que hacer ahora.
Y básicamente lo que nos dice es que debemos implementar MarkTaskCompletedHandler, que no tiene código todavía. Para eso necesitaremos un test unitario.
El caso de uso necesitará el repositorio para obtener la tarea deseada y actualizarla. Eso será lo que vamos a mockear.
namespace App\Tests\Application;
use App\Application\MarkTaskCompletedHandler;
use App\Domain\Task;
use App\Domain\TaskRepository;
use PHPUnit\Framework\TestCase;
class MarkTaskCompletedHandlerTest extends TestCase
{
private const TASK_ID = 1;
/** @test */
public function shouldMarkTaskAsComplete(): void
{
$task = $this->createMock(Task::class);
$task
->expects(self::once())
->method('markCompleted');
$taskRepository = $this->createMock(TaskRepository::class);
$taskRepository
->method('retrieve')
->with(self::TASK_ID)
->willReturn($task);
$taskRepository
->expects(self::once())
->method('store')
->with($task);
$markTaskAsCompleted = new MarkTaskCompletedHandler($taskRepository);
$markTaskAsCompleted->execute(self::TASK_ID, true);
}
}
Como detalle llamativo señalar que vamos a mockear una entidad. Esto es necesario para poder testar que pase algo que nos interesa: que llamamos a su método markCompleted. Esto nos obligará a implementarlo. Normalmente evitaría mockear entidades.
Al ejecutar el test, nos pide un método retrieve, que aún no tenemos en el repositorio.
namespace App\Domain;
interface TaskRepository
{
public function nextId(): int;
public function store(Task $task): void;
public function retrieve(int $taskId): Task;
}
Así como markCompleted en Task:
namespace App\Domain;
class Task
{
private int $id;
private string $description;
public function __construct(int $id, string $description)
{
$this->id = $id;
$this->description = $description;
}
public function id(): int
{
return $this->id;
}
public function markCompleted(): void
{
throw new \RuntimeException(sprintf('Implement %s::%s', __CLASS__, __METHOD__));
}
}
Finalmente, tenemos que implementar el método execute del caso de uso, que quedará así:
namespace App\Application;
use App\Domain\TaskRepository;
class MarkTaskCompletedHandler
{
private TaskRepository $taskRepository;
public function __construct(TaskRepository $taskRepository)
{
$this->taskRepository = $taskRepository;
}
public function execute(int $taskId, bool $done): void
{
$task = $this->taskRepository->retrieve($taskId);
$task->markCompleted();
$this->taskRepository->store($task);
}
}
Y, de momento, estamos listas por aquí.
Ejecutaremos de nuevo el test de aceptación. A ver qué nos dice.
Lo primero que nos indica es que no tenemos método retrieve en el repositorio FileTaskRepository. Tenemos que implementarlo para poder seguir. Para ello, usaremos el mismo FileTaskRepositoryTestCase que ya habíamos comenzado.
/** @test */
public function shouldRetrieveTasksById(): void
{
$storageEngine = $this->createMock(FileStorageEngine::class);
$task1 = new Task(1, 'Task 1');
$task2 = new Task(2, 'Task 2');
$storageEngine
->method('loadObjects')
->with(Task::class)
->willReturn([1 => $task1, 2 => $task2]);
$taskRepository = new FileTaskRepository($storageEngine);
$task = $taskRepository->retrieve(2);
self::assertEquals($task2, $task);
}
Nos pedirá implementar retrieve. Nos bastaría con esto:
namespace App\Infrastructure\Persistence;
use App\Domain\Task;
use App\Domain\TaskRepository;
use App\Lib\FileStorageEngine;
class FileTaskRepository implements TaskRepository
{
private FileStorageEngine $storageEngine;
public function __construct(FileStorageEngine $storageEngine)
{
$this->storageEngine = $storageEngine;
}
public function store(Task $task): void
{
$tasks = $this->storageEngine->loadObjects(Task::class);
$tasks[$task->id()] = $task;
$this->storageEngine->persistObjects($tasks);
}
public function nextId(): int
{
$tasks = $this->storageEngine->loadObjects(Task::class);
return count($tasks) + 1;
}
public function retrieve(int $taskId): Task
{
$tasks = $this->storageEngine->loadObjects(Task::class);
return $tasks[$taskId];
}
}
Y efectivamente nos llega. Ahora que estamos en verde, podemos aprovechar para arreglar un poquito el test.
namespace App\Tests\Infrastructure\Persistence;
use App\Domain\Task;
use App\Infrastructure\Persistence\FileTaskRepository;
use App\Lib\FileStorageEngine;
use PHPUnit\Framework\TestCase;
class FileTaskRepositoryTest extends TestCase
{
private FileStorageEngine $storageEngine;
private FileTaskRepository $taskRepository;
protected function setUp(): void
{
$this->storageEngine = $this->createMock(FileStorageEngine::class);
$this->taskRepository = new FileTaskRepository($this->storageEngine);
}
/** @test */
public function shouldBeAbleToStoreTasks(): void
{
$task = new Task(1, 'TaskDescription');
$this->storageEngine
->method('loadObjects')
->with(Task::class)
->willReturn([]);
$this->storageEngine
->expects(self::once())
->method('persistObjects')
->with([1 => $task]);
$this->taskRepository->store($task);
}
/** @test */
public function shouldProvideNextIdentity(): void
{
$this->storageEngine
->method('loadObjects')
->with(Task::class)
->willReturn([]);
$id = $this->taskRepository->nextId();
self::assertEquals(1, $id);
}
/** @test */
public function shouldRetrieveTasksById(): void
{
$task1 = new Task(1, 'Task 1');
$task2 = new Task(2, 'Task 2');
$this->storageEngine
->method('loadObjects')
->with(Task::class)
->willReturn([1 => $task1, 2 => $task2]);
$task = $this->taskRepository->retrieve(2);
self::assertEquals($task2, $task);
}
}
Una vez hecho esto, podemos lanzar de nuevo el test de aceptación y ver dónde hemos llegado.
Al hacerlo, nos salta la excepción que habíamos dejado en Task::markCompleted. De momento la vamos a implementar sin hacer nada. Esperaremos a que otros tests nos obliguen, ya que no tenemos realmente forma de verificarlo sin crear un método solo para poder revisar su estado en un test.
namespace App\Domain;
class Task
{
private int $id;
private string $description;
public function __construct(int $id, string $description)
{
$this->id = $id;
$this->description = $description;
}
public function id(): int
{
return $this->id;
}
public function markCompleted(): void
{
}
}
Esto hace que el test pueda llegar al siguiente punto interesante: no tenemos una ruta para recuperar la lista de tareas. En routes.yaml añadimos la definición:
api_add_task:
path: /api/todo
controller: App\Infrastructure\EntryPoint\Api\Controller\TodoListController::addTask
methods: ['POST']
api_mark_task_completed:
path: /api/todo/{taskid}
controller: App\Infrastructure\EntryPoint\Api\Controller\TodoListController::markTaskCo\
mpleted
methods: ['PATCH']
api_get_tasks_list:
path: /api/todo
controller: App\Infrastructure\EntryPoint\Api\Controller\TodoListController::getTasksLi\
st
methods: ['GET']
Lanzamos el test de aceptación para ver que ya no pide la ruta, sino la implementación de un controlador. Y añadimos un esqueleto en TodoListController.
namespace App\Infrastructure\EntryPoint\Api\Controller;
use App\Application\AddTaskHandler;
use App\Application\MarkTaskCompletedHandler;
use Symfony\Component\HttpFoundation\JsonResponse;
use Symfony\Component\HttpFoundation\Request;
use Symfony\Component\HttpFoundation\Response;
class TodoListController
{
private AddTaskHandler $addTask;
private MarkTaskCompletedHandler $markTaskCompleted;
public function __construct(
AddTaskHandler $addTask,
MarkTaskCompletedHandler $markTaskCompleted
)
{
$this->addTask = $addTask;
$this->markTaskCompleted = $markTaskCompleted;
}
public function addTask(Request $request): Response
{
$payload = json_decode($request->getContent(), true);
$this->addTask->execute($payload['task']);
return new JsonResponse('', Response::HTTP_CREATED);
}
public function markTaskCompleted(int $taskid, Request $request): Response
{
$payload = json_decode($request->getContent(), true);
$done = $payload['done'];
$this->markTaskCompleted->execute($taskid, $done);
return new JsonResponse('', Response::HTTP_OK);
}
public function getTasksList(): Response
{
throw new \RuntimeException(sprintf('Implement %s::%s', __CLASS__, __METHOD__));
}
}
Así que hay volver a TodoListControllerTestCase para desarrollar este método:
namespace App\Tests\Infrastructure\EntryPoint\Api\Controller;
use App\Application\AddTaskHandler;
use App\Application\MarkTaskCompletedHandler;
use App\Domain\Task;
use App\Infrastructure\EntryPoint\Api\Controller\TodoListController;
use PHPUnit\Framework\TestCase;
use Symfony\Component\HttpFoundation\Request;
use Symfony\Component\HttpFoundation\Response;
class TodoListControllerTest extends TestCase
{
private AddTaskHandler $addTaskHandler;
private TodoListController $todoListController;
private MarkTaskCompletedHandler $markTaskCompletedHandler;
private GetTasksListHandler $getTasksListHandler;
protected function setUp(): void
{
$this->addTaskHandler = $this->createMock(AddTaskHandler::class);
$this->markTaskCompletedHandler = $this->createMock(MarkTaskCompletedHandler::cla\
ss);
$this->getTasksListHandler = $this->createMock(GetTasksListHandler::class)
$this->todoListController = new TodoListController(
$this->addTaskHandler,
$this->markTaskCompletedHandler,
$this->getTasksListHandler
);
}
/** @test */
public function shouldAddTask(): void
{
$this->addTaskHandler
->expects(self::once())
->method('execute')
->with('Task Description');
$request = new Request(
[],
[],
[],
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['task' => 'Task Description'], JSON_THROW_ON_ERROR)
);
$response = $this->todoListController->addTask($request);
self::assertEquals(Response::HTTP_CREATED, $response->getStatusCode());
}
/** @test */
public function shouldMarkATaskCompleted(): void
{
$this->markTaskCompletedHandler
->expects(self::once())
->method('execute')
->with(1);
$request = new Request(
[],
[],
[],
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['done' => true], JSON_THROW_ON_ERROR)
);
$taskId = 1;
$response = $this->todoListController->markTaskCompleted($taskId, $request);
self::assertEquals(Response::HTTP_OK, $response->getStatusCode());
}
/** @test */
public function shouldGetListOfTasks(): void
{
$task1 = new Task(1, 'Task 1');
$task1->markCompleted();
$task2 = new Task(2, 'Task 2');
$expectedList = ['[√] Task 1', '[ ] Task 2'];
$this->getTasksListHandler
->expects(self::once())
->method('execute')
->willReturn([$task1, $task2]);
$request = new Request();
$response = $this->todoListController->getTasksList($request);
$list = json_decode($response->getContent(), true);
self::assertEquals(Response::HTTP_OK, $response->getStatusCode());
self::assertEquals($expectedList, $list);
}
}
El test fallará ya que necesitamos implementar GetTasksListHandler.
namespace App\Application;
class GetTasksListHandler
{
public function execute(): array
{
throw new \RuntimeException(sprintf('Implement %s::%s', __CLASS__, __METHOD__));
}
}
Cuando podemos ejecutar todo el test, empezamos a implementar. Esta es nuestra tentativa:
namespace App\Infrastructure\EntryPoint\Api\Controller;
use App\Application\AddTaskHandler;
use App\Application\GetTasksListHandler;
use App\Application\MarkTaskCompletedHandler;
use Symfony\Component\HttpFoundation\JsonResponse;
use Symfony\Component\HttpFoundation\Request;
use Symfony\Component\HttpFoundation\Response;
class TodoListController
{
private AddTaskHandler $addTask;
private MarkTaskCompletedHandler $markTaskCompleted;
private GetTasksListHandler $getTasksList;
public function __construct(
AddTaskHandler $addTask,
MarkTaskCompletedHandler $markTaskCompleted,
GetTasksListHandler $getTasksList
)
{
$this->addTask = $addTask;
$this->markTaskCompleted = $markTaskCompleted;
$this->getTasksList = $getTasksList;
}
public function addTask(Request $request): Response
{
$payload = json_decode($request->getContent(), true);
$this->addTask->execute($payload['task']);
return new JsonResponse('', Response::HTTP_CREATED);
}
public function markTaskCompleted(int $taskid, Request $request): Response
{
$payload = json_decode($request->getContent(), true);
$done = $payload['done'];
$this->markTaskCompleted->execute($taskid, $done);
return new JsonResponse('', Response::HTTP_OK);
}
public function getTasksList(Request $request): Response
{
$list = $this->getTasksList->execute();
return new JsonResponse($list, Response::HTTP_OK);
}
}
El problema aquí es que tenemos que introducir una forma de convertir la lista tal como la devuelve el caso de uso GetTaskListHandler al formato requerido por el consumidor del endpoint. Se trata de una representación de la tarea en forma de cadena de texto.
Hay varias formas de resolver esto, y todas requieren que Task pueda darnos algún tipo de representación utilizable:
- La más sencilla sería hacer la conversión en el propio controlador, recorriendo la lista de tareas y generando su representación. Para ello nos hará falta un método que se encargue.
- Otra consistiría en crear un servicio que haga la conversión. Sería una dependencia del controlador.
- Y una tercera alternativa sería usar ese mismo servicio, pero pasándolo a
GetTaskListHandlercomo estrategia. De este modo el controlador decide cómo quiere obtener la lista, aunque seaGetTaskListHandlerquien la prepara.
Esta última opción es la que vamos a usar. Pero para eso tendremos que cambiar tests. No mucho, por suerte, tan solo TodoListControllerTest necesita cambios realmente.
namespace App\Tests\Infrastructure\EntryPoint\Api\Controller;
use App\Application\AddTaskHandler;
use App\Application\GetTasksListHandler;
use App\Application\MarkTaskCompletedHandler;
use App\Application\TaskListFormatter;
use App\Domain\Task;
use App\Infrastructure\EntryPoint\Api\Controller\TodoListController;
use PHPUnit\Framework\TestCase;
use Symfony\Component\HttpFoundation\Request;
use Symfony\Component\HttpFoundation\Response;
class TodoListControllerTest extends TestCase
{
private AddTaskHandler $addTaskHandler;
private TodoListController $todoListController;
private MarkTaskCompletedHandler $markTaskCompletedHandler;
private GetTasksListHandler $getTasksListHandler;
private TaskListFormatter $taskListFormatter;
protected function setUp(): void
{
$this->addTaskHandler = $this->createMock(AddTaskHandler::class);
$this->markTaskCompletedHandler = $this->createMock(MarkTaskCompletedHandler::cla\
ss);
$this->getTasksListHandler = $this->createMock(GetTasksListHandler::class);
$this->taskListFormatter = $this->createMock(TaskListFormatter::class);
$this->todoListController = new TodoListController(
$this->addTaskHandler,
$this->markTaskCompletedHandler,
$this->getTasksListHandler,
$this->taskListFormatter
);
}
/** @test */
public function shouldAddTask(): void
{
$this->addTaskHandler
->expects(self::once())
->method('execute')
->with('Task Description');
$request = new Request(
[],
[],
[],
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['task' => 'Task Description'], JSON_THROW_ON_ERROR)
);
$response = $this->todoListController->addTask($request);
self::assertEquals(Response::HTTP_CREATED, $response->getStatusCode());
}
/** @test */
public function shouldMarkATaskCompleted(): void
{
$this->markTaskCompletedHandler
->expects(self::once())
->method('execute')
->with(1);
$request = new Request(
[],
[],
[],
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['done' => true], JSON_THROW_ON_ERROR)
);
$taskId = 1;
$response = $this->todoListController->markTaskCompleted($taskId, $request);
self::assertEquals(Response::HTTP_OK, $response->getStatusCode());
}
/** @test */
public function shouldGetListOfTasks(): void
{
$expectedList = ['[√] Task 1', '[ ] Task 2'];
$this->getTasksListHandler
->expects(self::once())
->method('execute')
->with($this->taskListFormatter)
->willReturn($expectedList);
$request = new Request();
$response = $this->todoListController->getTasksList($request);
$list = json_decode($response->getContent(), true);
self::assertEquals(Response::HTTP_OK, $response->getStatusCode());
self::assertEquals($expectedList, $list);
}
}
Y el controlador quedará así:
namespace App\Infrastructure\EntryPoint\Api\Controller;
use App\Application\AddTaskHandler;
use App\Application\GetTasksListHandler;
use App\Application\MarkTaskCompletedHandler;
use App\Application\TaskListFormatter;
use Symfony\Component\HttpFoundation\JsonResponse;
use Symfony\Component\HttpFoundation\Request;
use Symfony\Component\HttpFoundation\Response;
class TodoListController
{
private AddTaskHandler $addTask;
private MarkTaskCompletedHandler $markTaskCompleted;
private GetTasksListHandler $getTasksList;
private TaskListFormatter $taskListFormatter;
public function __construct(
AddTaskHandler $addTask,
MarkTaskCompletedHandler $markTaskCompleted,
GetTasksListHandler $getTasksList,
TaskListFormatter $taskListFormatter
)
{
$this->addTask = $addTask;
$this->markTaskCompleted = $markTaskCompleted;
$this->getTasksList = $getTasksList;
$this->taskListFormatter = $taskListFormatter;
}
public function addTask(Request $request): Response
{
$payload = json_decode($request->getContent(), true);
$this->addTask->execute($payload['task']);
return new JsonResponse('', Response::HTTP_CREATED);
}
public function markTaskCompleted(int $taskid, Request $request): Response
{
$payload = json_decode($request->getContent(), true);
$done = $payload['done'];
$this->markTaskCompleted->execute($taskid, $done);
return new JsonResponse('', Response::HTTP_OK);
}
public function getTasksList(Request $request): Response
{
$list = $this->getTasksList->execute($this->taskListFormatter);
return new JsonResponse($list, Response::HTTP_OK);
}
}
Y el caso de uso será este:
namespace App\Application;
class GetTasksListHandler
{
public function execute(TaskListFormatter $taskListFormatter): array
{
throw new \RuntimeException(sprintf('Implement %s::%s', __CLASS__, __METHOD__));
}
}
Y, de momento, la implementación que tenemos del formateador sería así:
namespace App\Application;
class TaskListFormatter
{
public function format(array $tasks): array
{
throw new \RuntimeException(sprintf('Implement %s::%s', __CLASS__, __METHOD__));
}
}
Hemos vuelto a verde, y en este caso, como veremos, significa que ya hemos acabado con TodoListController. Veamos qué dice el test de aceptación.
El test de aceptación nos pide implementar el caso de uso. Así que tenemos que crear un nuevo test unitario.
namespace App\Tests\Application;
use App\Application\GetTasksListHandler;
use App\Application\TaskListFormatter;
use App\Domain\Task;
use App\Domain\TaskRepository;
use PHPUnit\Framework\TestCase;
class GetTasksListHandlerTest extends TestCase
{
/** @test */
public function shouldGetTheListOfTasks(): void
{
$tasks = [
new Task(1, 'Task 1'),
new Task(2, 'Task 2')
];
$expectedList = ['[√] Task 1', '[ ] Task 2'];
$tasksRepository = $this->createMock(TaskRepository::class);
$tasksRepository->method('findAll')->willReturn($tasks);
$formatter = $this->createMock(TaskListFormatter::class);
$formatter
->expects(self::once())
->method('format')
->with($tasks)
->willReturn($expectedList);
$getTaskListHandler = new GetTasksListHandler($tasksRepository);
$list = $getTaskListHandler->execute($formatter);
self::assertEquals($expectedList, $list);
}
}
Ejecutar el test nos revela la necesidad de implementar un método findAll en el repositorio. Una vez subsanado esto, nos tocará implementar el método execute del caso de uso:
namespace App\Application;
use App\Domain\TaskRepository;
use App\Application\TaskListFormatter;
class GetTasksListHandler
{
private TaskRepository $taskRepository;
public function __construct(TaskRepository $taskRepository)
{
$this->taskRepository = $taskRepository;
}
public function execute(TaskListFormatter $taskListFormatter): array
{
$tasks = $this->taskRepository->findAll();
return $taskListFormatter->format($tasks);
}
}
Esta sencilla implementación nos lleva a verde y podemos volver a lanzar el test de aceptación. Estamos muy cerca ya del final. Pero tenemos que añadir el método findAll al repositorio concreto. Primero el test:
namespace App\Tests\Infrastructure\Persistence;
use App\Domain\Task;
use App\Infrastructure\Persistence\FileTaskRepository;
use App\Lib\FileStorageEngine;
use PHPUnit\Framework\TestCase;
class FileTaskRepositoryTest extends TestCase
{
private FileStorageEngine $storageEngine;
private FileTaskRepository $taskRepository;
protected function setUp(): void
{
$this->storageEngine = $this->createMock(FileStorageEngine::class);
$this->taskRepository = new FileTaskRepository($this->storageEngine);
}
/** @test */
public function shouldBeAbleToStoreTasks(): void
{
$task = new Task(1, 'TaskDescription');
$this->storageEngine
->method('loadObjects')
->with(Task::class)
->willReturn([]);
$this->storageEngine
->expects(self::once())
->method('persistObjects')
->with([1 => $task]);
$this->taskRepository->store($task);
}
/** @test */
public function shouldProvideNextIdentity(): void
{
$this->storageEngine
->method('loadObjects')
->with(Task::class)
->willReturn([]);
$id = $this->taskRepository->nextId();
self::assertEquals(1, $id);
}
/** @test */
public function shouldRetrieveTasksById(): void
{
$task1 = new Task(1, 'Task 1');
$task2 = new Task(2, 'Task 2');
$this->storageEngine
->method('loadObjects')
->with(Task::class)
->willReturn([1 => $task1, 2 => $task2]);
$task = $this->taskRepository->retrieve(2);
self::assertEquals($task2, $task);
}
/** @test */
public function shouldRetrieveAllTasks(): void
{
$expectedTasks = [
1 => new Task(1, 'Task 1'),
2 => new Task(2, 'Task 2'),
];
$this->storageEngine
->method('loadObjects')
->with(Task::class)
->willReturn($expectedTasks);
$tasks = $this->taskRepository->findAll();
self::assertEquals($expectedTasks, $tasks);
}
}
Test que se resuelve rápidamente con:
namespace App\Infrastructure\Persistence;
use App\Domain\Task;
use App\Domain\TaskRepository;
use App\Lib\FileStorageEngine;
class FileTaskRepository implements TaskRepository
{
private FileStorageEngine $storageEngine;
public function __construct(FileStorageEngine $storageEngine)
{
$this->storageEngine = $storageEngine;
}
public function store(Task $task): void
{
$tasks = $this->storageEngine->loadObjects(Task::class);
$tasks[$task->id()] = $task;
$this->storageEngine->persistObjects($tasks);
}
public function nextId(): int
{
$tasks = $this->storageEngine->loadObjects(Task::class);
return count($tasks) + 1;
}
public function retrieve(int $taskId): Task
{
$tasks = $this->storageEngine->loadObjects(Task::class);
return $tasks[$taskId];
}
public function findAll(): array
{
return $this->storageEngine->loadObjects(Task::class);
}
}
Y volvemos a lanzar el test de aceptación para ver por dónde seguir. En esta ocasión el test nos dice que tenemos que implementar el método TaskListFormatter::format. Realmente estamos a dos pasos, pero tenemos que crear un test unitario.
En este punto podríamos plantear diversos diseños que eviten tratar temas de presentación en una entidad de dominio, pero para simplificar haremos que Task sea capaz de proporcionar su representación en forma de texto añadiendo un método asString.
Cabe preguntarse si aquí sería adecuado usar un doble de Task, algo que ya hicimos en otro test y esperar a que el test de aceptación nos pida desarrollar Task, o si sería preferible usar la entidad tal cual y que el test nos fuerce a introducir los métodos necesarios.
En la práctica, llegadas a este punto creo que todo depende de la complejidad que pueda suponer. En este ejercicio, el comportamiento de Task es bastante trivial, por lo que podríamos avanzar con la entidad sin más complicaciones. Pero si el comportamiento es complejo, posiblemente sea mejor ir despacio, trabajar con el mock y dedicarle el tiempo necesario después.
Así que aquí también usaremos mocks para eso.
namespace App\Tests\Application\Formatter;
use App\Domain\Task;
use App\Application\TaskListFormatter;
use PHPUnit\Framework\TestCase;
class TaskListFormatterTest extends TestCase
{
/** @test */
public function shouldFormatAListOfTasks(): void
{
$expected = [
'[√] 1. Task 1',
'[ ] 2. Task 2'
];
$task1 = $this->createMock(Task::class);
$task1->method('asString')->willReturn('[√] 1. Task 1');
$task2 = $this->createMock(Task::class);
$task2->method('asString')->willReturn('[ ] 2. Task 2');
$formatter = new TaskListFormatter();
$formattedList = $formatter->format([$task1, $task2]);
self::assertEquals($expected, $formattedList);
}
}
Lanzamos el test para ver que falla porque no tenemos el método asString en Task. Así que lo introducimos. Fíjate que todavía no hemos implementado markCompleted.
namespace App\Domain;
class Task
{
private int $id;
private string $description;
public function __construct(int $id, string $description)
{
$this->id = $id;
$this->description = $description;
}
public function id(): int
{
return $this->id;
}
public function markCompleted(): void
{
}
public function asString(): string
{
throw new \RuntimeException(sprintf('Implement %s::%s', __CLASS__, __METHOD__));
}
}
Al relanzar el test ya protesta porque no está implementado el método format, así que vamos a ello:
namespace App\Application\Formatter;
class TaskListFormatter
{
public function format(array $tasks): array
{
$formatted = [];
foreach ($tasks as $task) {
$formatted[] = $task->asString();
}
return $formatted;
}
}
Y ya estamos en verde. Turno de volver al bucle del test de aceptación.
Últimos pasos
El test de aceptación, como cabía esperar, falla porque Task::asString no está implementado. También habíamos dejado Task:markCompleted sin implementar no haciendo nada. Podría ser buena idea dejar que se queje de nuevo y así asegurarnos de que se llama y no olvidarnos de gestionarlo también.
namespace App\Domain;
class Task
{
private int $id;
private string $description;
public function __construct(int $id, string $description)
{
$this->id = $id;
$this->description = $description;
}
public function id(): int
{
return $this->id;
}
public function markCompleted(): void
{
throw new \RuntimeException(sprintf('Implement %s::%s', __CLASS__, __METHOD__));
}
public function asString(): string
{
throw new \RuntimeException(sprintf('Implement %s::%s', __CLASS__, __METHOD__));
}
}
Y al volver a lanzar el test de aceptación vemos que se queja de eso exactamente y que es ahí donde queríamos estar ahora.
Tenemos que seguir con el desarrollo de Task, usando un test unitario. Como no queremos añadir métodos, de momento, para verificar el estado de done, lo haremos a través de asString.
namespace App\Tests\Domain;
use App\Domain\Task;
use PHPUnit\Framework\TestCase;
class TaskTest extends TestCase
{
/** @test */
public function shouldHaveTextualRepresentation(): void
{
$task = new Task(1, 'Task Description');
$formatted = $task->asString();
self::assertEquals('[ ] 1. Task Description', $formatted);
}
}
Este test pasa. Por lo que hay que volver al test de aceptación.
Ahora el mensaje del test ha cambiado. Nos pide implementar markCompleted en Task, pero el test en sí ahora falla porque las respuestas no coinciden. Espera esto:
Array (
0 => '[√] 1. Write a test that fails'
1 => '[ ] 2. Write Production code ...t pass'
2 => '[ ] 3. Refactor if there is o...tunity'
)
Y obtiene esto:
Array (
0 => '[ ] 1. Write a test that fails'
1 => '[ ] 2. Write Production code ...t pass'
2 => '[ ] 3. Refactor if there is o...tunity'
)
A estas alturas, el motivo es obvio. No hay nada implementado en Task que se ocupe de mantener el estado de “done”.
Añadamos un caso más al test:
namespace App\Tests\Domain;
use App\Domain\Task;
use PHPUnit\Framework\TestCase;
class TaskTest extends TestCase
{
/** @test */
public function shouldHaveTextualRepresentation(): void
{
$task = new Task(1, 'Task Description');
$formatted = $task->asString();
self::assertEquals('[ ] 1. Task Description', $formatted);
}
/** @test */
public function shouldHaveTextualRepresentationWhenDone(): void
{
$task = new Task(1, 'Task Description');
$task->markCompleted();
$formatted = $task->asString();
self::assertEquals('[√] 1. Task Description', $formatted);
}
}
Ahora lo implementamos:
namespace App\Domain;
class Task
{
private int $id;
private string $description;
private bool $done;
public function __construct(int $id, string $description)
{
$this->id = $id;
$this->description = $description;
$this->done = false;
}
public function id(): int
{
return $this->id;
}
public function markCompleted(): void
{
$this->done = true;
}
public function asString(): string
{
$done = $this->done ? '√' : ' ';
return sprintf('[%s] %s. %s', $done, $this->id, $this->description);
}
}
Con el test en verde, volvemos a lanzar el test de aceptación y… ¡Sí! El test pasa sin ningún problema más: hemos terminado el desarrollo de nuestra aplicación.
Qué hemos aprendido con esta kata
- La modalidad outside-in mockista parece contravenir las normas de TDD. Pese a ello, todo el proceso ha sido guiado por lo que nos indican los test.
- El test de aceptación fallará mientras no se haya implementado todo lo necesario para ejecutar la aplicación.
- Nos movemos siempre entre el loop del test de aceptación y el de cada uno de los tests unitarios que tendremos que usar para desarrollar los componentes.
- Una vez que el test de aceptación pasa, la feature está completa, al menos en los términos que hayamos definido el test.
- En los tests unitarios usamos mocks para definir la interfaz pública de cada componente en función de las necesidades de sus consumidores, lo que nos ayuda a mantener el principio de segregación de interfaces.
22 Outside-in TDD clásico
Es posible seguir una metodología outside-in mientras mantenemos el ciclo de TDD clásico. Como ya sabrás, en esta aproximación el diseño se aplica durante la fase de refactor, por lo que, una vez que hemos desarrollado una versión tosca de la funcionalidad deseada, vamos identificando responsabilidades y extrayéndolas a diferentes objetos con los que vamos componiendo el sistema.
En las katas de estilo clásico que hemos presentado en la segunda parte del libro no hemos llegado a esta fase de extracción a colaboradores, aunque lo hemos sugerido varias veces, y sería algo perfectamente posible. De hecho, es un ejercicio recomendable.
Sin embargo, cuando hablamos de outside-in es frecuente que pensemos más bien en proyectos más complejos que los problemas propuestos en las katas. Es decir, el desarrollo de un producto de software real visto desde el punto de vista de sus consumidores.
Nuestro ejemplo de backend de aplicación de lista de tareas estaría en esta categoría. En el capítulo anterior hemos desarrollado el proyecto usando el enfoque mockista, cuya característica principal es que partimos de un test de aceptación y vamos entrando en cada componente de la aplicación, que desarrollamos con la ayuda de un test unitario, mockeando los componentes más internos que aún no hemos desarrollado.
En TDD clásico con frecuencia se hace un diseño up-front para tener una idea de los componentes necesarios y luego se desarrolla cada uno de ellos, integrándose después.
Pero outside-in clásico es un poco diferente. Empezaríamos también con un test en el nivel de aceptación y con el fin de escribir la lógica que lo hace pasar. En las fases de refactor comenzaríamos a extraer objetos capaces de hacerse cargo de las diversas responsabilidades identificadas.
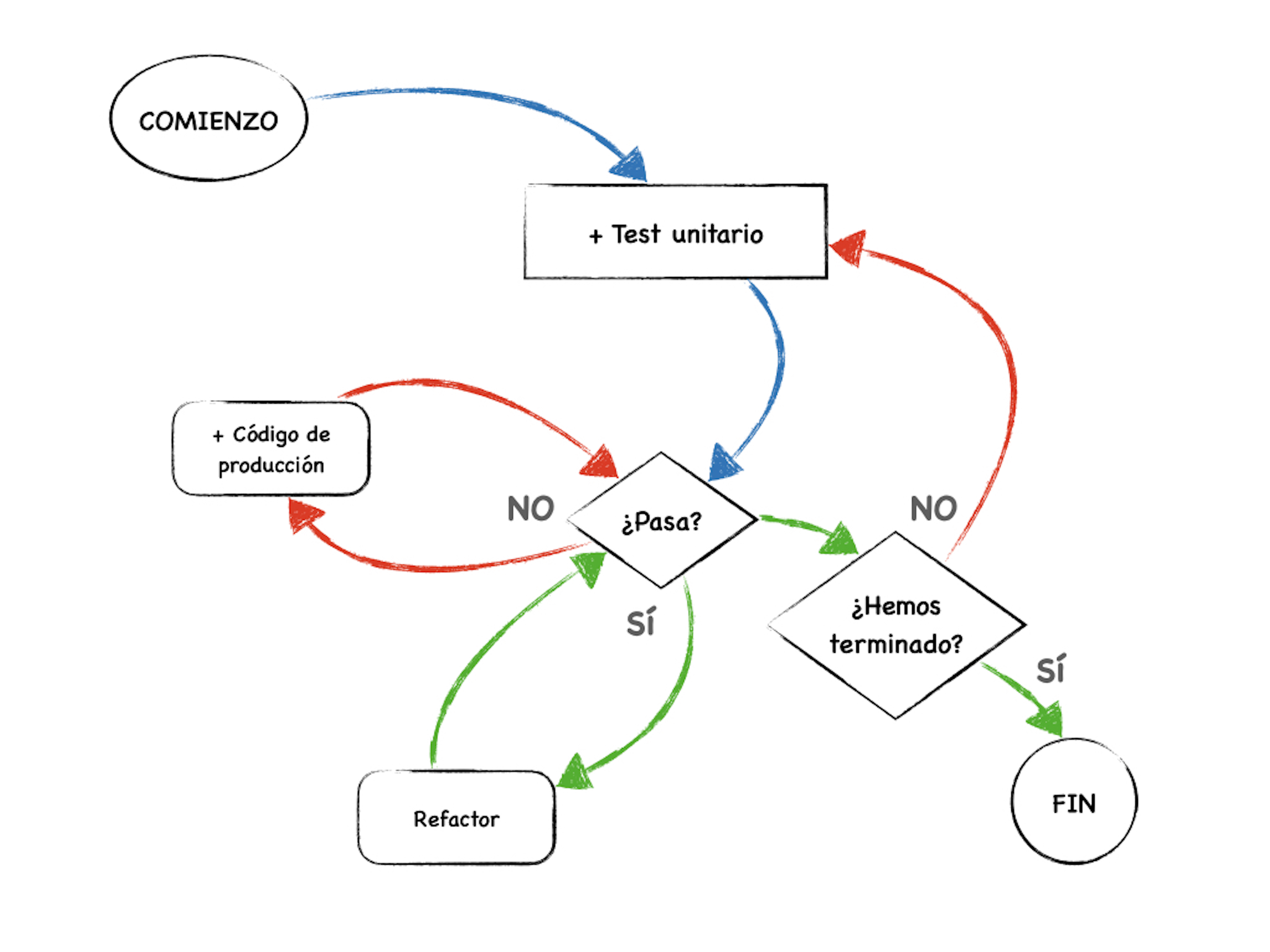
Para este ejemplo escribiremos una nueva versión de nuestra aplicación de lista de tareas, esta vez en Ruby. El framework HTTP será Sinatra y el framework de testing RSpec.
Planteando el problema
Nuestro punto de partida será igualmente un test de aceptación como consumidoras de la API. En cierto modo, podríamos considerar el sistema como un gran objeto con el que nos comunicamos mediante request a sus endpoints.
Al tratarse de TDD clásico no usaremos mocks, salvo si necesitamos definir un límite de arquitectura. Obviamente, para definir este tipo de cosas necesitamos tener algún mínimo de diseño up-front, así que esperamos que en algún momento tendremos casos de uso, entidades de dominio y repositorios.
El límite de arquitectura en nuestro ejemplo será el repositorio. Como todavía no vamos a definir cuál es la tecnología concreta de persistencia, en su momento lo mockearemos. Después veremos cómo desarrollar una implementación.
Poniendo en marcha el desarrollo
Mi primera propuesta de test es la siguiente:
# todo_list_acceptance_spec.rb
# frozen_string_literal: true
ENV['APP_ENV'] = 'test'
require 'rspec'
RSpec.describe 'As a user I want to' do
it "add a new task to the list" do
TodoListApp.new
end
end
Este test intenta instanciar un objeto TodoListApp, que es la clase en la que definiremos la aplicación Sinatra que responderá en primera instancia. Requiere instalar rspec, si no lo tenemos ya. Y fallará con este error:
NameError:
uninitialized constant TodoListApp
# ./spec/todo_list_acceptance_spec.rb:10:in `block (2 levels) in <top (required)>'
Que nos indica que no tenemos la clase definida en ningún sitio. Para hacerlo pasar, introduciré la clase en el mismo archivo del test y cuando consiga ponerlo en verde, lo moveré a su ubicación.
# todo_list_acceptance_spec.rb
# frozen_string_literal: true
ENV['APP_ENV'] = 'test'
require 'rspec'
class TodoListApp
end
RSpec.describe 'As a user I want to' do
it "add a new task to the list" do
TodoListApp.new
end
end
Esto es suficiente para hacer pasar el test, por lo que voy a hacer el refactor más obvio, que es mover TodoListApp a un lugar adecuado en el proyecto.
La fase de refactor es la fase en la que tomamos decisiones de diseño en el enfoque clásico. Los controladores pertenecen a la capa de infraestructura, por lo que será allí donde coloque esta clase. Con eso, el test queda así:
# todo_list_acceptance_spec.rb
# frozen_string_literal: true
ENV['APP_ENV'] = 'test'
require 'rspec'
require_relative '../src/infrastructure/entry_point/todo_list_app.rb'
RSpec.describe 'As a user I want to' do
it "add a new task to the list" do
TodoListApp.new
end
end
Y verificamos que sigue pasando.
Para el siguiente punto necesito hacer un salto un poco más grande y preparar el cliente que ejecutará las requests contra los endpoints. Usando rack-test, puedo crear un cliente del API. Puesto que estoy en verde, voy a introducirlo e iniciarlo. Tendremos que instalar rack-test primero.
# todo_list_acceptance_spec.rb
# frozen_string_literal: true
ENV['APP_ENV'] = 'test'
require 'rspec'
require 'rack/test'
require_relative '../src/infrastructure/entry_point/todo_list_app.rb'
RSpec.describe 'As a user I want to' do
it "add a new task to the list" do
todo_application = TodoListApp.new
@client = Rack::Test::Session.new(
Rack::MockSession.new(
todo_application
)
)
end
end
Este refactor no cambia el resultado del test, así que vamos bastante bien.
Ahora vamos a asegurarnos de que podemos hacer una llamada POST /api/todo y que alguien nos responde.
# todo_list_acceptance_spec.rb
# frozen_string_literal: true
ENV['APP_ENV'] = 'test'
require 'rspec'
require 'rack/test'
require_relative '../src/infrastructure/entry_point/todo_list_app.rb'
RSpec.describe 'As a user I want to' do
it "add a new task to the list" do
todo_application = TodoListApp.new
@client = Rack::Test::Session.new(
Rack::MockSession.new(
todo_application
)
)
@client.post '/api/todo'
end
end
Ahora el test falla, porque la aplicación no es capaz de enrutar la llamada a ningún método. Es el momento de implementar algo en TodoListApp hasta lograr hacer pasar el test. Esto requerirá introducir e instalar sinatra.
# frozen_string_literal: true
require 'sinatra'
class TodoListApp < Sinatra::Base
end
Lo cierto es que basta con esto para que el test pase, ya que no estamos haciendo ninguna expectativa sobre la respuesta. Necesitamos un poco más de resolución para obligarnos a implementar una acción asociada al endpoint, para lo cual hacemos que el test sea más preciso y explícito:
# todo_list_acceptance_spec.rb
# frozen_string_literal: true
ENV['APP_ENV'] = 'test'
require 'rspec'
require 'rack/test'
require_relative '../src/infrastructure/entry_point/todo_list_app.rb'
RSpec.describe 'As a user I want to' do
it "add a new task to the list" do
todo_application = TodoListApp.new
@client = Rack::Test::Session.new(
Rack::MockSession.new(
todo_application
)
)
@client.post '/api/todo'
expect(@client.last_response.status).to eq(201)
end
end
Y este test, que ya es un test de verdad, nos muestra que no se encuentra la ruta deseada:
1) As a user I want to add a new task to the list Failure/Error: expect(@client.last_response.status).to eq(201) expected: 201 got: 404Con lo que ya podemos implementar una acción que responda.
# frozen_string_literal: true
require 'sinatra'
class TodoListApp < Sinatra::Base
post '/api/todo' do
[201]
end
end
Ahora hemos hecho pasar el test, devolviendo una respuesta fija, y ya tenemos la seguridad de que nuestra aplicación está respondiendo al endpoint. Sería el momento de introducir la llamada con su payload, que será la descripción de la nueva tarea.
# todo_list_acceptance_spec.rb
# frozen_string_literal: true
ENV['APP_ENV'] = 'test'
require 'rspec'
require 'rack/test'
require_relative '../src/infrastructure/entry_point/todo_list_app.rb'
RSpec.describe 'As a user I want to' do
it "add a new task to the list" do
todo_application = TodoListApp.new
@client = Rack::Test::Session.new(
Rack::MockSession.new(
todo_application
)
)
@client.post '/api/todo',
{task: 'Write a test that fails'}.to_json,
{ 'CONTENT_TYPE' => 'application/json' }
expect(@client.last_response.status).to eq(201)
end
end
El test no añade nueva información. Si queremos progresar en el desarrollo necesitaremos introducir otro test que cuestione la implementación actual, obligando a hacer un cambio en la dirección de conseguir aquello que se espera que haga el test.
Este endpoint sirve para crear tareas y guardarlas en la lista, lo que quiere decir que produce un efecto (side effect) en el sistema. Es un comando y no ofrece ninguna respuesta. Para testarlo tenemos que comprobar el efecto verificando que en algún lugar hay una tarea creada.
Una posibilidad es asumir que la tarea se persistirá en un TaskRepository, que sería un colaborador de TodoListApp. Los repositorios son objetos en los límites de arquitectura y se basan en una tecnología concreta. Esto presupone un cierto nivel de diseño previo, pero creo que es un compromiso aceptable dentro del enfoque clásico.
Esto implica modifica la forma en que se instancia TodoListApp, de modo que podamos pasarle colaboradores. Así que antes de nada, vamos a refactorizar el test de modo que la creación de nuevos ejemplos sea más fácil y el test más expresivo.
Quedaría algo así:
# todo_list_acceptance_spec.rb
# frozen_string_literal: true
ENV['APP_ENV'] = 'test'
require 'rspec'
require 'rack/test'
require_relative '../src/infrastructure/entry_point/todo_list_app.rb'
def todo_application
TodoListApp.new
end
def build_client
Rack::Test::Session.new(
Rack::MockSession.new(
todo_application
)
)
end
RSpec.describe 'As a user I want to' do
before do
@client = build_client
end
it "add a new task to the list" do
@client.post '/api/todo',
{task: 'Write a test that fails'}.to_json,
{ 'CONTENT_TYPE' => 'application/json' }
expect(@client.last_response.status).to eq(201)
end
end
Con este rediseño el test sigue pasando. Ahora, tenemos que introducir un doble del repositorio. Lo mínimo necesario para forzarnos a crear algo es:
# todo_list_acceptance_spec.rb
# frozen_string_literal: true
ENV['APP_ENV'] = 'test'
require 'rspec'
require 'rack/test'
require_relative '../src/infrastructure/entry_point/todo_list_app.rb'
def todo_application
double(TaskRepository)
TodoListApp.new
end
def build_client
Rack::Test::Session.new(
Rack::MockSession.new(
todo_application
)
)
end
RSpec.describe 'As a user I want to' do
before do
@client = build_client
end
it "add a new task to the list" do
@client.post '/api/todo',
{task: 'Write a test that fails'}.to_json,
{ 'CONTENT_TYPE' => 'application/json' }
expect(@client.last_response.status).to eq(201)
end
end
Con lo que tendríamos que introducir la definición de la clase. De momento, lo haremos en el mismo archivo.
# ...
class TaskRepository
end
def todo_application
double(TaskRepository)
TodoListApp.new
end
# ...
Y se lo pasamos a TodoListApp como parámetro de construcción.
# todo_list_acceptance_spec.rb
# frozen_string_literal: true
ENV['APP_ENV'] = 'test'
require 'rspec'
require 'rack/test'
require_relative '../src/infrastructure/entry_point/todo_list_app.rb'
class TaskRepository
end
def todo_application
@task_repository = double(TaskRepository)
TodoListApp.new @task_repository
end
def build_client
Rack::Test::Session.new(
Rack::MockSession.new(
todo_application
)
)
end
RSpec.describe 'As a user I want to' do
before do
@client = build_client
end
it "add a new task to the list" do
@client.post '/api/todo',
{task: 'Write a test that fails'}.to_json,
{ 'CONTENT_TYPE' => 'application/json' }
expect(@client.last_response.status).to eq(201)
end
end
# frozen_string_literal: true
require 'sinatra'
class TodoListApp < Sinatra::Base
def initialize(task_repository)
@task_repository = task_repository
end
post '/api/todo' do
[201]
end
end
En principio estos cambios no afectan al resultado del test. Así que vamos a mover TaskRepository a su sitio, en la capa de dominio.
A continuación, necesitamos definir el efecto que esperamos obtener, lo cual hacemos fijando una expectativa sobre el mensaje que vamos a enviar a task repository.
# todo_list_acceptance_spec.rb
# frozen_string_literal: true
ENV['APP_ENV'] = 'test'
require 'rspec'
require 'rack/test'
require_relative '../src/infrastructure/entry_point/todo_list_app.rb'
require_relative '../src/domain/task_repository'
def todo_application
@task_repository = double(TaskRepository)
TodoListApp.new @task_repository
end
def build_client
Rack::Test::Session.new(
Rack::MockSession.new(
todo_application
)
)
end
RSpec.describe 'As a user I want to' do
before do
@client = build_client
end
it "add a new task to the list" do
expect(@task_repository)
.to receive(:store)
.with(instance_of(Task))
@client.post '/api/todo',
{task: 'Write a test that fails'}.to_json,
{ 'CONTENT_TYPE' => 'application/json' }
expect(@client.last_response.status).to eq(201)
end
end
end
El test falla inicialmente porque hemos introducido Task, así que lo añadimos ya en su ubicación en la capa de dominio, porque lo necesitaremos enseguida. Al hacerlo, conseguimos que el test falle por el motivo adecuado:
1) As a user I want to add a new task to the list
Failure/Error:
expect(@task_repository)
.to receive(:store)
.with(instance_of(Task))
(Double TaskRepository).store(an_instance_of(Task))
expected: 1 time with arguments: (an_instance_of(Task))
received: 0 times
Añadiendo este código en TodoListApp, hacemos que pase el test.
# frozen_string_literal: true
require 'sinatra'
class TodoListApp < Sinatra::Base
def initialize(task_repository)
@task_repository = task_repository
end
post '/api/todo' do
task = Task.new
@task_repository.store(task)
[201]
end
end
Ahora necesitamos que un nuevo test nos pida implementar que se instancie una Task con los valores deseados. Esto es, queremos que Task se inicie con el ID 1 y la descripción que le pasamos. Para que el test funcione tenemos que implementar una inicialización en Task, que aún no tenemos y alguna forma de comparar objetos Task.
Por otro lado, tenemos que implementar alguna manera de inicializar Task. Esta creación puede ser cubierta por el propio test de aceptación. Otro modo de hacerlo sería desarrollando Task con un test unitario, pero la verdad es que, de momento, no lo veo necesario.
Al introducir esto en el test:
# todo_list_acceptance_spec.rb
# frozen_string_literal: true
ENV['APP_ENV'] = 'test'
require 'rspec'
require 'rack/test'
require_relative '../src/infrastructure/entry_point/todo_list_app.rb'
require_relative '../src/domain/task_repository'
require_relative '../src/domain/task'
def todo_application
@task_repository = double(TaskRepository)
TodoListApp.new @task_repository
end
def build_client
Rack::Test::Session.new(
Rack::MockSession.new(
todo_application
)
)
end
RSpec.describe 'As a user I want to' do
before do
@client = build_client
end
it "add a new task to the list" do
task = Task.new 1, 'Write a test that fails'
expect(@task_repository)
.to receive(:store)
.with(instance_of(Task))
@client.post '/api/todo',
{ task: 'Write a test that fails' }.to_json,
{ 'CONTENT_TYPE' => 'application/json' }
expect(@client.last_response.status).to eq(201)
end
end
Empezará a fallar, por lo que tenemos que implementar la inicialización:
class Task
def initialize(id, description)
@id = id
@description = description
end
end
El test falla ahora porque en el TodoListApp no estamos inicializando bien Task ya que no le pasábamos argumentos. Con este pequeño cambio, el test ya pasa.
# frozen_string_literal: true
require 'sinatra'
require_relative '../../domain/task'
require_relative '../../domain/task_repository'
class TodoListApp < Sinatra::Base
def initialize(task_repository)
@task_repository = task_repository
end
post '/api/todo' do
task = Task.new 1, 'Write a test that fails'
@task_repository.store(task)
[201]
end
end
Se puede decir que aquí estamos usando constantes para satisfacer el test, por lo que tenemos que evolucionar el código y obtener una implementación más flexible. Empezaré con un pequeño refactor que ponga de manifiesto lo que tenemos que lograr a continuación.
# frozen_string_literal: true
require 'sinatra'
require_relative '../../domain/task'
require_relative '../../domain/task_repository'
class TodoListApp < Sinatra::Base
def initialize(task_repository)
@task_repository = task_repository
end
post '/api/todo' do
task_id = 1
task_description = 'Write a test that fails'
task = Task.new task_id, task_description
@task_repository.store(task)
[201]
end
end
Así de simple, tenemos que obtener valores para las variables que acabamos de introducir. Pero ahora mismo no lo estamos comprobando. Es el momento de introducir un matcher.
RSpec::Matchers.define :has_same_data do |expected|
match do |actual|
expected.id == actual.id && expected.description == actual.description
end
end
Para usarlo, cambiaremos el test:
# todo_list_acceptance_spec.rb
# frozen_string_literal: true
ENV['APP_ENV'] = 'test'
require 'rspec'
require 'rack/test'
require 'json'
require_relative '../src/infrastructure/entry_point/todo_list_app.rb'
require_relative '../src/domain/task_repository'
require_relative '../src/domain/task'
def todo_application
@task_repository = double(TaskRepository)
TodoListApp.new @task_repository
end
def build_client
Rack::Test::Session.new(
Rack::MockSession.new(
todo_application
)
)
end
RSpec::Matchers.define :has_same_data do |expected|
match do |actual|
expected.id == actual.id && expected.description == actual.description
end
end
RSpec.describe 'As a user I want to' do
before do
@client = build_client
end
it "add a new task to the list" do
task = Task.new 1, 'Write a test that fails'
expect(@task_repository)
.to receive(:store)
.with(has_same_data(task))
@client.post '/api/todo',
{ task: 'Write a test that fails' }.to_json,
{ 'CONTENT_TYPE' => 'application/json' }
expect(@client.last_response.status).to eq(201)
end
end
En este momento el test no pasará porque Task no expone métodos para acceder a sus propiedades, por lo que añadiremos attr_reader:
class Task
attr_reader :description, :id
def initialize(id, description)
@id = id
@description = description
end
end
Y con esto el test pasa.
task_description viene en la payload de la request. Puesto que ya está definida en el test ahora mismo podríamos simplemente usarla.
# frozen_string_literal: true
require 'sinatra'
require_relative '../../domain/task'
require_relative '../../domain/task_repository'
class TodoListApp < Sinatra::Base
def initialize(task_repository)
@task_repository = task_repository
end
post '/api/todo' do
payload = JSON.parse request.body.read.to_s
task_description = payload['task']
task_id = 1
task = Task.new task_id, task_description
@task_repository.store(task)
[201]
end
end
En cuanto al ID de task, necesitaremos un generador de identidades. En nuestro diseño hemos puesto esta responsabilidad en TaskRepository, que tendría un método next_id. En este caso, tendremos que especificarlo en el test mediante un stub.
# todo_list_acceptance_spec.rb
# frozen_string_literal: true
ENV['APP_ENV'] = 'test'
require 'rspec'
require 'rack/test'
require_relative '../src/infrastructure/entry_point/todo_list_app.rb'
require_relative '../src/domain/task_repository'
require_relative '../src/domain/task'
def todo_application
@task_repository = double(TaskRepository)
TodoListApp.new @task_repository
end
def build_client
Rack::Test::Session.new(
Rack::MockSession.new(
todo_application
)
)
end
RSpec.describe 'As a user I want to' do
before do
@client = build_client
end
it "add a new task to the list" do
task = Task.new 1, 'Write a test that fails'
allow(@task_repository)
.to receive(:next_id)
.and_return(1)
expect(@task_repository)
.to receive(:store)
.with(instance_of(Task))
@client.post '/api/todo',
{ task: 'Write a test that fails' }.to_json,
{ 'CONTENT_TYPE' => 'application/json' }
expect(@client.last_response.status).to eq(201)
end
end
Tal y como está el código de producción el test pasa, por lo que no nos dice qué tendríamos que hacer a continuación, así que voy a hacer una pequeña trampa y forzar un fallo del test:
# frozen_string_literal: true
require 'sinatra'
require_relative '../../domain/task'
require_relative '../../domain/task_repository'
class TodoListApp < Sinatra::Base
def initialize(task_repository)
@task_repository = task_repository
end
post '/api/todo' do
payload = JSON.parse request.body.read.to_s
task_description = payload['task']
task_id = 0
task = Task.new task_id, task_description
@task_repository.store(task)
[201]
end
end
Ahora sí tiene sentido introducir la llamada a next_id:
# frozen_string_literal: true
require 'sinatra'
require_relative '../../domain/task'
require_relative '../../domain/task_repository'
class TodoListApp < Sinatra::Base
def initialize(task_repository)
@task_repository = task_repository
end
post '/api/todo' do
payload = JSON.parse request.body.read.to_s
task_description = payload['task']
task_id = @task_repository.next_id
task = Task.new task_id, task_description
@task_repository.store(task)
[201]
end
end
Extracción del caso de uso
Ahora el test ya pasa y podríamos decir que la implementación del endpoint está completa. Sin embargo, tenemos varios problemas:
-
TaskRepositoryes un mock. Sabemos qué interfaz debería tener, pero no tenemos ninguna implementación concreta que pueda funcionar en producción. - En el controlador hay un montón de lógica de negocio que no debería estar ahí.
- De hecho tenemos objetos de dominio en el controlador:
TaskyTaskRepostory.
En resumen, ahora mismo, el controlador está haciendo más cosas de las debidas. Además de su tarea como controlador, que es gestionar la request que viene del exterior, está haciendo tareas de la capa de aplicación, coordinando objetos del dominio.
Por tanto, tendríamos que extraer esta parte de la implementación a un nuevo objeto, que será el caso de uso AddTaskHandler.
Lo primero que hago es extraer la funcionalidad a un método privado
# frozen_string_literal: true
require 'sinatra'
require_relative '../../domain/task'
require_relative '../../domain/task_repository'
class TodoListApp < Sinatra::Base
def initialize(task_repository)
@task_repository = task_repository
end
post '/api/todo' do
payload = JSON.parse request.body.read.to_s
task_description = payload['task']
add_task(task_description)
[201]
end
private
def add_task(task_description)
task_id = @task_repository.next_id
task = Task.new task_id, task_description
@task_repository.store(task)
end
end
Crearé una clase AddTaskHandler en la capa de aplicación que encapsule la misma funcionalidad:
class AddTaskHandler
def initialize(task_repository)
@task_repository = task_repository
end
def execute(task_description)
task_id = @task_repository.next_id
task = Task.new task_id, task_description
@task_repository.store(task)
end
end
Y reemplazo la implementación del método por una llamada:
# frozen_string_literal: true
require 'sinatra'
require_relative '../../domain/task'
require_relative '../../domain/task_repository'
require_relative '../../application/add_task_handler'
class TodoListApp < Sinatra::Base
def initialize(task_repository)
@task_repository = task_repository
end
post '/api/todo' do
payload = JSON.parse request.body.read.to_s
task_description = payload['task']
add_task(task_description)
[201]
end
private
def add_task(task_description)
@add_task_handler = AddTaskHandler.new @task_repository
@add_task_handler.execute task_description
end
end
Hago un inline del método:
# frozen_string_literal: true
require 'sinatra'
require_relative '../../domain/task'
require_relative '../../domain/task_repository'
require_relative '../../application/add_task_handler'
class TodoListApp < Sinatra::Base
def initialize(task_repository)
@task_repository = task_repository
end
post '/api/todo' do
payload = JSON.parse request.body.read.to_s
task_description = payload['task']
@add_task_handler = AddTaskHandler.new @task_repository
@add_task_handler.execute task_description
[201]
end
end
Y refactorizo un poco la solución, moviendo la inicialización al constructor y eliminando alguna variable temporal:
# frozen_string_literal: true
require 'sinatra'
require_relative '../../domain/task'
require_relative '../../domain/task_repository'
require_relative '../../application/add_task_handler'
class TodoListApp < Sinatra::Base
def initialize(task_repository)
@task_repository = task_repository
@add_task_handler = AddTaskHandler.new @task_repository
end
post '/api/todo' do
payload = JSON.parse request.body.read.to_s
@add_task_handler.execute payload['task']
[201]
end
end
El siguiente paso es inyectar la dependencia de AddTaskHandler en lugar de la del repositorio. Para ello cambio primero el test:
# todo_list_acceptance_spec.rb
# frozen_string_literal: true
ENV['APP_ENV'] = 'test'
require 'rspec'
require 'rack/test'
require 'json'
require_relative '../src/infrastructure/entry_point/todo_list_app.rb'
require_relative '../src/domain/task_repository'
require_relative '../src/domain/task'
def todo_application
@task_repository = double(TaskRepository)
@add_task_handler = AddTaskHandler.new @task_repository
TodoListApp.new @add_task_handler
end
def build_client
Rack::Test::Session.new(
Rack::MockSession.new(
todo_application
)
)
end
RSpec::Matchers.define :has_same_data do |expected|
match do |actual|
expected.id == actual.id && expected.description == actual.description
end
end
RSpec.describe 'As a user I want to' do
before do
@client = build_client
end
it "add a new task to the list" do
task = Task.new 1, 'Write a test that fails'
allow(@task_repository)
.to receive(:next_id)
.and_return(1)
expect(@task_repository)
.to receive(:store)
.with(has_same_data(task))
@client.post '/api/todo',
{ task: 'Write a test that fails' }.to_json,
{ 'CONTENT_TYPE' => 'application/json' }
expect(@client.last_response.status).to eq(201)
end
end
Esto hará que el test falle porque el código de producción sigue esperando al repositorio como dependencia, así que lo cambiamos de este modo:
# frozen_string_literal: true
require 'sinatra'
require_relative '../../domain/task'
require_relative '../../domain/task_repository'
require_relative '../../application/add_task_handler'
class TodoListApp < Sinatra::Base
def initialize(add_task_handler)
@add_task_handler = add_task_handler
end
post '/api/todo' do
payload = JSON.parse request.body.read.to_s
@add_task_handler.execute payload['task']
[201]
end
end
Y ya tenemos esta parte resuelta.
Implementando un repositorio
Para arrancar el desarrollo hemos empezado con un TaskRepository que es un mock. Hemos introducido una clase vacía para poder doblarla, pero esta version real no puede recibir mensajes siquiera. Esto ha sido una licencia que me he permitido para no empezar a desarrollar desde dentro, creando componentes de la capa de dominio como este repositorio, antes de saber cómo iban a ser usados.
El repositorio es uno de esos objetos que viven en el límite de arquitectura, por así decir, por lo que es bastante aceptable usar un doble. Sin embargo, ahora vamos a tratar de implementar una versión que pueda servirnos para testear.
Esto supone un pequeño problema si consideramos que TaskRepository es un objeto del dominio, por lo que no queremos tener implementaciones concretas en esta capa. Una forma sencilla de hacerlo es mediante composición: en dominio tendríamos una clase TaskRepository que simplemente delegaría en la implementación concreta que inyectemos. Este es el enfoque que vamos a adoptar en este caso, implementando las versiones del repositorio que puedan ser necesarias a partir de un test unitario extrayendo las implementaciones a partir de una genérica.
En esta ocasión empezamos por la capacidad del repositorio de atender un mensaje next_id, que debería ser 1 cuando el repositorio está vacío.
require 'rspec'
describe 'TaskRepository' do
it 'should provide empty collection of tasks' do
task_repository = TaskRepository.new
result = task_repository.next_id
expect(result).to eq(1)
end
end
Este método aún no existe y el test fallará. Implementamos una versión inicial.
class TaskRepository
def next_id
1
end
end
Con el test en verde, vamos a hacer un refactor. next_id debería proporcionarnos un número que es el resultado de sumar uno a la cantidad de tareas almacenada. Así que vamos a representar esto en código primero.
class TaskRepository
def initialize
@tasks = {}
end
def next_id
@tasks.count + 1
end
end
Lo suyo sería poder añadir elementos y ver si las cosas realmente funcionan, así que vamos a permitir que el repositorio se pueda inicializar con algún contenido.
class TaskRepository
def initialize(*tasks)
tasks.empty? ? @tasks = {} : (@tasks = Hash[tasks.collect { |task| [task.id, task] }]\
unless tasks.empty?)
end
def next_id
@tasks.count + 1
end
end
Con esto, podemos testear que si iniciamos el repositorio con algún elemento nos devuelve el identificador correcto. Por ejemplo, así:
require 'rspec'
require_relative '../../src/domain/task_repository'
require_relative '../../src/domain/task'
describe 'TaskRepository' do
it 'first identity should be 1' do
task_repository = TaskRepository.new
result = task_repository.next_id
expect(result).to eq(1)
end
it 'should have next_id = n+1 if contains n tasks' do
task = Task.new 1, 'Description'
task_repository = TaskRepository.new task
expect(task_repository.next_id).to eq(2)
end
end
Esto ya debería ser suficiente para fiarnos de next_id. Puede que estés pensando que la generación de identidades con este algoritmo no es precisamente robusta, pero de momento nos llega para el ejemplo. En cualquier caso, podríamos implementar cualquier otra estrategia.
Ahora podríamos usar next_id como una manera indirecta de saber si hemos añadido tareas en el repositorio, por lo que ya podemos testear el método store.
require 'rspec'
require_relative '../../src/domain/task_repository'
require_relative '../../src/domain/task'
describe 'TaskRepository' do
it 'first identity should be 1' do
task_repository = TaskRepository.new
result = task_repository.next_id
expect(result).to eq(1)
end
it 'should have next_id = n+1 if contains n tasks' do
task = Task.new 1, 'Description'
task_repository = TaskRepository.new task
expect(task_repository.next_id).to eq(2)
end
it 'should add a Task' do
task_repository = TaskRepository.new
task = Task.new 1, 'Task Description'
task_repository.store task
expect(task_repository.next_id).to eq(2)
end
end
De momento, el test falla porque no tenemos un método que atienda el mensaje store, así que lo añadimos es implementamos la solución más simple:
class TaskRepository
def initialize(*tasks)
tasks.empty? ? @tasks = {} : (@tasks = Hash[tasks.collect { |task| [task.id, task] }]\
unless tasks.empty?)
end
def next_id
@tasks.count + 1
end
def store(task)
@tasks.store task.id, task
end
end
Que, por lo demás, es suficiente para hacer pasar el test. El último test se superpone al anterior test de next_id, así que lo vamos a quitar.
require 'rspec'
require_relative '../../src/domain/task_repository'
require_relative '../../src/domain/task'
describe 'TaskRepository' do
it 'should add a Task' do
task_repository = TaskRepository.new
task = Task.new 1, 'Task Description'
task_repository.store task
expect(task_repository.next_id).to eq(2)
end
end
Y también podemos quitar la inicialización, ya que no la necesitamos realmente.
class TaskRepository
def initialize
@tasks = {}
end
def next_id
@tasks.count + 1
end
def store(task)
@tasks.store task.id, task
end
end
Podríamos asegurarnos de que podemos introducir más tareas:
require 'rspec'
require_relative '../../src/domain/task_repository'
require_relative '../../src/domain/task'
describe 'TaskRepository' do
it 'first identity should be 1' do
task_repository = TaskRepository.new
result = task_repository.next_id
expect(result).to eq(1)
end
it 'should add a Task' do
task_repository = TaskRepository.new
task = Task.new 1, 'Task Description'
task_repository.store task
expect(task_repository.next_id).to eq(2)
end
it 'should add several tasks' do
task_repository = TaskRepository.new
@task_repository.store Task.new(1, 'Task Description')
@task_repository.store Task.new(2, 'Another Task')
@task_repository.store Task.new(3, 'Third Task')
expect(task_repository.next_id).to eq(4)
end
end
Puesto que queremos separar la tecnología concreta de persistencia, usaré estos tests para extraer un repositorio en memoria. Nos queda así:
require_relative '../infrastructure/persistence/memory_storage'
class TaskRepository
def initialize
@storage = MemoryStorage.new
end
def next_id
@storage.next_id
end
def store(task)
@storage.store task
end
end
class MemoryStorage
def initialize
@objects = {}
end
def next_id
@objects.count + 1
end
def store(object)
@objects.store object.id, object
end
end
Ahora podemos inyectarlo, para ello modificamos primero el test:
require 'rspec'
require_relative '../../src/domain/task_repository'
require_relative '../../src/domain/task'
describe 'TaskRepository' do
before() do
@task_repository = TaskRepository.new
end
it 'first identity should be 1' do
result = @task_repository.next_id
expect(result).to eq(1)
end
it 'should add a Task' do
task = Task.new 1, 'Task Description'
@task_repository.store task
expect(@task_repository.next_id).to eq(2)
end
it 'should add several tasks' do
@task_repository.store Task.new(@task_repository.next_id, 'Task Description')
@task_repository.store Task.new(@task_repository.next_id, 'Another Task')
@task_repository.store Task.new(@task_repository.next_id, 'Third Task')
expect(@task_repository.next_id).to eq(4)
end
end
Y ahora que solo tenemos un lugar para inicializar el repositorio…
require 'rspec'
require_relative '../../src/domain/task_repository'
require_relative '../../src/domain/task'
require_relative '../../src/infrastructure/persistence/memory_storage'
describe 'TaskRepository' do
before() do
memory_storage = MemoryStorage.new
@task_repository = TaskRepository.new memory_storage
end
# ...
end
El test fallará, pero solo es necesario hacer este cambio:
class TaskRepository
def initialize(storage)
@storage = storage
end
def next_id
@storage.next_id
end
def store(task)
@storage.store task
end
end
Con el cual tenemos un TaskRepository que podremos configurar para usar distintas tecnologías de persistencia y que podríamos empezar a usar en nuestro test de aceptación.
Un cambio posible es este, aunque luego seguiremos evolucionándolo:
# todo_list_acceptance_spec.rb
# frozen_string_literal: true
# ...
RSpec.describe 'As a user I want to' do
before do
@client = build_client
end
it "add a new task to the list" do
@client.post '/api/todo',
{ task: 'Write a test that fails' }.to_json,
{ 'CONTENT_TYPE' => 'application/json' }
expect(@client.last_response.status).to eq(201)
expect(@task_repository.next_id).to eq(2)
end
end
Obtener la lista de las tareas
Una vez que podemos añadir tareas, sería interesante poder acceder a ellas. Nuestro siguiente test de aceptación describiría esta acción, introduciendo una o más tareas y obteniendo una lista con todas las que tengamos.
# todo_list_acceptance_spec.rb
# frozen_string_literal: true
# ...
RSpec.describe 'As a user I want to' do
before do
@client = build_client
end
it "add a new task to the list" do
@client.post '/api/todo',
{ task: 'Write a test that fails' }.to_json,
{ 'CONTENT_TYPE' => 'application/json' }
expect(@client.last_response.status).to eq(201)
expect(@task_repository.next_id).to eq(2)
end
it 'get a list with all the tasks I\'ve introduced' do
@client.post '/api/todo',
{ task: 'Write a test that fails' }.to_json,
{ 'CONTENT_TYPE' => 'application/json' }
@client.get '/api/todo'
expect(@client.last_response.status).to eq(200)
expected_list = [
'[ ] 1. Write a test that fails'
]
expect(@client.last_response.body).to eq(expected_list.to_json)
end
end
Lanzamos este test y vemos que falla, ya que no hay controlador que se encargue de esta ruta.
1) As a user I want to get a list with all the tasks I've introduced
Failure/Error: expect(@client.last_response.status).to eq(200)
expected: 200
got: 404
````
Así que añadimos uno:
```ruby
# frozen_string_literal: true
require 'sinatra'
require_relative '../../domain/task'
require_relative '../../domain/task_repository'
require_relative '../../application/add_task_handler'
class TodoListApp < Sinatra::Base
def initialize(add_task_handler)
@add_task_handler = add_task_handler
end
post '/api/todo' do
payload = JSON.parse request.body.read.to_s
@add_task_handler.execute payload['task']
[201]
end
get '/api/todo' do
end
end
Esta vez el error es que no se devuelve nada. Podemos arreglarlo fácilmente con esta implementación constante:
# frozen_string_literal: true
require 'sinatra'
require_relative '../../domain/task'
require_relative '../../domain/task_repository'
require_relative '../../application/add_task_handler'
class TodoListApp < Sinatra::Base
def initialize(add_task_handler)
@add_task_handler = add_task_handler
end
post '/api/todo' do
payload = JSON.parse request.body.read.to_s
@add_task_handler.execute payload['task']
[201]
end
get '/api/todo' do
tasks = [
'[ ] 1. Write a test that fails'
]
[200, tasks.to_json]
end
end
Por supuesto, lo suyo sería obtener las tareas del repositorio y generar la respuesta a partir de ahí. Para ello vamos a modificar un poco el test, introduciendo una tarea más y esperando una lista más larga en consecuencia.
# todo_list_acceptance_spec.rb
# frozen_string_literal: true
# ...
RSpec.describe 'As a user I want to' do
before do
@client = build_client
end
it "add a new task to the list" do
@client.post '/api/todo',
{ task: 'Write a test that fails' }.to_json,
{ 'CONTENT_TYPE' => 'application/json' }
expect(@client.last_response.status).to eq(201)
expect(@task_repository.next_id).to eq(2)
end
it 'get a list with all the tasks I\'ve introduced' do
@client.post '/api/todo',
{ task: 'Write a test that fails' }.to_json,
{ 'CONTENT_TYPE' => 'application/json' }
@client.post '/api/todo',
{ task: 'Write Production code that makes the test pass' }.to_json,
{ 'CONTENT_TYPE' => 'application/json' }
@client.get '/api/todo'
expect(@client.last_response.status).to eq(200)
expected_list = [
'[ ] 1. Write a test that fails',
'[ ] 2. Write Production code that makes the test pass'
]
expect(@client.last_response.body).to eq(expected_list.to_json)
end
end
El test fallará porque no coinciden la lista generada y la esperada. Para hacerlo pasar necesitaremos volver a inyectar el repositorio, de modo que podamos recuperar las tareas guardadas.
De momento, podemos hacerlo en el test, pero antes tendríamos que anular este segundo test para volver a verde y hacer los cambios que necesitamos. Este es el test que quedaría:
# todo_list_acceptance_spec.rb
# frozen_string_literal: true
# ...
RSpec.describe 'As a user I want to' do
before do
@client = build_client
end
it "add a new task to the list" do
@client.post '/api/todo',
{ task: 'Write a test that fails' }.to_json,
{ 'CONTENT_TYPE' => 'application/json' }
expect(@client.last_response.status).to eq(201)
expect(@task_repository.next_id).to eq(2)
end
it 'get a list with all the tasks I\'ve introduced' do
@client.post '/api/todo',
{ task: 'Write a test that fails' }.to_json,
{ 'CONTENT_TYPE' => 'application/json' }
# @client.post '/api/todo',
# { task: 'Write Production code that makes the test pass' }.to_json,
# { 'CONTENT_TYPE' => 'application/json' }
@client.get '/api/todo'
expect(@client.last_response.status).to eq(200)
expected_list = [
'[ ] 1. Write a test that fails',
# '[ ] 2. Write Production code that makes the test pass'
]
expect(@client.last_response.body).to eq(expected_list.to_json)
end
end
El código de producción:
# frozen_string_literal: true
require 'sinatra'
require_relative '../../domain/task'
require_relative '../../domain/task_repository'
require_relative '../../application/add_task_handler'
class TodoListApp < Sinatra::Base
def initialize(add_task_handler, task_repository)
@add_task_handler = add_task_handler
@task_repository = task_repository
end
post '/api/todo' do
payload = JSON.parse request.body.read.to_s
@add_task_handler.execute payload['task']
[201]
end
get '/api/todo' do
tasks = [
'[ ] 1. Write a test that fails'
]
[200, tasks.to_json]
end
end
Ahora nos encontramos un par de problemas:
- No tenemos un método en el repositorio para obtener las tareas
- Tenemos que gestionar la transformación de
Tasken su representación
Personalmente, creo que me interesa abordar antes este último. Puestos a devolver una respuesta hard-coded, puedo empezar con la transformación desde el objeto Task y luego ya continuaré el desarrollo de TaskRepository.
De hecho tiene sentido esto como refactor en la situación actual, mientras el test está en verde. Así que vamos a ello:
# frozen_string_literal: true
require 'sinatra'
require_relative '../../domain/task'
require_relative '../../domain/task_repository'
require_relative '../../application/add_task_handler'
class TodoListApp < Sinatra::Base
def initialize(add_task_handler, task_repository)
@add_task_handler = add_task_handler
@task_repository = task_repository
end
post '/api/todo' do
payload = JSON.parse request.body.read.to_s
@add_task_handler.execute payload['task']
[201]
end
get '/api/todo' do
tasks = {
1 => Task.new(1, 'Write a test that fails')
}
representation = tasks.map do |key, task|
"[ ] #{task.id}. #{task.description}"
end
[200, representation.to_json]
end
end
Esta solución es muy sencilla en Ruby y nos permite hacer pasar el test.
Para el siguiente paso necesitaremos implementar el método find_all en el repositorio, por lo que tenemos que cambiar de foco y movernos a su test. De momento, empezamos con un test sencillo:
require 'rspec'
require_relative '../../src/domain/task_repository'
require_relative '../../src/domain/task'
require_relative '../../src/infrastructure/persistence/memory_storage'
describe 'TaskRepository' do
before() do
memory_storage = MemoryStorage.new
@task_repository = TaskRepository.new memory_storage
end
it 'first identity should be 1' do
result = @task_repository.next_id
expect(result).to eq(1)
end
it 'should add a Task' do
task = Task.new 1, 'Task Description'
@task_repository.store task
expect(@task_repository.next_id).to eq(2)
end
it 'should add several tasks' do
@task_repository.store Task.new(1, 'Task Description')
@task_repository.store Task.new(2, 'Another Task')
@task_repository.store Task.new(3, 'Third Task')
expect(@task_repository.next_id).to eq(4)
end
it 'should find all tasks stored' do
@task_repository.store Task.new(1, 'Task Description')
@task_repository.store Task.new(2, 'Another Task')
@task_repository.store Task.new(3, 'Third Task')
expect(@task_repository.find_all.count).to eq(3)
end
end
Para hacerlo pasar necesitamos:
class TaskRepository
def initialize(storage)
@storage = storage
end
def next_id
@storage.next_id
end
def store(task)
@storage.store task
end
def find_all
@storage.find_all
end
end
Y como no está implementado en memory_storage, pues se lo añadimos:
class MemoryStorage
def initialize
@objects = {}
end
def next_id
@objects.count + 1
end
def store(object)
@objects.store object.id, object
end
def find_all
@objects
end
end
Esto hace pasar el test, podríamos añadir aquí tests para verificar que las tareas almacenadas son las que hemos guardado. Después de toquetear un poco:
require 'rspec'
require_relative '../../src/domain/task_repository'
require_relative '../../src/domain/task'
require_relative '../../src/infrastructure/persistence/memory_storage'
describe 'TaskRepository' do
before() do
memory_storage = MemoryStorage.new
@task_repository = TaskRepository.new memory_storage
end
it 'first identity should be 1' do
result = @task_repository.next_id
expect(result).to eq(1)
end
it 'should add a Task' do
task = Task.new 1, 'Task Description'
@task_repository.store task
expect(@task_repository.next_id).to eq(2)
end
it 'should add several tasks' do
@task_repository.store Task.new(1, 'Task Description')
@task_repository.store Task.new(2, 'Another Task')
@task_repository.store Task.new(3, 'Third Task')
expect(@task_repository.next_id).to eq(4)
end
it 'should find all tasks stored' do
examples = [
Task.new(1, 'Task Description'),
Task.new(2, 'Another Task'),
Task.new(3, 'Third Task')
].each { |task| @task_repository.store task }
tasks = @task_repository.find_all
expect(tasks.count).to eq(3)
expect(tasks[1]).to eq(examples[0])
expect(tasks[2]).to eq(examples[1])
expect(tasks[3]).to eq(examples[2])
end
end
Con lo que ya tendríamos lo que necesitamos en el repositorio. Por tanto, podemos introducir su uso en el código de producción después de recuperar el test:
# todo_list_acceptance_spec.rb
# frozen_string_literal: true
# ...
RSpec.describe 'As a user I want to' do
before do
@client = build_client
end
it "add a new task to the list" do
@client.post '/api/todo',
{ task: 'Write a test that fails' }.to_json,
{ 'CONTENT_TYPE' => 'application/json' }
expect(@client.last_response.status).to eq(201)
expect(@task_repository.next_id).to eq(2)
end
it 'get a list with all the tasks I\'ve introduced' do
@client.post '/api/todo',
{ task: 'Write a test that fails' }.to_json,
{ 'CONTENT_TYPE' => 'application/json' }
@client.post '/api/todo',
{ task: 'Write Production code that makes the test pass' }.to_json,
{ 'CONTENT_TYPE' => 'application/json' }
@client.get '/api/todo'
expect(@client.last_response.status).to eq(200)
expected_list = [
'[ ] 1. Write a test that fails',
'[ ] 2. Write Production code that makes the test pass'
]
expect(@client.last_response.body).to eq(expected_list.to_json)
end
end
# frozen_string_literal: true
require 'sinatra'
require_relative '../../domain/task'
require_relative '../../domain/task_repository'
require_relative '../../application/add_task_handler'
class TodoListApp < Sinatra::Base
def initialize(add_task_handler, task_repository)
@add_task_handler = add_task_handler
@task_repository = task_repository
end
post '/api/todo' do
payload = JSON.parse request.body.read.to_s
@add_task_handler.execute payload['task']
[201]
end
get '/api/todo' do
tasks = @task_repository.find_all
representation = tasks.map do |key, task|
"[ ] #{task.id}. #{task.description}"
end
[200, representation.to_json]
end
end
Del mismo modo que hicimos en la historia anterior, ahora sería el momento de extraer la lógica de negocio que contiene el controlador a un caso de uso. Hay que recordar que la condición es que sea el controlador quien decida la representación que necesita.
Seguiremos el mismo procedimiento que antes, extrayendo un método privado con la funcionalidad que vamos a mover al caso de uso. Aquí hemos dado un salto bastante grande de código, implementando la estrategia de transformación mediante un block.
# frozen_string_literal: true
require 'sinatra'
require_relative '../../domain/task'
require_relative '../../domain/task_repository'
require_relative '../../application/add_task_handler'
class TodoListApp < Sinatra::Base
def initialize(add_task_handler, task_repository)
@add_task_handler = add_task_handler
@task_repository = task_repository
end
post '/api/todo' do
payload = JSON.parse request.body.read.to_s
@add_task_handler.execute payload['task']
[201]
end
get '/api/todo' do
tasks = get_tasks_list do |task|
"[ ] #{task.id}. #{task.description}"
end
[200, tasks.to_json]
end
private
def get_tasks_list
tasks = @task_repository.find_all
return tasks unless block_given?
representations = []
tasks.each do |key, task|
representations << yield(task)
end
representations
end
end
Es ahora cuando creamos el caso de uso:
class GetTaskListHandler
def initialize(task_repository)
@task_repository = task_repository
end
def execute
end
end
Y lo usamos dentro del código.
# frozen_string_literal: true
require 'sinatra'
require_relative '../../domain/task'
require_relative '../../domain/task_repository'
require_relative '../../application/add_task_handler'
require_relative '../../application/get_task_list_handler'
class TodoListApp < Sinatra::Base
def initialize(add_task_handler, task_repository)
@add_task_handler = add_task_handler
@task_repository = task_repository
@get_tasks_list_handler = GetTaskListHandler.new task_repository
end
post '/api/todo' do
payload = JSON.parse request.body.read.to_s
@add_task_handler.execute payload['task']
[201]
end
get '/api/todo' do
tasks = @get_tasks_list_handler.execute do |task|
"[ ] #{task.id}. #{task.description}"
end
tasks = get_tasks_list do |task|
"[ ] #{task.id}. #{task.description}"
end
[200, tasks.to_json]
end
private
def get_tasks_list
tasks = @task_repository.find_all
return tasks unless block_given?
representations = []
tasks.each do |key, task|
representations << yield(task)
end
representations
end
end
Con estos cambios el test pasa. La ejecución del caso de uso no tiene ningún efecto en el test, así que vamos a mover el código con los siguientes pasos:
Primero, copiamos el método privado get_tasks_list en el execute del caso de uso:
class GetTaskListHandler
def initialize(task_repository)
@task_repository = task_repository
end
def execute
tasks = @task_repository.find_all
return tasks unless block_given?
representations = []
tasks.each do |key, task|
representations << yield(task)
end
representations
end
end
Ejecutamos el test para asegurarnos de que este cambio no tiene efectos indeseados. Ahora quitamos la llamada al método privado y volvemos a probar:
# frozen_string_literal: true
require 'sinatra'
require_relative '../../domain/task'
require_relative '../../domain/task_repository'
require_relative '../../application/add_task_handler'
require_relative '../../application/get_task_list_handler'
class TodoListApp < Sinatra::Base
def initialize(add_task_handler, task_repository)
@add_task_handler = add_task_handler
@task_repository = task_repository
@get_tasks_list_handler = GetTaskListHandler.new task_repository
end
post '/api/todo' do
payload = JSON.parse request.body.read.to_s
@add_task_handler.execute payload['task']
[201]
end
get '/api/todo' do
tasks = @get_tasks_list_handler.execute do |task|
"[ ] #{task.id}. #{task.description}"
end
[200, tasks.to_json]
end
private
def get_tasks_list
tasks = @task_repository.find_all
return tasks unless block_given?
representations = []
tasks.each do |key, task|
representations << yield(task)
end
representations
end
end
Con esto ya nos aseguramos de que es el caso de uso el que ejecuta la acción y, por tanto, está haciendo que el test siga pasando.
Solo nos queda borrar el método privado.
# frozen_string_literal: true
require 'sinatra'
require_relative '../../domain/task'
require_relative '../../domain/task_repository'
require_relative '../../application/add_task_handler'
require_relative '../../application/get_task_list_handler'
class TodoListApp < Sinatra::Base
def initialize(add_task_handler, task_repository)
@add_task_handler = add_task_handler
@task_repository = task_repository
@get_tasks_list_handler = GetTaskListHandler.new task_repository
end
post '/api/todo' do
payload = JSON.parse request.body.read.to_s
@add_task_handler.execute payload['task']
[201]
end
get '/api/todo' do
tasks = @get_tasks_list_handler.execute do |task|
"[ ] #{task.id}. #{task.description}"
end
[200, tasks.to_json]
end
end
Y ya está. La segunda historia de usuario está implementada. Nos queda todavía un poco de refactor. Vamos a inyectar el caso de uso que acabamos de crear. Por otro lado, dejaremos aún la dependencia de TaskRepository porque es previsible que la necesitemos de nuevo.
# frozen_string_literal: true
require 'sinatra'
require_relative '../../domain/task'
require_relative '../../domain/task_repository'
require_relative '../../application/add_task_handler'
require_relative '../../application/get_task_list_handler'
class TodoListApp < Sinatra::Base
def initialize(add_task_handler, get_tasks_list_handler, task_repository)
@add_task_handler = add_task_handler
@get_tasks_list_handler = get_tasks_list_handler
@task_repository = task_repository
end
post '/api/todo' do
payload = JSON.parse request.body.read.to_s
@add_task_handler.execute payload['task']
[201]
end
get '/api/todo' do
tasks = @get_tasks_list_handler.execute do |task|
"[ ] #{task.id}. #{task.description}"
end
[200, tasks.to_json]
end
end
Y aplicamos esto en el test:
# todo_list_acceptance_spec.rb
# frozen_string_literal: true
# ...
def todo_application
@task_repository = TaskRepository.new MemoryStorage.new
@add_task_handler = AddTaskHandler.new @task_repository
@get_tasks_list_handler = GetTaskListHandler.new @task_repository
TodoListApp.new @add_task_handler, @get_tasks_list_handler, @task_repository
end
# ...
Ruby es bastante conciso, aun así, voy a hacer algún refactor en el test de aceptación extrayendo a métodos las llamadas a la API:
# todo_list_acceptance_spec.rb
# frozen_string_literal: true
# ...
def api_post_task(description)
@client.post '/api/todo',
{ task: description }.to_json,
{ 'CONTENT_TYPE' => 'application/json' }
end
def api_get_tasks
@client.get '/api/todo'
end
RSpec.describe 'As a user I want to' do
before do
@client = build_client
end
it "add a new task to the list" do
api_post_task('Write a test that fails')
expect(@client.last_response.status).to eq(201)
expect(@task_repository.next_id).to eq(2)
end
it 'get a list with all the tasks I\'ve introduced' do
api_post_task('Write a test that fails')
api_post_task('Write Production code that makes the test pass')
api_get_tasks
expect(@client.last_response.status).to eq(200)
expected_list = [
'[ ] 1. Write a test that fails',
'[ ] 2. Write Production code that makes the test pass'
]
expect(@client.last_response.body).to eq(expected_list.to_json)
end
end
Marcar una tarea completada
La última funcionalidad que vamos a implementar es marcar una tarea como completada. Nos toca seguir los pasos que hemos realizado hasta ahora:
- Añadir un ejemplo al test de aceptación
- Implementar la funcionalidad en el controlador
- Extraerla a un caso de uso
Si necesitamos desarrollar algo nuevo en algún objeto, como ha ocurrido con TaskRepository, lo hacemos con el test de aceptación en verde, de modo que luego podamos usarlo sin problemas en el código.
Así que vamos allá. Empecemos con el test de aceptación que, gracias a los refactors anteriores, debería ser fácil de escribir. Aquí está:
# todo_list_acceptance_spec.rb
# frozen_string_literal: true
# ...
def api_post_task(description)
@client.post '/api/todo',
{ task: description }.to_json,
{ 'CONTENT_TYPE' => 'application/json' }
end
def api_get_tasks
@client.get '/api/todo'
end
RSpec.describe 'As a user I want to' do
before do
@client = build_client
end
# ...
it 'mark a task completed' do
api_post_task('Write a test that fails')
api_post_task('Write Production code that makes the test pass')
api_get_tasks
@client.patch '/api/todo/1',
{ completed: true }.to_json,
{ 'CONTENT_TYPE' => 'application/json' }
expect(@client.last_response.status).to eq(200)
expected_list = [
'[√] 1. Write a test that fails',
'[ ] 2. Write Production code that makes the test pass'
]
expect(@client.last_response.body).to eq(expected_list.to_json)
end
end
El principal punto de interés en este test es que vamos a comprobar que ha funcionado recuperando la lista y viendo si ya se representa la tarea como marcada. En muchos aspectos, podríamos considerar que este test sería suficiente para validar toda la funcionalidad de la lista, ya que para llegar al resultado final todas las demás acciones, que hemos desarrollado con otros tests, funcionan.
Así que vamos a empezar a añadir código de producción hasta lograr que el test pase. Por supuesto, el primer problema es que no hay una ruta ni un controlador asociado.
Con este primer paso conseguimos resolver este problema y el fallo del test ya tiene que ver con el contenido de la respuesta.
# frozen_string_literal: true
require 'sinatra'
class TodoListApp < Sinatra::Base
def initialize(add_task_handler, get_tasks_list_handler, task_repository)
@add_task_handler = add_task_handler
@get_tasks_list_handler = get_tasks_list_handler
@task_repository = task_repository
end
#...
patch '/api/todo/:task_id' do | task_id |
[200]
end
end
Este es el error:
1) As a user I want to mark a task completed Failure/Error: expect(@client.last_response.body).to eq(expected_list.to_json) expected: "[\"[√] 1. Write a test that fails\",\"[ ] 2. Write Production code that\ makes the test pass\"]" got: "[\"[ ] 1. Write a test that fails\",\"[ ] 2. Write Production code that\ makes the test pass\"]"Y este error ya es que la tarea completada aparece sin marcar, que es exactamente donde queremos estar.
Una forma de solucionarlo es con este código:
# frozen_string_literal: true
require 'sinatra'
require_relative '../../../src/domain/task'
class TodoListApp < Sinatra::Base
def initialize(add_task_handler, get_tasks_list_handler, task_repository)
@add_task_handler = add_task_handler
@get_tasks_list_handler = get_tasks_list_handler
@task_repository = task_repository
end
post '/api/todo' do
payload = JSON.parse request.body.read.to_s
@add_task_handler.execute payload['task']
[201]
end
get '/api/todo' do
tasks = @get_tasks_list_handler.execute do |task|
"[#{task.id == 1 ? '√' : ' '}] #{task.id}. #{task.description}"
end
[200, tasks.to_json]
end
patch '/api/todo/:task_id' do | task_id |
[200]
end
end
Y este código hace pasar nuestro test actual. Sin embargo, hace fallar el test anterior de obtener todas las tareas, ya que en ese test se asume que no hay ninguna completada.
Por supuesto, lo que necesitamos es que una tarea pueda decir que está completada. Necesitamos añadir algún comportamiento en Task, pero también que los tests de aceptación anteriores pasen. Por tanto, vamos a quitar este test temporalmente, revertir este último cambio y trabajar en añadir en Task la capacidad de ser marcada como completa.
De momento, me basta con anular la última aserción, que es la que controla el cambio de comportamiento en Task:
# todo_list_acceptance_spec.rb
# frozen_string_literal: true
# ...
def api_post_task(description)
@client.post '/api/todo',
{ task: description }.to_json,
{ 'CONTENT_TYPE' => 'application/json' }
end
def api_get_tasks
@client.get '/api/todo'
end
RSpec.describe 'As a user I want to' do
before do
@client = build_client
end
#...
it 'mark a task completed' do
api_post_task('Write a test that fails')
api_post_task('Write Production code that makes the test pass')
@client.patch '/api/todo/1',
{ completed: true }.to_json,
{ 'CONTENT_TYPE' => 'application/json' }
expect(@client.last_response.status).to eq(200)
api_get_tasks
expected_list = [
'[√] 1. Write a test that fails',
'[ ] 2. Write Production code that makes the test pass'
]
# expect(@client.last_response.body).to eq(expected_list.to_json)
end
end
Y también tengo que neutralizar el cambio en el código de producción, temporalmente:
# frozen_string_literal: true
require 'sinatra'
require_relative '../../../src/domain/task'
class TodoListApp < Sinatra::Base
def initialize(add_task_handler, get_tasks_list_handler, task_repository)
@add_task_handler = add_task_handler
@get_tasks_list_handler = get_tasks_list_handler
@task_repository = task_repository
end
post '/api/todo' do
payload = JSON.parse request.body.read.to_s
@add_task_handler.execute payload['task']
[201]
end
get '/api/todo' do
tasks = @get_tasks_list_handler.execute do |task|
"[ ] #{task.id}. #{task.description}"
end
[200, tasks.to_json]
end
patch '/api/todo/:task_id' do | task_id |
[200]
end
end
Vamos a ver entonces cómo marcar tareas completadas:
require 'rspec'
require_relative '../../src/domain/task'
describe 'Task' do
it 'should be incomplete on creation' do
task = Task.new 1, 'Task Description'
expect(task.completed).to be_falsey
end
end
Esto nos basta para introducir la propiedad, iniciarla como false, y exponer un método para acceder a ella.
class Task
attr_reader :description, :id, :completed
def initialize(id, description)
@id = id
@description = description
@completed = false
end
end
Por otra parte, necesitamos poder marcar la tarea como completada:
require 'rspec'
require_relative '../../src/domain/task'
describe 'Task' do
it 'should be incomplete on creation' do
task = Task.new 1, 'Task Description'
expect(task.completed).to be_falsey
end
it 'should be able to be completed' do
task = Task.new 1, 'Task Description'
task.mark_completed
expect(task.completed).to be_truthy
end
end
Lo cual es bastante sencillo de lograr:
class Task
attr_reader :description, :id, :completed
def initialize(id, description)
@id = id
@description = description
@completed = false
end
def mark_completed
@completed = true
end
end
Por esta parte ya tenemos lo que necesitamos.
Ahora, vamos a hacer un refactor para usar algunas de estas capacidades. Con este refactor mantenemos el comportamiento actual y estamos preparados para atender al cambio importante:
# frozen_string_literal: true
require 'sinatra'
require_relative '../../../src/domain/task'
class TodoListApp < Sinatra::Base
def initialize(add_task_handler, get_tasks_list_handler, task_repository)
@add_task_handler = add_task_handler
@get_tasks_list_handler = get_tasks_list_handler
@task_repository = task_repository
end
# ...
get '/api/todo' do
tasks = @get_tasks_list_handler.execute do |task|
"[#{task.completed ? '√' : ' '}] #{task.id}. #{task.description}"
end
[200, tasks.to_json]
end
# ...
end
Así que recuperamos el test:
# todo_list_acceptance_spec.rb
# frozen_string_literal: true
# ...
def api_post_task(description)
@client.post '/api/todo',
{ task: description }.to_json,
{ 'CONTENT_TYPE' => 'application/json' }
end
def api_get_tasks
@client.get '/api/todo'
end
RSpec.describe 'As a user I want to' do
before do
@client = build_client
end
it "add a new task to the list" do
api_post_task('Write a test that fails')
expect(@client.last_response.status).to eq(201)
expect(@task_repository.next_id).to eq(2)
end
it 'get a list with all the tasks I\'ve introduced' do
api_post_task('Write a test that fails')
api_post_task('Write Production code that makes the test pass')
api_get_tasks
expect(@client.last_response.status).to eq(200)
expected_list = [
'[ ] 1. Write a test that fails',
'[ ] 2. Write Production code that makes the test pass'
]
expect(@client.last_response.body).to eq(expected_list.to_json)
end
it 'mark a task completed' do
api_post_task('Write a test that fails')
api_post_task('Write Production code that makes the test pass')
@client.patch '/api/todo/1',
{ completed: true }.to_json,
{ 'CONTENT_TYPE' => 'application/json' }
expect(@client.last_response.status).to eq(200)
api_get_tasks
expected_list = [
'[√] 1. Write a test that fails',
'[ ] 2. Write Production code that makes the test pass'
]
expect(@client.last_response.body).to eq(expected_list.to_json)
end
end
Que falla por el motivo deseado. No deja de tener cierta gracia que nos interese que fallen cosas por una buena razón:
1) As a user I want to mark a task completed Failure/Error: expect(@client.last_response.body).to eq(expected_list.to_json) expected: "[\"[√] 1. Write a test that fails\",\"[ ] 2. Write Production code that\ makes the test pass\"]" got: "[\"[ ] 1. Write a test that fails\",\"[ ] 2. Write Production code that\ makes the test pass\"]"Ahora es cuando implementamos una solución tentativa:
# frozen_string_literal: true
require 'sinatra'
require_relative '../../../src/domain/task'
class TodoListApp < Sinatra::Base
def initialize(add_task_handler, get_tasks_list_handler, task_repository)
@add_task_handler = add_task_handler
@get_tasks_list_handler = get_tasks_list_handler
@task_repository = task_repository
end
# ...
patch '/api/todo/:task_id' do | task_id |
task = Task.new 1, 'Write a test that fails'
task.mark_completed
@task_repository.store task
[200]
end
end
Y esto hace pasar el test. Obviamente, necesitamos recuperar primero la tarea para poder actualizarla, pero es algo que no tenemos todavía en nuestro TaskRepository. Pero como tenemos todos los tests pasando podemos añadir la funcionalidad.
require 'rspec'
require_relative '../../src/domain/task_repository'
require_relative '../../src/domain/task'
require_relative '../../src/infrastructure/persistence/memory_storage'
describe 'TaskRepository' do
before() do
memory_storage = MemoryStorage.new
@task_repository = TaskRepository.new memory_storage
end
# ...
it 'should retrieve a task by id' do
examples = [
Task.new(1, 'Task Description'),
Task.new(2, 'Another Task'),
Task.new(3, 'Third Task')
].each { |task| @task_repository.store task }
task = @task_repository.retrieve 1
expect(task).to eq(examples[0])
end
end
Lo implementamos así:
class TaskRepository
def initialize(storage)
@storage = storage
end
def next_id
@storage.next_id
end
def store(task)
@storage.store task
end
def find_all
@storage.find_all
end
def retrieve(task_id)
@storage.retrieve task_id
end
end
Junto con:
class MemoryStorage
def initialize
@objects = {}
end
def next_id
@objects.count + 1
end
def store(object)
@objects.store object.id, object
end
def find_all
@objects
end
def retrieve(object_id)
@objects[object_id]
end
end
Ahora posamos usarlo en nuestra implementación, reemplazando la asignación directa de task, que tenemos ahora.
# frozen_string_literal: true
require 'sinatra'
require_relative '../../../src/domain/task'
class TodoListApp < Sinatra::Base
def initialize(add_task_handler, get_tasks_list_handler, task_repository)
@add_task_handler = add_task_handler
@get_tasks_list_handler = get_tasks_list_handler
@task_repository = task_repository
end
post '/api/todo' do
payload = JSON.parse request.body.read.to_s
@add_task_handler.execute payload['task']
[201]
end
get '/api/todo' do
tasks = @get_tasks_list_handler.execute do |task|
"[#{task.completed ? '√' : ' '}] #{task.id}. #{task.description}"
end
[200, tasks.to_json]
end
patch '/api/todo/:task_id' do | task_id |
task = @task_repository.retrieve task_id
task.mark_completed
@task_repository.store task
[200]
end
end
Y ya casi estamos. El test de aceptación sigue pasando. Lo único que nos queda es introducir el caso de uso, para lo que seguimos el proceso de refactor que ya conocemos. Primero extraemos la funcionalidad a un método privado.
# frozen_string_literal: true
require 'sinatra'
require_relative '../../../src/domain/task'
class TodoListApp < Sinatra::Base
def initialize(add_task_handler, get_tasks_list_handler, task_repository)
@add_task_handler = add_task_handler
@get_tasks_list_handler = get_tasks_list_handler
@task_repository = task_repository
end
# ...
patch '/api/todo/:task_id' do | task_id |
mark_task_completed task_id
[200]
end
def self.mark_task_completed(task_id)
task = @task_repository.retrieve task_id
task.mark_completed
@task_repository.store task
end
end
Introducimos la nueva clase, que simplemente usa el mismo código que ya está testado.
class MarkTaskCompletedHandler
def initialize(task_repository)
@task_repository = task_repository
end
def execute(task_id)
task = @task_repository.retrieve task_id
task.mark_completed
@task_repository.store task
end
end
Y ahora, introducimos su uso. Como esta acción es idempotente, podemos hacer esto de modo que probamos si funciona antes de eliminar el código que hemos movido:
# frozen_string_literal: true
require 'sinatra'
require_relative '../../../src/domain/task'
class TodoListApp < Sinatra::Base
def initialize(add_task_handler, get_tasks_list_handler, task_repository)
@add_task_handler = add_task_handler
@get_tasks_list_handler = get_tasks_list_handler
@task_repository = task_repository
end
# ...
patch '/api/todo/:task_id' do | task_id |
mark_task_completed task_id
@mark_task_completed = MarkTaskCompletedHandler.new @task_repository
@mark_task_completed.execute task_id
[200]
end
# ...
end
Y el test sigue pasando, como era de esperar. Así que podemos eliminar el método extraído antes. Después tendremos que cambiar la construcción para inyectar el caso de uso. Pero vamos por partes:
# frozen_string_literal: true
require 'sinatra'
require_relative '../../../src/domain/task'
class TodoListApp < Sinatra::Base
def initialize(add_task_handler, get_tasks_list_handler, task_repository)
@add_task_handler = add_task_handler
@get_tasks_list_handler = get_tasks_list_handler
@mark_task_completed = MarkTaskCompletedHandler.new @task_repository
@task_repository = task_repository
end
post '/api/todo' do
payload = JSON.parse request.body.read.to_s
@add_task_handler.execute payload['task']
[201]
end
get '/api/todo' do
tasks = @get_tasks_list_handler.execute do |task|
"[#{task.completed ? '√' : ' '}] #{task.id}. #{task.description}"
end
[200, tasks.to_json]
end
patch '/api/todo/:task_id' do | task_id |
@mark_task_completed.execute task_id
[200]
end
end
El cambio de la construcción lo vamos a dirigir desde el test, iniciando la aplicación con los servicios que realmente necesita
# todo_list_acceptance_spec.rb
# frozen_string_literal: true
# ...
def todo_application
@task_repository = TaskRepository.new MemoryStorage.new
@add_task_handler = AddTaskHandler.new @task_repository
@get_tasks_list_handler = GetTaskListHandler.new @task_repository
@mark_task_completed = MarkTaskCompletedHandler.new @task_repository
TodoListApp.new @add_task_handler, @get_tasks_list_handler, @mark_task_completed
end
# ...
Los test fallarán estrepitosamente, pero el cambio es fácil de aplicar. Así queda la aplicación:
# frozen_string_literal: true
require 'sinatra'
require_relative '../../../src/domain/task'
class TodoListApp < Sinatra::Base
def initialize(add_task_handler, get_tasks_list_handler, mark_task_completed)
@add_task_handler = add_task_handler
@get_tasks_list_handler = get_tasks_list_handler
@mark_task_completed = mark_task_completed
end
post '/api/todo' do
payload = JSON.parse request.body.read.to_s
@add_task_handler.execute payload['task']
[201]
end
get '/api/todo' do
tasks = @get_tasks_list_handler.execute do |task|
"[#{task.completed ? '√' : ' '}] #{task.id}. #{task.description}"
end
[200, tasks.to_json]
end
patch '/api/todo/:task_id' do | task_id |
@mark_task_completed.execute task_id
[200]
end
end
Qué hemos aprendido con esta kata
- Es perfectamente posible aplicar un enfoque outside-in con la metodología clásica de TDD.
- La modalidad outside-in clásica require que tengamos los tests en verde para introducir el diseño porque lo hacemos en la fase de refactor.
- En algunos momentos podríamos necesitar dobles de test, aunque preferiremos usar implementaciones fake o específicas para test (como los repositorios en memoria), o en su caso stubs antes que mocks.
TDD en la vida real
En esta parte nos ocuparemos de cómo es posible incorporar TDD en todos los procesos de desarrollo en proyectos reales.
Trabajaremos en un proyecto para crear el backend de una aplicación de lista de tareas sencilla. La misma que hemos usado en el ejemplo de outside-in. Pero esta vez tendremos un punto de partida ligeramente distinto, con el proyecto organizado mediante historias de usuario.
El segundo capítulo de esta parte nos mostrará cómo trabajar cuando tenemos que solucionar un bug, desde la forma de reproducirlo a los pasos que tendremos que ir dando para solucionarlo.
El tercer capítulo trata sobre la implementación de nuevas historias de usuario en el sistema.
23 Lista de tareas, outside-in TDD por historias de usuario
En esta versión del mismo ejercicio de crear una aplicación usando TDD trabajaremos con el proyecto organizado en historias de usuario. Esto es: hemos dividido el proyecto en funcionalidades que aporten valor. El objetivo es mostrar una metodología de trabajo que podríamos llevar a la práctica en proyectos reales.
Este proyecto también lo haremos en PHP, usando PHPUnit y algunos componentes del framework Symfony. La resolución es un poco diferente a la que hicimos en un capítulo anterior, porque esta vez limitaremos el alcance de nuestro trabajo a la historia de usuario, lo que impone algunas restricciones que antes no se presentaban.
Añadir tareas a una lista
Repasemos la definición.
US 1
- As a User
- I want to add tasks to a to-do list
- So that, I can organize my tasks
Para completar esta historia de usuario necesitaremos, aparte de un endpoint al que poder llamar y un controlador que lo gestione, un caso de uso para añadir tareas a la lista y un repositorio en el que guardarlas. Nuestro caso de uso va a ser un command, por lo que el resultado de la acción será una llamada al repositorio guardando cada nueva tarea.
Para poder verificar esto en un test no queremos escribir código que no vaya a ser necesario en producción. Por ejemplo, no vamos a desarrollar métodos (todavía) para recuperar información del repositorio. Estrictamente hablando, de momento no sabemos siquiera si las vamos a necesitar (spoiler: sí, pero eso sería programar para un futuro que aún no conocemos). Así que, inicialmente, usaremos un mock del repositorio y verificaremos que se hacen las llamadas adecuadas.
Una vez que tenemos esto claro, escribimos un test que enviará un POST al endpoint para crear una tarea nueva y verificará que, en algún momento, estamos llamando a un repositorio de tareas, confiando en que la implementación real lo gestionará correctamente cuando esté disponible.
Suele ser buena idea, empezar el test por el final, es decir, por lo que esperamos, y construir el resto con las acciones necesarias. En este caso, esperamos la existencia de un TaskRepository, que será una interfaz por el momento. También introducimos el concepto de Task.
namespace App\Tests\Katas\TodoList;
use Symfony\Bundle\FrameworkBundle\Test\WebTestCase;
class TodoListAcceptanceTest extends WebTestCase
{
/** @test */
public function asUserIWantToAddTaskToAToDoList(): void
{
$taskRepository = $this->createMock(TaskRepository::class);
$task = new Task(1, 'Write a test that fails');
$taskRepository
->expects(self::once())
->method('store')
->with($task);
$client = self::createClient();
$client->getContainer()->set(TaskRepository::class, $taskRepository);
$client->request(
'POST',
'/api/todo',
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['task' => 'Write a test that fails'], JSON_THROW_ON_ERROR)
);
}
protected function setUp(): void
{
$this->resetRepositoryData();
}
protected function tearDown(): void
{
$this->resetRepositoryData();
}
private function resetRepositoryData(): void
{
if (file_exists('repository.data')) {
unlink('repository.data');
}
}
}
Tendremos que ejecutar el test e implementar todo lo que nos vaya pidiendo hasta lograr que falle por la razón adecuada.
El primer mensaje de error es que no tenemos definido TaskRepository, así que empezamos por ahí:
Cannot stub or mock class or interface "App\Tests\Katas\TodoList\TaskRepository" which do\
es not exist
Este error en concreto es específico de PHP y PHPUnit. En otros lenguajes podrías encontrar un error diferente.
De momento mi solución es iniciarlo en el mismo test, si el mensaje de error cambia, entonces lo moveré a su propio archivo.
interface TaskRepository
{
}
El test ahora falla por una razón diferente, así que hemos pasado este escollo. Usamos el refactor Move Class para poner TaskRepository en App\TodoList\Domain\TaskRepository y lanzamos nuevamente los tests, obteniendo el siguiente error, que es:
Error : Class 'App\Tests\Katas\TodoList\Task' not found
Que nos está diciendo que no hemos definido la clase Task. De momento, crearemos Task en el mismo archivo, relanzando el test para ver si cambia el error.
class Task
{
}
Ahora el error nos indica que no existe un método store en TaskRepository, por lo que no se puede mockear. Tenemos que introducirlo, pero antes, moveremos Task a su lugar en App\TodoList\Domain. Como puedes ver, estamos organizando el código conforme a una arquitectura en capas.
Tras mover Task, añadimos el método store en TaskRepository:
namespace App\TodoList\Domain;
interface TaskRepository
{
public function store(Task $task): void;
}
El siguiente error es algo más extraño:
Symfony\Component\Config\Exception\LoaderLoadException : The file "../src/Controller" doe\
s not exist
(in: /application/config) in /application/config/services.yaml
(which is loaded in resource "/application/config/services.yaml").
Tiene que ver con la configuración de Symfony, el framework de PHP que estamos usando para este ejercicio. Este mensaje nos indica que no hay archivos que contengan controladores en el path y namespace indicados. De hecho, yo tampoco no los quiero ahí, sino en App\TodoList\Infrastructure\EntryPoint\Api. Esto es porque quiero mantener esa arquitectura limpia, con los componentes organizados en capas. Los controladores y los puntos de entrada a la aplicación están en la capa de infraestructura, dentro de una categoría EntryPoint que, en este caso, tiene un “puerto” relacionado con la comunicación mediante Api.
Para lograr esto, no tenemos más que ir al archivo config/services.yaml y cambiar lo necesario:
# controllers are imported separately to make sure services can be injected
# as action arguments even if you don't extend any base controller class
App\TodoList\Infrastructure\EntryPoint\Api\:
resource: '../src/TodoList/Infrastructure/EntryPoint/Api'
tags: ['controller.service_arguments']
Al ejecutar el test, tendremos un error semejante:
Symfony\Component\Config\Exception\LoaderLoadException : The file "../src/TodoList/Infras\
tructure/EntryPoint/Api"
does not exist (in: /application/config) in /application/config/services.yaml
(which is loaded in resource "/application/config/services.yaml").
Es positivo porque refleja que hemos hecho el cambio de services.yaml correctamente, pero aún no hemos añadido un controlador en la ubicación deseada que se pueda cargar y evitar el error. Así que añadimos un archivo TodoListController, en la ubicación definida.
namespace App\TodoList\Infrastructure\EntryPoint\Api;
class TodoListController
{
}
Al ejecutar el test obtenemos dos nuevos mensajes de error. Por un lado:
"No route found for "POST /api/todo""
Nos indica un problema en el framework, ya que el cliente HTTP del test está llamando a un endpoint que aún no hemos definido en ninguna parte. Lo resolvemos configurando lo necesario en routes.yaml:
api_add_task:
path: /api/todo
controller: App\TodoList\Infrastructure\EntryPoint\Api\TodoListController::addTask
methods: ['POST']
Como hacemos después de un cambio, ejecutamos el test, que ahora se quejará de que no existe un método en el controlador encargado de responder a este endpoint.
"The controller for URI "/api/todo" is not callable.
Expected method "addTask" on class "App\TodoList\Infrastructure\EntryPoint\Api\TodoListCo\
ntroller"...
Lo implementamos así:
namespace App\TodoList\Infrastructure\EntryPoint\Api;
class TodoListController
{
public function addTask()
{
throw new \RuntimeException(sprintf('Implement %s', __METHOD__));
}
}
Es una simple línea que lanza una excepción para indicar que el método no está implementado. Esto lo hacemos para que el propio test nos indique que tenemos algo sin implementar. En este caso concreto, un cuerpo vacío no nos indicaría nada y, en muchos casos, sería fácil perder la pista de lo que tenemos pendiente de escribir.
De hecho, si lanzamos el test nos indica justamente ese error.
Pero también este otro, que es propio del test:
Expectation failed for method name is equal to 'store' when invoked 1 time(s).
Method was expected to be called 1 times, actually called 0 times.
Este error es el que esperaríamos del test tal como lo hemos definido. Ya no hay errores de configuración del framework. Nos dice que nunca llega a intentarse guardar una Task en el repositorio, que es como decir, que no hay código de producción que haga lo que deseamos.
Estos dos errores juntos nos indican momento de implementar.
Y para hacerlo, necesitamos avanzar un paso hacia el interior de nuestra aplicación, que en nuestro ejemplo es TodoListController. En este punto abandonamos el ciclo del test de aceptación y entramos en un ciclo de test unitarios para desarrollar TodoListController::addTask.
Diseñando en rojo
El test de aceptación no está pasando, y nos está pidiendo que implementemos algo en TodoListController. Para hacerlo, lo que vamos a hacer es pensar cómo queremos que sea el controlador y si delegará en otros objetos el trabajo.
En particular, queremos que el controlador sea una capa muy fina que se encargue de:
- Obtener la información necesaria de la request
- Pasársela a un caso de uso para que haga lo que sea necesario
- Obtener la respuesta del caso de uso y enviarla como respuesta del endpoint
En un enfoque clásico, implementaríamos la solución completa en el controlador y luego iríamos moviendo la lógica a los componentes necesarios.
En lugar de eso, en el enfoque mockista, diseñamos cómo va a ser ese nivel de implementación y usamos dobles para los colaboradores que vayamos necesitando. Por ejemplo, este es nuestro test:
namespace App\Tests\TodoList\Infrastructure\EntryPoint\Api;
use App\TodoList\Infrastructure\EntryPoint\Api\TodoListController;
use PHPUnit\Framework\TestCase;
use Symfony\Component\HttpFoundation\Request;
class TodoListControllerTest extends TestCase
{
/** @test */
public function shouldAddTask(): void
{
$addTaskHandler = $this->createMock(AddTaskHandler::class);
$addTaskHandler
->expects(self::once())
->method('execute')
->with('Task Description');
$todoListController = new TodoListController($addTaskHandler);
$request = new Request(
[],
[],
[],
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['task' => 'Task Description'], JSON_THROW_ON_ERROR)
);
$response = $todoListController->addTask($request);
self::assertEquals(201, $response->getStatusCode());
}
}
En este test se verifican dos cosas. Por un lado, que devolvemos una respuesta con código 201 (recurso creado) y que tendremos un caso de uso llamado AddTaskHandler que se encarga de procesar la creación de la tarea a partir de su descripción, que recibe como payload en la request.
Al ejecutar el test, empezamos a obtener los errores esperados. El primero es que no tenemos ningún AddTaskHandler. De nuevo, empezaré añadiéndolo en el archivo del test y lo moveré en el siguiente paso. De hecho, es literalmente lo que indica el error:
Así que, añadimos:
class AddTaskHandler
{
}
Al ejecutar ahora el test, nos pide incorporar el método execute, que aún no está definido. Antes de añadirlo, vamos a mover AddTaskHandler, que es el caso de uso, a su lugar en la capa de aplicación: App\TodoList\Application. A continuación, añadimos el método incluyendo nuestra excepción de no implementado.
namespace App\TodoList\Application;
class AddTaskHandler
{
public function execute(): void
{
throw new \RuntimeException(sprintf('Implement %s', __METHOD__));
}
}
De este modo, lo que ocurrirá es lo siguiente: una vez que hayamos implementado el controlador, veremos que su test unitario pasa, puesto que estamos usando el doble de AddTaskHandler y no llamamos al código real. Esto ocurrirá al lanzar el test de aceptación, lo que nos estará indicando que deberíamos implementar AddTaskHandler y profundizar un nivel más en la aplicación.
El siguiente fallo es conocido:
RuntimeException : Implement App\TodoList\Infrastructure\EntryPoint\Api\TodoListControlle\
r::addTask
Lo que nos indica que el test ya está llamando al método addTask, que aún no está implementado. Es justo donde queríamos estar. En TodoListController::addTask implementaremos lógica que haga pasar el test:
namespace App\TodoList\Infrastructure\EntryPoint\Api;
use App\TodoList\Application\AddTaskHandler;
use Symfony\Component\HttpFoundation\JsonResponse;
use Symfony\Component\HttpFoundation\Request;
use Symfony\Component\HttpFoundation\Response;
class TodoListController
{
/** @var AddTaskHandler */
private AddTaskHandler $addTaskHandler;
public function __construct(AddTaskHandler $addTaskHandler)
{
$this->addTaskHandler = $addTaskHandler;
}
public function addTask(Request $request): Response
{
$payload = json_decode($request->getContent(), true, 512, JSON_THROW_ON_ERROR);
$this->addTaskHandler->execute($payload['task']);
return new JsonResponse('', Response::HTTP_CREATED);
}
}
¡El test pasa!
Podríamos haber ido más despacio aquí para dirigir la implementación con pasos más pequeños, pero creo que es mejor hacerlo en uno solo porque la lógica no es muy compleja y así no nos vamos mucho por las ramas. Lo importante, en todo caso, es que hemos cumplido con el objetivo de desarrollar este controlador con un test unitario que ahora mismo pasa.
Como el test unitario ya pasa, no tenemos más que hacer en este nivel. En todo caso, voy a hacer un pequeño refactor para ocultar los detalles de la obtención del payload de la request, lo que deja el cuerpo del controlador un poco más limpio y fácil de seguir.
namespace App\TodoList\Infrastructure\EntryPoint\Api;
use App\TodoList\Application\AddTaskHandler;
use Symfony\Component\HttpFoundation\JsonResponse;
use Symfony\Component\HttpFoundation\Request;
use Symfony\Component\HttpFoundation\Response;
class TodoListController
{
/** @var AddTaskHandler */
private AddTaskHandler $addTaskHandler;
public function __construct(AddTaskHandler $addTaskHandler)
{
$this->addTaskHandler = $addTaskHandler;
}
public function addTask(Request $request): Response
{
$payload = $this->obtainPayload($request);
$this->addTaskHandler->execute($payload['task']);
return new JsonResponse('', Response::HTTP_CREATED);
}
private function obtainPayload(Request $request): array
{
return json_decode($request->getContent(), true, 512, JSON_THROW_ON_ERROR);
}
}
Volviendo al test de aceptación
Una vez que hemos hecho pasar el test unitario, tenemos que volver al nivel de aceptación para que nos diga como seguir. Lo ejecutamos y obtenemos lo siguiente:
Ahora nos toca internarnos un poco más en la aplicación y movernos al caso de uso AddTaskHandler. Lo que esperamos de este UseCase es que use la información recibida para crear una tarea y la guarde en TaskRepository.
Para crear una tarea, necesitaremos asignarle un ID, el cual le vamos a pedir al propio repositorio que tendrá un método a propósito.
Esto lo podemos expresar con el siguiente test unitario.
namespace App\Tests\TodoList\Application;
use App\TodoList\Application\AddTaskHandler;
use App\TodoList\Domain\Task;
use App\TodoList\Domain\TaskRepository;
use PHPUnit\Framework\TestCase;
class AddTaskHandlerTest extends TestCase
{
/** @test */
public function shouldCreateAndStoreATask(): void
{
$task = new Task(1, 'Task Description');
$taskRepository = $this->createMock(TaskRepository::class);
$taskRepository
->method('nextIdentity')
->willReturn(1);
$taskRepository
->expects(self::once())
->method('store')
->with($task);
$addTaskHandler = new AddTaskHandler($taskRepository);
$addTaskHandler->execute('Task Description');
}
}
Ejecutamos el test. Obtenemos primero este error:
Añadimos el método en la interfaz:
namespace App\TodoList\Domain;
interface TaskRepository
{
public function store(Task $task): void;
public function nextIdentity(): int;
}
Lo que genera este error:
RuntimeException : Implement App\TodoList\Application\AddTaskHandler::App\TodoList\Applic\
ation\AddTaskHandler::execute
Y estamos listos para implementar el caso de uso. Este código debería bastar:
namespace App\TodoList\Application;
use App\TodoList\Domain\Task;
use App\TodoList\Domain\TaskRepository;
class AddTaskHandler
{
/** @var TaskRepository */
private TaskRepository $taskRepository;
public function __construct(TaskRepository $taskRepository)
{
$this->taskRepository = $taskRepository;
}
public function execute(string $taskDescription): void
{
$id = $this->taskRepository->nextIdentity();
$task = new Task($id, $taskDescription);
$this->taskRepository->store($task);
}
}
El código es suficiente para hacer pasar el test, por lo que podemos volver al nivel de aceptación.
Nuevo ciclo
Al relanzar el test de aceptación nos encontramos que este pasa. Sin embargo, la historia de usuario no está implementada aún, ya que no tenemos un repositorio concreto en el que se estén guardando Task. De hecho, nuestras clases Task no tienen ningún código todavía.
El motivo es que estamos usando un mock de TaskRepository en el test de aceptación. Nos interesaría dejar de usarlo para que TodoList utilice una implementación concreta. El problema que tendríamos ahora es que de momento no vamos a tener métodos con los que explorar el contenido del repositorio y verificar el test. Vamos a hacer esto en dos fases.
En la primera simplemente eliminamos el uso del mock y verificamos que la respuesta del API devuelve el código 201 (created).
namespace App\Tests\Katas\TodoList;
use App\TodoList\Domain\Task;
use App\TodoList\Domain\TaskRepository;
use Symfony\Bundle\FrameworkBundle\Test\WebTestCase;
use Symfony\Component\HttpFoundation\Response;
class TodoListAcceptanceTest extends WebTestCase
{
/** @test */
public function asUserIWantToAddTaskToAToDoList(): void
{
$client = self::createClient();
$client->request(
'POST',
'/api/todo',
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['task' => 'Write a test that fails'], JSON_THROW_ON_ERROR)
);
$response = $client->getResponse();
self::assertEquals(Response::HTTP_CREATED, $response->getStatusCode());
}
protected function setUp(): void
{
$this->resetRepositoryData();
}
protected function tearDown(): void
{
$this->resetRepositoryData();
}
private function resetRepositoryData(): void
{
if (file_exists('repository.data')) {
unlink('repository.data');
}
}
}
Antes de continuar, tenemos que eliminar la definición del servicio que hicimos antes en services_test.yaml. Como es el único que tenemos declarado aquí, podemos eliminar el archivo sin problema.
Y al ejecutar el test, nos aparece el siguiente error del framework:
Cannot autowire service "App\TodoList\Application\AddTaskHandler": argument "$taskReposit\
ory" of method "__construct()"
Esto ocurre porque solo tenemos una interfaz de TaskRepository y necesitaríamos una implementación concreta que usar. De este modo, tenemos un error que nos permite avanzar en el desarrollo. Necesitaremos un test para implementar FileTaskRepository, un repositorio basado en un sencillo archivo de texto para guardar los objetos serializados:
namespace App\Lib;
class FileStorageEngine
{
private string $filePath;
public function __construct($filePath)
{
$this->filePath = $filePath;
}
public function loadObjects(string $class): array
{
if (!file_exists($this->filePath)) {
return [];
}
$file = fopen($this->filePath, 'rb');
$objects = unserialize(fgets($file), ['allowed_classes' => [$class]]);
fclose($file);
return $objects;
}
public function persistObjects(array $objects): void
{
$file = fopen($this->filePath, 'wb');
fwrite($file, serialize($objects));
fclose($file);
}
}
En primer lugar, vamos a crear una implementación por defecto para FileTaskRepository en su lugar, que será App\TodoList\Infrastructure\Persistence:
namespace App\TodoList\Infrastructure\Persistence;
use App\TodoList\Domain\Task;
use App\TodoList\Domain\TaskRepository;
class FileTaskRepository implements TaskRepository
{
public function store(Task $task): void
{
throw new \RuntimeException('Implement store() method.');
}
public function nextIdentity(): int
{
throw new \RuntimeException('Implement nextIdentity() method.');
}
}
Al volver a ejecutar el test de aceptación se producen dos errores. Uno nos dice que tenemos que implementar el método nextIdentity del repositorio. El otro, que es un error propio del test, nos informa de que el endpoint devuelve el código 500 en lugar de 201. Es lógico porque la implementación que tenemos ahora de FileTaskRepository fallará de forma fatal.
Pero es una buena noticia, porque nos dice por dónde seguir. Así que crearemos un nuevo test unitario para guiar el desarrollo de FileTaskRepository. En este test simulamos distinto número de objetos en el almacenamiento para asegurar la implementación correcta.
namespace App\Tests\TodoList\Infrastructure\Persistence;
use App\Lib\FileStorageEngine;
use App\TodoList\Infrastructure\Persistence\FileTaskRepository;
use PHPUnit\Framework\TestCase;
class FileTaskRepositoryTest extends TestCase
{
/** @test */
public function shouldProvideNextIdentityCountingExistingObjects(): void
{
$storageEngine = $this->createMock(FileStorageEngine::class);
$taskRepository = new FileTaskRepository($storageEngine);
$storageEngine
->method('loadObjects')
->willReturn(
[],
['Task'],
['Task', 'Task']
);
self::assertEquals(1, $taskRepository->nextIdentity());
self::assertEquals(2, $taskRepository->nextIdentity());
self::assertEquals(3, $taskRepository->nextIdentity());
}
}
Con este test pasando, volvemos al test de aceptación, que vuelve a fallar. El endpoint devuelve un error 500 porque no tenemos una implementación del método store en FileTaskRepository.
Introduciremos un nuevo test, aunque antes lo hemos refactorizado un poco a fin de que sea más fácil introducir los cambios:
namespace App\Tests\TodoList\Infrastructure\Persistence;
use App\Lib\FileStorageEngine;
use App\TodoList\Domain\Task;
use App\TodoList\Domain\TaskRepository;
use App\TodoList\Infrastructure\Persistence\FileTaskRepository;
use PHPUnit\Framework\TestCase;
class FileTaskRepositoryTest extends TestCase
{
private FileStorageEngine $fileStorageEngine;
private TaskRepository $taskRepository;
public function setUp(): void
{
$this->fileStorageEngine = $this->createMock(FileStorageEngine::class);
$this->taskRepository = new FileTaskRepository($this->fileStorageEngine);
}
/** @test */
public function shouldProvideNextIdentityCountingExistingObjects(): void
{
$this->fileStorageEngine
->method('loadObjects')
->willReturn(
[],
['Task'],
['Task', 'Task']
);
self::assertEquals(1, $this->taskRepository->nextIdentity());
self::assertEquals(2, $this->taskRepository->nextIdentity());
self::assertEquals(3, $this->taskRepository->nextIdentity());
}
/** @test */
public function shouldStoreATask(): void
{
$task = new Task(1, 'Task Description');
$this->fileStorageEngine
->method('loadObjects')
->willReturn([]);
$this->fileStorageEngine
->expects(self::once())
->method('persistObjects')
->with([1 => $task]);
$this->taskRepository->store($task);
}
}
Esta es nuestra implementación para pasar el test:
namespace App\TodoList\Infrastructure\Persistence;
use App\Lib\FileStorageEngine;
use App\TodoList\Domain\Task;
use App\TodoList\Domain\TaskRepository;
class FileTaskRepository implements TaskRepository
{
/** @var FileStorageEngine */
private FileStorageEngine $fileStorageEngine;
public function __construct(FileStorageEngine $fileStorageEngine)
{
$this->fileStorageEngine = $fileStorageEngine;
}
public function store(Task $task): void
{
$tasks = $this->fileStorageEngine->loadObjects(Task::class);
$tasks[$task->id()] = $task;
$this->fileStorageEngine->persistObjects($tasks);
}
public function nextIdentity(): int
{
$tasks = $this->fileStorageEngine->loadObjects(Task::class);
return count($tasks) + 1;
}
}
Tenemos que implementar el método Task::id, lo que nos hace introducir también un constructor:
namespace App\TodoList\Domain;
class Task
{
private int $id;
private string $description;
public function __construct(int $id, string $description)
{
$this->id = $id;
$this->description = $description;
}
public function id(): int
{
return $this->id;
}
}
La implementación hace pasar el test. Para no alargarnos no introduciré más ejemplos, que sería lo propio para tener más confianza en el comportamiento del test. Pero de momento nos vale para entender el proceso.
Como estamos en verde, volvemos al test de aceptación para comprobar qué avances hemos tenido. Y al ejecutarlo, el test de aceptación pasa, indicando que la feature está completa. O casi, ya que por el momento no tenemos forma de saber si las tareas se han almacenado o no.
Una posibilidad es obtener el contenido de FileStorageEngine y ver si allí se encuentran nuestras tareas. No nos obliga a implementar nada en el código de producción:
namespace App\Tests\Katas\TodoList;
use App\Lib\FileStorageEngine;
use App\TodoList\Domain\Task;
use Symfony\Bundle\FrameworkBundle\Test\WebTestCase;
use Symfony\Component\HttpFoundation\Response;
class TodoListAcceptanceTest extends WebTestCase
{
/** @test */
public function asUserIWantToAddTaskToAToDoList(): void
{
$client = self::createClient();
$client->request(
'POST',
'/api/todo',
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['task' => 'Write a test that fails'], JSON_THROW_ON_ERROR)
);
$response = $client->getResponse();
self::assertEquals(Response::HTTP_CREATED, $response->getStatusCode());
$storage = new FileStorageEngine('repository.data');
$tasks = $storage->loadObjects(Task::class);
self::assertCount(1, $tasks);
self::assertEquals(1, $tasks[1]->id());
}
protected function setUp(): void
{
$this->resetRepositoryData();
}
protected function tearDown(): void
{
$this->resetRepositoryData();
}
private function resetRepositoryData(): void
{
if (file_exists('repository.data')) {
unlink('repository.data');
}
}
}
El test verifica que hemos guardado una tarea en el repositorio, confirmando que la primera historia de usuario está implementada. Puede ser buen momento para examinar lo que hemos hecho y ver si podemos hacer algún refactor que pueda facilitar los siguientes pasos del desarrollo.
Empecemos con el test de aceptación:
namespace App\Tests\Katas\TodoList;
use App\Lib\FileStorageEngine;
use App\TodoList\Domain\Task;
use Symfony\Bundle\FrameworkBundle\Client;
use Symfony\Bundle\FrameworkBundle\Test\WebTestCase;
use Symfony\Component\HttpFoundation\Response;
class TodoListAcceptanceTest extends WebTestCase
{
private Client $client;
/** @test */
public function asUserIWantToAddTaskToAToDoList(): void
{
$response = $this->whenWeRequestToCreateATaskWithDescription('Write a test that f\
ails');
$this->thenResponseShouldBeSuccesful($response);
$this->thenTheTaskIsStored();
}
protected function setUp(): void
{
$this->resetRepositoryData();
$this->client = self::createClient();
}
protected function tearDown(): void
{
$this->resetRepositoryData();
}
private function resetRepositoryData(): void
{
if (file_exists('repository.data')) {
unlink('repository.data');
}
}
private function whenWeRequestToCreateATaskWithDescription(string $taskDescription): \
Response
{
$this->client->request(
'POST',
'/api/todo',
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['task' => $taskDescription], JSON_THROW_ON_ERROR)
);
return $this->client->getResponse();
}
private function thenResponseShouldBeSuccesful(Response $response): void
{
self::assertEquals(Response::HTTP_CREATED, $response->getStatusCode());
}
private function thenTheTaskIsStored(): void
{
$storage = new FileStorageEngine('repository.data');
$tasks = $storage->loadObjects(Task::class);
self::assertCount(1, $tasks);
self::assertEquals(1, $tasks[1]->id());
}
}
TodoListControllerTest:
namespace App\Tests\TodoList\Infrastructure\EntryPoint\Api;
use App\TodoList\Application\AddTaskHandler;
use App\TodoList\Infrastructure\EntryPoint\Api\TodoListController;
use PHPUnit\Framework\TestCase;
use Symfony\Component\HttpFoundation\Request;
class TodoListControllerTest extends TestCase
{
private const TASK_DESCRIPTION = 'Task Description';
private AddTaskHandler $addTaskHandler;
private TodoListController $todoListController;
protected function setUp(): void
{
$this->addTaskHandler = $this->createMock(AddTaskHandler::class);
$this->todoListController = new TodoListController($this->addTaskHandler);
}
/** @test */
public function shouldAddTask(): void
{
$this->addTaskHandler
->expects(self::once())
->method('execute')
->with(self::TASK_DESCRIPTION);
$request = new Request(
[],
[],
[],
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['task' => self::TASK_DESCRIPTION], JSON_THROW_ON_ERROR)
);
$response = $this->todoListController->addTask($request);
self::assertEquals(201, $response->getStatusCode());
}
}
Hay otros pequeños cambios en archivos, pero no los vamos a detallar aquí.
Ver las tareas de la lista
US 2
- As a User
- I want to see the task in my to-do list
- So that, I can know what I have to do next
Nuestra segunda historia requiere su propio endpoint, controlador y caso de uso. Ya tenemos un repositorio de tareas, al cual tendremos que añadir un método con el que obtener las lista completa.
Como tenemos una implementación real del repositorio ya no tenemos que usar un mock como nos hizo falta antes para poder arrancar el desarrollo. En una situación en la que estuviésemos usando una persistencia en base de datos o similar, posiblemente necesitaríamos una implementación fake, como un repositorio en memoria o incluso este simple repositorio en archivo que estamos utilizando, que necesitamos por el problema de la persistencia entre requests de PHP.
Esta es la primera versión del test de aceptación para esta historia de usuario:
namespace App\Tests\Katas\TodoList;
use App\Lib\FileStorageEngine;
use App\TodoList\Domain\Task;
use Symfony\Bundle\FrameworkBundle\Client;
use Symfony\Bundle\FrameworkBundle\Test\WebTestCase;
use Symfony\Component\HttpFoundation\Response;
class TodoListAcceptanceTest extends WebTestCase
{
private Client $client;
/** @test */
public function asUserIWantToAddTaskToAToDoList(): void
{
$response = $this->whenWeRequestToCreateATaskWithDescription('Write a test that f\
ails');
$this->thenResponseShouldBeSuccesful($response);
$this->thenTheTaskIsStored();
}
/** @test */
public function asUserIWantToSeeTheTasksInMyTodoList(): void
{
$expectedList = [
'[ ] 1. Write a test tha fails',
'[ ] 2. Write code to make the test pass'
];
$this->apiCreateTaskWithDescription('Write a test tha fails');
$this->apiCreateTaskWithDescription('Write code to make the test pass');
$this->client->request(
'GET',
'/api/todo'
);
$response = $this->client->getResponse();
self::assertEquals(Response::HTTP_OK, $response->getStatusCode());
$taskList = json_decode($response->getContent(), true);
self::assertEquals($expectedList, $taskList);
}
protected function setUp(): void
{
$this->resetRepositoryData();
$this->client = self::createClient();
}
protected function tearDown(): void
{
$this->resetRepositoryData();
}
private function resetRepositoryData(): void
{
if (file_exists('repository.data')) {
unlink('repository.data');
}
}
private function whenWeRequestToCreateATaskWithDescription(string $taskDescription): \
Response
{
return $this->apiCreateTaskWithDescription($taskDescription);
}
private function thenResponseShouldBeSuccesful(Response $response): void
{
self::assertEquals(Response::HTTP_CREATED, $response->getStatusCode());
}
private function thenTheTaskIsStored(): void
{
$storage = new FileStorageEngine('repository.data');
$tasks = $storage->loadObjects(Task::class);
self::assertCount(1, $tasks);
self::assertEquals(1, $tasks[1]->id());
}
private function apiCreateTaskWithDescription(string $taskDescription): Response
{
$this->client->request(
'POST',
'/api/todo',
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['task' => $taskDescription], JSON_THROW_ON_ERROR)
);
return $this->client->getResponse();
}
}
Así que lo ejecutamos y, como antes, nos vamos fijando en los errores que lanza para arreglarlos hasta que el test falle por las razones correctas. En este caso podemos ver dos errores relacionados.
El primero es que no hay una ruta adecuada para el endpoint.
"No route found for "GET /api/todo": Method Not Allowed (Allow: POST)"
Lo que, por supuesto, causa el error en el test al verificar el código de estado:
Configuramos la ruta en routes.yaml:
api_add_task:
path: /api/todo
controller: App\TodoList\Infrastructure\EntryPoint\Api\TodoListController::addTask
methods: ['POST']
Lanzamos el test. El error es diferente, lo que indica que hemos hecho el cambio correctamente, pero ahora nos hace falta el controlador específico:
"The controller for URI "/api/todo" is not callable. Expected method "getTaskList" on cla\
ss "App\TodoList\Infrastructure\EntryPoint\Api\TodoListController"
Así que añadimos nuestra implementación vacía inicial:
namespace App\TodoList\Infrastructure\EntryPoint\Api;
use App\TodoList\Application\AddTaskHandler;
use Symfony\Component\HttpFoundation\JsonResponse;
use Symfony\Component\HttpFoundation\Request;
use Symfony\Component\HttpFoundation\Response;
class TodoListController
{
/** @var AddTaskHandler */
private AddTaskHandler $addTaskHandler;
public function __construct(AddTaskHandler $addTaskHandler)
{
$this->addTaskHandler = $addTaskHandler;
}
public function addTask(Request $request): Response
{
$payload = $this->obtainPayload($request);
$this->addTaskHandler->execute($payload['task']);
return new JsonResponse('', Response::HTTP_CREATED);
}
public function getTaskList(): Response
{
throw new \RuntimeException(sprintf('Implement %s', __METHOD__));
}
private function obtainPayload(Request $request): array
{
return json_decode($request->getContent(), true, 512, JSON_THROW_ON_ERROR);
}
}
Al volver a lanzar el test, se lanza la excepción que nos indica que necesitamos implementar algo. Es el momento de volver al test unitario de TodoListController. Es importante aprender a identificar cuando tenemos que movernos entre el ciclo del test de aceptación y el ciclo de tests unitarios.
El nuevo test nos ayuda a introducir el nuevo caso de uso GetTaskListHandler, pero también nos plantea un problema interesante: ¿qué debería devolver GetTaskListHandler, objetos Task o una representación de estos?
En este caso, lo más correcto sería utilizar algún tipo de DataTransformer y aplicar un patrón Strategy de modo que TodoListController le indique al caso de uso qué DataTransformer quiere usar. Este transformer se puede pasar como dependencia al controlador y este se lo enviará al caso de uso como parámetro.
Como puedes ver, ahora estamos literalmente diseñando. Así que vamos a ver cómo queda el test.
namespace App\Tests\TodoList\Infrastructure\EntryPoint\Api;
use App\TodoList\Application\AddTaskHandler;
use App\TodoList\Infrastructure\EntryPoint\Api\TodoListController;
use PHPUnit\Framework\TestCase;
use Symfony\Component\HttpFoundation\Request;
class TodoListControllerTest extends TestCase
{
private const TASK_DESCRIPTION = 'Task Description';
private AddTaskHandler $addTaskHandler;
private TodoListController $todoListController;
private GetTaskListHandler $getTaskListHandler;
private TaskListTransformer $taskListTransformer;
protected function setUp(): void
{
$this->addTaskHandler = $this->createMock(AddTaskHandler::class);
$this->getTaskListHandler = $this->createMock(GetTaskListHandler::class);
$this->taskListTransformer = $this->createMock(TaskListTransformer::class);
$this->todoListController = new TodoListController(
$this->addTaskHandler,
$this->getTaskListHandler,
$this->taskListTransformer
);
}
/** @test */
public function shouldAddTask(): void
{
$this->addTaskHandler
->expects(self::once())
->method('execute')
->with(self::TASK_DESCRIPTION);
$request = new Request(
[],
[],
[],
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['task' => self::TASK_DESCRIPTION], JSON_THROW_ON_ERROR)
);
$response = $this->todoListController->addTask($request);
self::assertEquals(201, $response->getStatusCode());
}
/** @test */
public function shouldGetTaskList(): void
{
$expectedList = [
'[ ] 1. Task Description',
'[ ] 2. Task Description',
];
$this->getTaskListHandler
->expects(self::once())
->method('execute')
->with($this->taskListTransformer)
->willReturn($expectedList);
$response = $this->todoListController->getTaskList(new Request());
self::assertEquals(200, $response->getStatusCode());
$list = json_decode($response->getContent(), true);
self::assertEquals($expectedList, $list);
}
}
En este punto, solo necesitamos TaskListTransformer para que el controlador lo pase al caso de uso. Si lanzamos el test, fallará porque no tenemos aún definida la clase GetTaskListHandler. Introducimos una implementación inicial.
class GetTaskListHandler
{
}
Lanzando el test de nuevo, vemos que ahora nos pide TaskListTransformer. Primero movemos GetTaskListHandler a su lugar en App\TodoList\Application. Luego creamos TaskListTransformer.
class TaskListTransformer
{
}
Comprobamos de nuevo el resultado del test, que ahora nos dice que nos falta un método execute en GetTaskListHandler. Igual que hicimos antes, movemos primero la clase TaskListTransformer a su lugar.
En principio yo lo introduciría en App\TodoList\Infrastructure\EntryPoint\Api puesto que la razón de ser del transformer es preparar una respuesta específica para la API. Pero eso sería para la implementación concreta que vayamos a usar. Si lo hacemos así tendremos una dependencia mal orientada, pues estaría apuntando de Aplicación a Infraestructura. Para invertirla, tendremos que poner TaskListTransformer en la capa de aplicación como interface. Su lugar sería: App\TodoList\Application\TaskListTransformer.
Una vez recolocado nos ocupamos de añadir el método execute en GetTaskListHandler.
namespace App\TodoList\Application;
class GetTaskListHandler
{
public function execute(TaskListTransformer $taskListTransformer): array
{
throw new \RuntimeException(sprintf('Implement %s', __METHOD__));
}
}
Con este añadido, al ejecutar el test conseguimos que falle porque vemos que ha saltado la excepción que nos pide implementar getTaskList en el controlador:
RuntimeException : Implement App\TodoList\Infrastructure\EntryPoint\Api\TodoListControlle\
r::getTaskList
Y podemos implementar lo necesario para que pase el test:
namespace App\TodoList\Infrastructure\EntryPoint\Api;
use App\TodoList\Application\AddTaskHandler;
use App\TodoList\Application\GetTaskListHandler;
use App\TodoList\Application\TaskListTransformer;
use Symfony\Component\HttpFoundation\JsonResponse;
use Symfony\Component\HttpFoundation\Request;
use Symfony\Component\HttpFoundation\Response;
class TodoListController
{
private AddTaskHandler $addTaskHandler;
private GetTaskListHandler $getTaskListHandler;
private TaskListTransformer $taskListTransformer;
public function __construct(
AddTaskHandler $addTaskHandler,
GetTaskListHandler $getTaskListHandler,
TaskListTransformer $taskListTransformer
) {
$this->addTaskHandler = $addTaskHandler;
$this->getTaskListHandler = $getTaskListHandler;
$this->taskListTransformer = $taskListTransformer;
}
public function addTask(Request $request): Response
{
$payload = $this->obtainPayload($request);
$this->addTaskHandler->execute($payload['task']);
return new JsonResponse('', Response::HTTP_CREATED);
}
public function getTaskList(Request $request): Response
{
$taskList = $this->getTaskListHandler->execute($this->taskListTransformer);
return new JsonResponse($taskList, Response::HTTP_OK);
}
private function obtainPayload(Request $request): array
{
return json_decode($request->getContent(), true, 512, JSON_THROW_ON_ERROR);
}
}
Se puede observar que el controlador tiene muchas dependencias. Esto se puede solucionar con un bus de comandos o dividiendo la clase en otras más pequeñas, pero no lo vamos a hacer en este ejercicio para no perder el foco.
En cualquier caso, el test pasa, lo que nos indica que es el momento de moverse de nuevo al ciclo del test de aceptación.
Este seguirá fallando, como cabría esperar:
Fallo que nos dice que el siguiente paso es desarrollar con un test unitario el caso de uso GetTaskListHandler.
namespace App\Tests\TodoList\Application;
use App\TodoList\Application\GetTaskListHandler;
use App\TodoList\Application\TaskListTransformer;
use App\TodoList\Domain\Task;
use App\TodoList\Domain\TaskRepository;
use PHPUnit\Framework\TestCase;
class GetTaskListHandlerTest extends TestCase
{
/** @test */
public function shouldGetExistingTasks(): void
{
$expectedList = [
'[ ] 1. Write a test that fails',
'[ ] 2. Write code to make the test pass',
];
$taskList = [
new Task(1, 'Write a test that fails'),
new Task(2, 'Write code to make the test pass'),
];
$tasksRepository = $this->createMock(TaskRepository::class);
$tasksRepository
->method('findAll')
->willReturn($taskList);
$taskListTransformer = $this->createMock(TaskListTransformer::class);
$taskListTransformer
->expects(self::once())
->method('transform')
->with($taskList)
->willReturn($expectedList);
$getTaskListHandler = new GetTaskListHandler($tasksRepository);
$list = $getTaskListHandler->execute($taskListTransformer);
self::assertEquals($expectedList, $list);
}
}
Al lanzar este test, nos pide añadir el método findAll en el repositorio.
Esto lo hacemos en la interfaz y en la implementación concreta:
namespace App\TodoList\Domain;
interface TaskRepository
{
public function store(Task $task): void;
public function nextIdentity(): int;
public function findAll(): array;
}
namespace App\TodoList\Infrastructure\Persistence;
use App\Lib\FileStorageEngine;
use App\TodoList\Domain\Task;
use App\TodoList\Domain\TaskRepository;
class FileTaskRepository implements TaskRepository
{
/** @var FileStorageEngine */
private FileStorageEngine $fileStorageEngine;
public function __construct(FileStorageEngine $fileStorageEngine)
{
$this->fileStorageEngine = $fileStorageEngine;
}
public function store(Task $task): void
{
$tasks = $this->fileStorageEngine->loadObjects(Task::class);
$tasks[$task->id()] = $task;
$this->fileStorageEngine->persistObjects($tasks);
}
public function nextIdentity(): int
{
$tasks = $this->fileStorageEngine->loadObjects(Task::class);
return count($tasks) + 1;
}
public function findAll(): array
{
throw new \RuntimeException('Implement findAll() method.');
}
}
Y lo mismo para el método transform en TaskListTransformer:
El cual quedará así, una vez redefinido como interfaz:
namespace App\TodoList\Application;
interface TaskListTransformer
{
public function transform(array $taskList): array;
}
Con estos cambios, el test ahora fallará para decirnos que necesitamos implementar el método execute del caso de uso, que es justo donde queríamos estar:
RuntimeException : Implement App\TodoList\Application\GetTaskListHandler::execute
Y he aquí la implementación que hace pasar el test.
namespace App\TodoList\Application;
use App\TodoList\Domain\TaskRepository;
use App\TodoList\Application\TaskListTransformer;
class GetTaskListHandler
{
/** @var TaskRepository */
private TaskRepository $taskRepository;
public function __construct(TaskRepository $taskRepository)
{
$this->taskRepository = $taskRepository;
}
public function execute(TaskListTransformer $taskListTransformer): array
{
$tasks = $this->taskRepository->findAll();
return $taskListTransformer->transform($tasks);
}
}
Ahora que hemos vuelto a verde, regresaremos al ciclo de aceptación. Al lanzar el test el resultado es un mensaje de error nuevo, que nos pide implementar findAll en FileTaskRepository.
Esto requiere un test unitario.
namespace App\Tests\TodoList\Infrastructure\Persistence;
use App\Lib\FileStorageEngine;
use App\TodoList\Domain\Task;
use App\TodoList\Domain\TaskRepository;
use App\TodoList\Infrastructure\Persistence\FileTaskRepository;
use PHPUnit\Framework\TestCase;
class FileTaskRepositoryTest extends TestCase
{
private FileStorageEngine $fileStorageEngine;
private TaskRepository $taskRepository;
public function setUp(): void
{
$this->fileStorageEngine = $this->createMock(FileStorageEngine::class);
$this->taskRepository = new FileTaskRepository($this->fileStorageEngine);
}
/** @test */
public function shouldProvideNextIdentityCountingExistingObjects(): void
{
$this->fileStorageEngine
->method('loadObjects')
->willReturn(
[],
['Task'],
['Task', 'Task']
);
self::assertEquals(1, $this->taskRepository->nextIdentity());
self::assertEquals(2, $this->taskRepository->nextIdentity());
self::assertEquals(3, $this->taskRepository->nextIdentity());
}
/** @test */
public function shouldStoreATask(): void
{
$task = new Task(1, 'Task Description');
$this->fileStorageEngine
->method('loadObjects')
->willReturn([]);
$this->fileStorageEngine
->expects(self::once())
->method('persistObjects')
->with([1 => $task]);
$this->taskRepository->store($task);
}
/** @test */
public function shouldGetStoredTasks(): void
{
$storedTasks = [
1 => new Task(1, 'Write a test that fails'),
2 => new Task(2, 'Write code to make the test pass'),
];
$this->fileStorageEngine
->method('loadObjects')
->willReturn(
$storedTasks
);
self::assertEquals($storedTasks, $this->taskRepository->findAll());
}
}
Al ejecutarlo, nos pedirá:
RuntimeException : Implement findAll() method.
Así que vamos a ello:
namespace App\TodoList\Infrastructure\Persistence;
use App\Lib\FileStorageEngine;
use App\TodoList\Domain\Task;
use App\TodoList\Domain\TaskRepository;
class FileTaskRepository implements TaskRepository
{
/** @var FileStorageEngine */
private FileStorageEngine $fileStorageEngine;
public function __construct(FileStorageEngine $fileStorageEngine)
{
$this->fileStorageEngine = $fileStorageEngine;
}
public function store(Task $task): void
{
$tasks = $this->fileStorageEngine->loadObjects(Task::class);
$tasks[$task->id()] = $task;
$this->fileStorageEngine->persistObjects($tasks);
}
public function nextIdentity(): int
{
$tasks = $this->fileStorageEngine->loadObjects(Task::class);
return count($tasks) + 1;
}
public function findAll(): array
{
return $this->fileStorageEngine->loadObjects(Task::class);
}
}
Ahora el test unitario pasa, con lo cual tenemos implementado buena parte del repositorio. ¿Será suficiente para hacer pasar el test de aceptación?
No, todavía tenemos cosas pendientes. En este momento se nos reclama introducir una implementación concreta de TaskListTransformer.
Ahora nos toca introducir un nuevo test unitario para desarrollar el Transformer concreto, que ubicaremos en App\TodoList\Infrastructure\EntryPoint\Api, ya que es el controlador quien está interesado en usarlo. Lo denominaremos StringTaskListTransformer pues convierte a Task en una representación en forma de string.
Este nos va a suponer un pequeño reto de diseño. No disponemos todavía de formas de acceder a las propiedades de Task, una entidad que tampoco hemos tenido que desarrollar más hasta ahora, y lo cierto es que no deberíamos condicionar su implementación a este tipo de necesidades. En un sistema más real y sofisticado podríamos aplicar un patrón Visitor o similar. En este caso, lo que haremos será pasar una plantilla a Task para que nos la devuelva cubierta con sus datos.
Como Task es una entidad prefiero no mockearla, así que el test quedará de esta forma:
namespace App\Tests\TodoList\Infrastructure\EntryPoint\Api;
use App\TodoList\Domain\Task;
use App\TodoList\Infrastructure\EntryPoint\Api\StringTaskListTransformer;
use PHPUnit\Framework\TestCase;
class StringTaskListTransformerTest extends TestCase
{
/** @test
* @dataProvider examplesProvider
*/
public function shouldTransformList($tasksList, $expected): void
{
$taskListTransformer = new StringTaskListTransformer();
$result = $taskListTransformer->transform($tasksList);
self::assertEquals($expected, $result);
}
public function examplesProvider(): array
{
return [
[[], []],
[[new Task(1, 'Task Description')], ['[ ] 1. Task Description']]
];
}
}
Y el código de producción podría ser este:
namespace App\TodoList\Infrastructure\EntryPoint\Api;
use App\TodoList\Application\TaskListTransformer;
class StringTaskListTransformer implements TaskListTransformer
{
public function transform(array $taskList): array
{
$transformed = [];
foreach ($taskList as $task) {
$transformed[] = $task->representedAs('[:check] :id. :description');
}
return $transformed;
}
}
El test lanzará un error para decirnos que no está implementado el método representedAs en Task, por lo que podemos añadirlo.
namespace App\TodoList\Domain;
class Task
{
private int $id;
private string $description;
public function __construct(int $id, string $description)
{
$this->id = $id;
$this->description = $description;
}
public function id(): int
{
return $this->id;
}
public function representedAs(): string
{
throw new \RuntimeException(sprintf('Implement %s', __METHOD__));
}
}
Salvando las distancias, podemos usar el test actual como test de aceptación. Si lo ejecutamos veremos que se lanza la excepción:
RuntimeException : Implement App\TodoList\Domain\Task::representedAs
Lo que nos indicaría la necesidad de pasar al siguiente nivel y crear un test unitario para desarrollar Task, o al menos el método representedAs. Otra opción, sería desarrollar Task bajo la cobertura del test actual, pero no es muy buena idea, ya que el test podría requerir de ejemplos que no aportan nada realmente al test y que son relevantes solo para task.
namespace App\Tests\TodoList\Domain;
use App\TodoList\Domain\Task;
use PHPUnit\Framework\TestCase;
class TaskTest extends TestCase
{
/** @test */
public function shouldProvideRepresentation(): void
{
$expected = '[ ] 1. Task Description';
$task = new Task(1, 'Task Description');
$representation = $task->representedAs('[:check] :id. :description');
self::assertEquals($expected, $representation);
}
}
Por el momento esta implementación ya nos iría bien.
namespace App\TodoList\Domain;
class Task
{
private int $id;
private string $description;
public function __construct(int $id, string $description)
{
$this->id = $id;
$this->description = $description;
}
public function id(): int
{
return $this->id;
}
public function representedAs(string $format): string
{
$values = [
':check' => ' ',
':id' => $this->id,
':description' => $this->description
];
return strtr($format, $values);
}
}
Así que podríamos subir un nivel y volver al test anterior del Transformer, que pasa sin más problemas.
Con este test en verde, regresamos al nivel de aceptación, que también pasa, indicando que hemos terminado de desarrollar esta historia de usuario.
Marcar tareas completadas
US-3
- As a User
- I want to check a task when it is done
- So that, I can see my progress
La tercera historia de usuario se construye fácilmente a partir de las dos anteriores, ya que nuestra aplicación ya permite introducir tareas y ver la lista. Por eso, antes de empezar con el desarrollo refactorizaremos el test de aceptación para que sea más sencillo extenderlo. De hecho, hasta podemos reutilizar algunas partes. Este es el resultado, ya con el nuevo test de aceptación.
namespace App\Tests\Katas\TodoList;
use App\Lib\FileStorageEngine;
use App\TodoList\Domain\Task;
use Symfony\Bundle\FrameworkBundle\Client;
use Symfony\Bundle\FrameworkBundle\Test\WebTestCase;
use Symfony\Component\HttpFoundation\Response;
class TodoListAcceptanceTest extends WebTestCase
{
private Client $client;
/** @test */
public function asUserIWantToAddTaskToAToDoList(): void
{
$response = $this->whenWeRequestToCreateATaskWithDescription('Write a test that f\
ails');
$this->thenResponseShouldBeSuccesful($response);
$this->thenTheTaskIsStored();
}
/** @test */
public function asUserIWantToSeeTheTasksInMyTodoList(): void
{
$this->givenIHaveAddedTasks();
$response = $this->whenIRequestTheListOfTasks();
$this->thenICanSeeAddedTasksInTheList(
[
'[ ] 1. Write a test tha fails',
'[ ] 2. Write code to make the test pass'
],
$response
);
}
/** @test */
public function asUserIWantToMarkTasksAsCompleted(): void
{
$this->givenIHaveAddedTasks();
$this->client->request(
'PATCH',
'/api/todo/1',
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['completed' => true], JSON_THROW_ON_ERROR)
);
$patchResponse = $this->client->getResponse();
self::assertEquals(Response::HTTP_OK, $patchResponse->getStatusCode());
$response = $this->whenIRequestTheListOfTasks();
$this->thenICanSeeAddedTasksInTheList(
[
'[√] 1. Write a test tha fails',
'[ ] 2. Write code to make the test pass'
],
$response
);
}
protected function setUp(): void
{
$this->resetRepositoryData();
$this->client = self::createClient();
}
protected function tearDown(): void
{
$this->resetRepositoryData();
}
private function resetRepositoryData(): void
{
if (file_exists('repository.data')) {
unlink('repository.data');
}
}
private function whenWeRequestToCreateATaskWithDescription(string $taskDescription): \
Response
{
return $this->apiCreateTaskWithDescription($taskDescription);
}
private function thenResponseShouldBeSuccesful(Response $response): void
{
self::assertEquals(Response::HTTP_CREATED, $response->getStatusCode());
}
private function thenTheTaskIsStored(): void
{
$storage = new FileStorageEngine('repository.data');
$tasks = $storage->loadObjects(Task::class);
self::assertCount(1, $tasks);
self::assertEquals(1, $tasks[1]->id());
}
private function apiCreateTaskWithDescription(string $taskDescription): Response
{
$this->client->request(
'POST',
'/api/todo',
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['task' => $taskDescription], JSON_THROW_ON_ERROR)
);
return $this->client->getResponse();
}
private function whenIRequestTheListOfTasks(): Response
{
$response = $this->apiGetTasksList();
self::assertEquals(Response::HTTP_OK, $response->getStatusCode());
return $response;
}
private function apiGetTasksList(): Response
{
$this->client->request(
'GET',
'/api/todo'
);
return $this->client->getResponse();
}
private function givenIHaveAddedTasks(): void
{
$this->apiCreateTaskWithDescription('Write a test tha fails');
$this->apiCreateTaskWithDescription('Write code to make the test pass');
}
private function thenICanSeeAddedTasksInTheList(array $expectedTasks, Response $respo\
nse): void
{
$taskList = json_decode($response->getContent(), true);
self::assertEquals(
$expectedTasks, $taskList);
}
}
Al lanzar el test, y como era de esperar, falla porque no se encuentra la ruta al endpoint:
"No route found for "PATCH /api/todo/1"
Y, como hemos hecho antes, tendremos que definirla y crear un controlador que la gestione. En primer lugar, la definición de la ruta en routes.yaml.
api_add_task:
path: /api/todo
controller: App\TodoList\Infrastructure\EntryPoint\Api\TodoListController::addTask
methods: ['POST']
api_get_task_list:
path: /api/todo
controller: App\TodoList\Infrastructure\EntryPoint\Api\TodoListController::getTaskList
methods: ['GET']
api_mark_task_completed:
path: /api/todo/{taskId}
controller: App\TodoList\Infrastructure\EntryPoint\Api\TodoListController::markTaskComp\
leted
methods: ['PATCH']
Una nueva ejecución del test nos indica que falta un controlador:
"The controller for URI "/api/todo/1" is not callable. Expected method "markTaskCompleted"
Y añadimos uno vacío:
namespace App\TodoList\Infrastructure\EntryPoint\Api;
use App\TodoList\Application\AddTaskHandler;
use App\TodoList\Application\GetTaskListHandler;
use App\TodoList\Application\TaskListTransformer;
use Symfony\Component\HttpFoundation\JsonResponse;
use Symfony\Component\HttpFoundation\Request;
use Symfony\Component\HttpFoundation\Response;
class TodoListController
{
private AddTaskHandler $addTaskHandler;
private GetTaskListHandler $getTaskListHandler;
private TaskListTransformer $taskListTransformer;
public function __construct(
AddTaskHandler $addTaskHandler,
GetTaskListHandler $getTaskListHandler,
TaskListTransformer $taskListTransformer
) {
$this->addTaskHandler = $addTaskHandler;
$this->getTaskListHandler = $getTaskListHandler;
$this->taskListTransformer = $taskListTransformer;
}
public function addTask(Request $request): Response
{
$payload = $this->obtainPayload($request);
$this->addTaskHandler->execute($payload['task']);
return new JsonResponse('', Response::HTTP_CREATED);
}
public function getTaskList(Request $request): Response
{
$taskList = $this->getTaskListHandler->execute($this->taskListTransformer);
return new JsonResponse($taskList, Response::HTTP_OK);
}
public function markTaskCompleted(int $taskId): Response
{
throw new \RuntimeException(sprintf('Implement %s', __METHOD__));
}
private function obtainPayload(Request $request): array
{
return json_decode($request->getContent(), true, 512, JSON_THROW_ON_ERROR);
}
}
El error ahora es:
Y el test falla porque espera que ese endpoint esté funcionando como es debido y respondiendo, pero todavía está sin implementar. Por tanto, nos movemos al nivel unitario para definir la funcionalidad del controlador.
Como en los casos anteriores, implementar la funcionalidad require además del controlador un caso de uso y utilizar el repositorio para recuperar la tarea que se quiere marcar, y volver a guardarla. Por tanto, la clave del test será esperar que se ejecute el caso de uso con los parámetros adecuados.
Así que, el test quedaría más o menos así;
namespace App\Tests\TodoList\Infrastructure\EntryPoint\Api;
use App\TodoList\Application\AddTaskHandler;
use App\TodoList\Application\GetTaskListHandler;
use App\TodoList\Application\TaskListTransformer;
use App\TodoList\Infrastructure\EntryPoint\Api\TodoListController;
use PHPUnit\Framework\TestCase;
use Symfony\Component\HttpFoundation\Request;
class TodoListControllerTest extends TestCase
{
private const TASK_DESCRIPTION = 'Task Description';
private const COMPLETED_TASK_ID = 1;
private AddTaskHandler $addTaskHandler;
private TodoListController $todoListController;
private GetTaskListHandler $getTaskListHandler;
private TaskListTransformer $taskListTransformer;
private MarkTaskCompletedHandler $markTaskCompletedHandler;
protected function setUp(): void
{
$this->addTaskHandler = $this->createMock(AddTaskHandler::class);
$this->getTaskListHandler = $this->createMock(GetTaskListHandler::class);
$this->taskListTransformer = $this->createMock(TaskListTransformer::class);
$this->markTaskCompletedHandler = $this->createMock(MarkTaskCompletedHandler::cla\
ss);
$this->todoListController = new TodoListController(
$this->addTaskHandler,
$this->getTaskListHandler,
$this->taskListTransformer,
$this->markTaskCompletedHandler
);
}
/** @test */
public function shouldAddTask(): void
{
$this->addTaskHandler
->expects(self::once())
->method('execute')
->with(self::TASK_DESCRIPTION);
$request = new Request(
[],
[],
[],
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['task' => self::TASK_DESCRIPTION], JSON_THROW_ON_ERROR)
);
$response = $this->todoListController->addTask($request);
self::assertEquals(201, $response->getStatusCode());
}
/** @test */
public function shouldGetTaskList(): void
{
$expectedList = [
'[ ] 1. Task Description',
'[ ] 2. Task Description',
];
$this->getTaskListHandler
->expects(self::once())
->method('execute')
->with($this->taskListTransformer)
->willReturn($expectedList);
$response = $this->todoListController->getTaskList(new Request());
self::assertEquals(200, $response->getStatusCode());
$list = json_decode($response->getContent(), true);
self::assertEquals($expectedList, $list);
}
/** @test */
public function shouldMarkTaskCompleted(): void
{
$this->markTaskCompletedHandler
->expects(self::once())
->method('execute')
->with(self::COMPLETED_TASK_ID, true);
$request = new Request(
[],
[],
[],
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['completed' => true], JSON_THROW_ON_ERROR)
);
$response = $this->todoListController->markTaskCompleted(self::COMPLETED_TASK_ID,\
$request);
self::assertEquals(200, $response->getStatusCode());
}
}
Una vez que tenemos el test, lo lanzamos. El resultado es que nos pide crear la clase MarkTaskCompletedHandler.
La creamos en el propio test y luego la movemos a su ubicación en App\TodoList\Application. A continuación nos pedirá crear el método execute.
El cual prepararemos de esta forma:
namespace App\TodoList\Application;
class MarkTaskCompletedHandler
{
public function execute(int $taskId, bool $completed): void
{
throw new \RuntimeException(sprintf('Implement %s', __METHOD__));
}
}
Con esto ya tenemos lo necesario para implementar la acción del controlador, cosa que hacemos, porque el siguiente error nos lo indica:
RuntimeException : Implement App\TodoList\Infrastructure\EntryPoint\Api\TodoListControlle\
r::markTaskCompleted
Este es el código que hará pasar el test del controlador.
namespace App\TodoList\Infrastructure\EntryPoint\Api;
use App\TodoList\Application\AddTaskHandler;
use App\TodoList\Application\GetTaskListHandler;
use App\TodoList\Application\MarkTaskCompletedHandler;
use Symfony\Component\HttpFoundation\JsonResponse;
use Symfony\Component\HttpFoundation\Request;
use Symfony\Component\HttpFoundation\Response;
class TodoListController
{
private AddTaskHandler $addTaskHandler;
private GetTaskListHandler $getTaskListHandler;
private TaskListTransformer $taskListTransformer;
private MarkTaskCompletedHandler $markTaskCompletedHandler;
public function __construct(
AddTaskHandler $addTaskHandler,
GetTaskListHandler $getTaskListHandler,
TaskListTransformer $taskListTransformer,
MarkTaskCompletedHandler $markTaskCompletedHandler
) {
$this->addTaskHandler = $addTaskHandler;
$this->getTaskListHandler = $getTaskListHandler;
$this->taskListTransformer = $taskListTransformer;
$this->markTaskCompletedHandler = $markTaskCompletedHandler;
}
public function addTask(Request $request): Response
{
$payload = $this->obtainPayload($request);
$this->addTaskHandler->execute($payload['task']);
return new JsonResponse('', Response::HTTP_CREATED);
}
public function getTaskList(Request $request): Response
{
$taskList = $this->getTaskListHandler->execute($this->taskListTransformer);
return new JsonResponse($taskList, Response::HTTP_OK);
}
public function markTaskCompleted(int $taskId, Request $request): Response
{
$payload = $this->obtainPayload($request);
$this->markTaskCompletedHandler->execute($taskId, $payload['completed']);
return new JsonResponse('', Response::HTTP_OK);
}
private function obtainPayload(Request $request): array
{
return json_decode($request->getContent(), true, 512, JSON_THROW_ON_ERROR);
}
}
Una vez que el test del controlador pasa, tendremos que volver a lanzar el test de aceptación. Este nos indicará el siguiente paso:
Nos requiere implementar el caso de uso. Por lo tanto, necesitamos un nuevo test unitario:
namespace App\Tests\TodoList\Application;
use App\TodoList\Application\MarkTaskCompletedHandler;
use App\TodoList\Domain\Task;
use App\TodoList\Domain\TaskRepository;
use PHPUnit\Framework\TestCase;
class MarkTaskCompletedHandlerTest extends TestCase
{
private const COMPLETED_TASK_ID = 1;
/** @test */
public function shouldMarkTaskAsCompletedAndPersist(): void
{
$task = new Task(self::COMPLETED_TASK_ID, 'Task Description');
$taskRepository = $this->createMock(TaskRepository::class);
$taskRepository
->method('retrieve')
->with(self::COMPLETED_TASK_ID)
->willReturn($task);
$taskRepository
->expects(self::once())
->method('store')
->with($task);
$markTaskCompletedHandler = new MarkTaskCompletedHandler($taskRepository);
$markTaskCompletedHandler->execute(self::COMPLETED_TASK_ID, true);
}
}
La ejecución del test arroja el siguiente error:
Hasta ahora no habíamos requerido este método en el repositorio, por lo cual tendremos que añadirlo a la interfaz.
namespace App\TodoList\Domain;
interface TaskRepository
{
public function store(Task $task): void;
public function nextIdentity(): int;
public function findAll(): array;
public function retrieve(int $taskId): Task;
}
Esto será suficiente para poder seguir ejecutando el test y que nos pida implementar el método execute en el caso de uso.
RuntimeException : Implement App\TodoList\Application\MarkTaskCompletedHandler::execute
Así que vamos a ello. Es bastante sencillo:
namespace App\TodoList\Application;
use App\TodoList\Domain\TaskRepository;
class MarkTaskCompletedHandler
{
private TaskRepository $taskRepository;
public function __construct(TaskRepository $taskRepository)
{
$this->taskRepository = $taskRepository;
}
public function execute(int $taskId, bool $completed): void
{
$task = $this->taskRepository->retrieve($taskId);
if ($completed) {
$task->markCompleted();
}
$this->taskRepository->store($task);
}
}
Al volver a ejecutar el test fallará. Esto es porque no tenemos definido el método Task::markCompleted:
Error : Call to undefined method App\TodoList\Domain\Task::markCompleted()
Siempre que tenemos un error de este tipo, tendremos que profundizar y entrar en un nuevo test unitario. En este caso, para implementar este método en Task. No tenemos acceso directo a la propiedad complete, que aún no tenemos definida siquiera, pero podemos controlar su estado indirectamente gracias a su representación.
namespace App\Tests\TodoList\Domain;
use App\TodoList\Domain\Task;
use PHPUnit\Framework\TestCase;
class TaskTest extends TestCase
{
/** @test */
public function shouldProvideRepresentation(): void
{
$expected = '[ ] 1. Task Description';
$task = new Task(1, 'Task Description');
$representation = $task->representedAs('[:check] :id. :description');
self::assertEquals($expected, $representation);
}
/** @test */
public function shouldMarkTaskCompleted(): void
{
$expected = '[√] 1. Task Description';
$task = new Task(1, 'Task Description');
$task->markCompleted();
$representation = $task->representedAs('[:check] :id. :description');
self::assertEquals($expected, $representation);
}
}
La implementación es bastante sencilla:
namespace App\TodoList\Domain;
class Task
{
private int $id;
private string $description;
private bool $completed;
public function __construct(int $id, string $description)
{
$this->id = $id;
$this->description = $description;
$this->completed = false;
}
public function id(): int
{
return $this->id;
}
public function representedAs(string $format): string
{
$values = [
':check' => $this->completed ? '√' : ' ',
':id' => $this->id,
':description' => $this->description
];
return strtr($format, $values);
}
public function markCompleted(): void
{
$this->completed = true;
}
}
Con esto, el test de Task pasa y podemos volver al nivel del caso de uso. Al lanzar el test de nuevo, vemos que también pasa, por lo que podemos volver al nivel del test de aceptación.
Este test, en cambio, no pasará porque espera que implementemos el método retrieve en FileTaskRepository, que aún no lo tenemos. Nos vamos al test.
namespace App\Tests\TodoList\Infrastructure\Persistence;
use App\Lib\FileStorageEngine;
use App\TodoList\Domain\Task;
use App\TodoList\Domain\TaskRepository;
use App\TodoList\Infrastructure\Persistence\FileTaskRepository;
use PHPUnit\Framework\TestCase;
class FileTaskRepositoryTest extends TestCase
{
private FileStorageEngine $fileStorageEngine;
private TaskRepository $taskRepository;
public function setUp(): void
{
$this->fileStorageEngine = $this->createMock(FileStorageEngine::class);
$this->taskRepository = new FileTaskRepository($this->fileStorageEngine);
}
/** @test */
public function shouldProvideNextIdentityCountingExistingObjects(): void
{
$this->fileStorageEngine
->method('loadObjects')
->willReturn(
[],
['Task'],
['Task', 'Task']
);
self::assertEquals(1, $this->taskRepository->nextIdentity());
self::assertEquals(2, $this->taskRepository->nextIdentity());
self::assertEquals(3, $this->taskRepository->nextIdentity());
}
/** @test */
public function shouldStoreATask(): void
{
$task = new Task(1, 'Task Description');
$this->fileStorageEngine
->method('loadObjects')
->willReturn([]);
$this->fileStorageEngine
->expects(self::once())
->method('persistObjects')
->with([1 => $task]);
$this->taskRepository->store($task);
}
/** @test */
public function shouldGetStoredTasks(): void
{
$storedTasks = [
1 => new Task(1, 'Write a test that fails'),
2 => new Task(2, 'Write code to make the test pass'),
];
$this->fileStorageEngine
->method('loadObjects')
->willReturn(
$storedTasks
);
self::assertEquals($storedTasks, $this->taskRepository->findAll());
}
/** @test */
public function shouldRetrieveATaskByItsId(): void
{
$expectedTask = new Task(1, 'Write a test that fails');
$storedTasks = [
1 => $expectedTask,
2 => new Task(2, 'Write code to make the test pass'),
];
$this->fileStorageEngine
->method('loadObjects')
->willReturn(
$storedTasks
);
self::assertEquals($expectedTask, $this->taskRepository->retrieve(1));
}
}
Como era de esperar, el test nos reclamará escribir el método retrieve.
namespace App\TodoList\Infrastructure\Persistence;
use App\Lib\FileStorageEngine;
use App\TodoList\Domain\Task;
use App\TodoList\Domain\TaskRepository;
class FileTaskRepository implements TaskRepository
{
private FileStorageEngine $fileStorageEngine;
public function __construct(FileStorageEngine $fileStorageEngine)
{
$this->fileStorageEngine = $fileStorageEngine;
}
public function store(Task $task): void
{
$tasks = $this->fileStorageEngine->loadObjects(Task::class);
$tasks[$task->id()] = $task;
$this->fileStorageEngine->persistObjects($tasks);
}
public function nextIdentity(): int
{
$tasks = $this->fileStorageEngine->loadObjects(Task::class);
return count($tasks) + 1;
}
public function findAll(): array
{
return $this->fileStorageEngine->loadObjects(Task::class);
}
public function retrieve(int $taskId): Task
{
$tasks = $this->fileStorageEngine->loadObjects(Task::class);
return $tasks[$taskId];
}
}
Y con este el test de FileTaskRepository está en verde. Aprovechamos para hacer un pequeño refactor, de modo que la dependencia esté controlada:
namespace App\TodoList\Infrastructure\Persistence;
use App\Lib\FileStorageEngine;
use App\TodoList\Domain\Task;
use App\TodoList\Domain\TaskRepository;
class FileTaskRepository implements TaskRepository
{
private FileStorageEngine $fileStorageEngine;
public function __construct(FileStorageEngine $fileStorageEngine)
{
$this->fileStorageEngine = $fileStorageEngine;
}
public function store(Task $task): void
{
$tasks = $this->findAll();
$tasks[$task->id()] = $task;
$this->persistAllInStorage($tasks);
}
public function nextIdentity(): int
{
$tasks = $this->findAll();
return count($tasks) + 1;
}
public function findAll(): array
{
return $this->getAllFromStorage();
}
public function retrieve(int $taskId): Task
{
$tasks = $this->findAll();
return $tasks[$taskId];
}
private function getAllFromStorage(): array
{
return $this->fileStorageEngine->loadObjects(Task::class);
}
private function persistAllInStorage(array $tasks): void
{
$this->fileStorageEngine->persistObjects($tasks);
}
}
Y ahora volveremos a lanzar el test de aceptación, que esta vez pasa limpiamente.
Siguientes pasos
En este punto tenemos las tres historias de usuario implementadas. ¿Qué nos interesa hacer ahora?
Una de las mejoras que podemos hacer en este momento es arreglar el test de aceptación para que pueda usarse como test de QA. Ahora que hemos desarrollado todos los componentes implicados es posible hacer que el test sea más expresivo y más útil para describir el comportamiento implementado.
Los tests unitarios nos pueden valer tal como están. Una objeción típica es que al estar basados en mocks son frágiles por su acoplamiento a la implementación. Sin embargo, debemos recordar que básicamente hemos estado diseñando los componentes que necesitábamos y la forma en que queríamos hacerlos interactuar. En otras palabras: no es previsible que esta implementación vaya a cambiar demasiado hasta el punto de invalidar los test. Por otro lado, los tests unitarios que hemos usado, caracterizan el comportamiento concreto de cada unidad. En conjunto son rápidos y nos proporcionan la resolución necesaria como para ayudarnos a diagnosticar rápidamente los problemas que puedan surgir.
Así que vamos a retocar el test de aceptación para que tenga un mejor lenguaje de negocio:
namespace App\Tests\Katas\TodoList;
use Symfony\Bundle\FrameworkBundle\Client;
use Symfony\Bundle\FrameworkBundle\Test\WebTestCase;
use Symfony\Component\HttpFoundation\Response;
class TodoListAcceptanceTest extends WebTestCase
{
private Client $client;
/** @test */
public function asUserIWantToAddTaskToAToDoList(): void
{
$this->givenIRequestToCreateATaskWithDescription('Write a test that fails');
$response = $this->whenIRequestTheListOfTasks();
$this->thenICanSeeAddedTasksInTheList(
[
'[ ] 1. Write a test that fails',
],
$response
);
}
/** @test */
public function asUserIWantToSeeTheTasksInMyTodoList(): void
{
$this->givenIHaveAddedTasks(
[
'Write a test that fails',
'Write code to make the test pass',
]
);
$response = $this->whenIRequestTheListOfTasks();
$this->thenICanSeeAddedTasksInTheList(
[
'[ ] 1. Write a test that fails',
'[ ] 2. Write code to make the test pass',
],
$response
);
}
/** @test */
public function asUserIWantToMarkTasksAsCompleted(): void
{
$this->givenIHaveAddedTasks(
[
'Write a test that fails',
'Write code to make the test pass',
]
);
$this->givenIMarkATaskAsCompleted(1);
$response = $this->whenIRequestTheListOfTasks();
$this->thenICanSeeAddedTasksInTheList(
[
'[√] 1. Write a test that fails',
'[ ] 2. Write code to make the test pass',
],
$response
);
}
private function givenIRequestToCreateATaskWithDescription(string $taskDescription): \
Response
{
return $this->apiCreateTaskWithDescription($taskDescription);
}
private function apiCreateTaskWithDescription(string $taskDescription): Response
{
$this->client->request(
'POST',
'/api/todo',
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['task' => $taskDescription], JSON_THROW_ON_ERROR)
);
return $this->client->getResponse();
}
private function whenIRequestTheListOfTasks(): Response
{
$response = $this->apiGetTasksList();
self::assertEquals(Response::HTTP_OK, $response->getStatusCode());
return $response;
}
private function apiGetTasksList(): Response
{
$this->client->request(
'GET',
'/api/todo'
);
return $this->client->getResponse();
}
private function thenICanSeeAddedTasksInTheList(array $expectedTasks, Response $respo\
nse): void
{
$taskList = json_decode($response->getContent(), true);
self::assertEquals($expectedTasks, $taskList);
}
private function givenIHaveAddedTasks($tasks): void
{
foreach ($tasks as $task) {
$this->apiCreateTaskWithDescription($task);
}
}
private function givenIMarkATaskAsCompleted(int $taskId): void
{
$patchResponse = $this->apiMarkTaskCompleted($taskId);
self::assertEquals(Response::HTTP_OK, $patchResponse->getStatusCode());
}
private function apiMarkTaskCompleted(int $taskId): Response
{
$this->client->request(
'PATCH',
'/api/todo/' . $taskId . '',
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['completed' => true], JSON_THROW_ON_ERROR)
);
return $this->client->getResponse();
}
protected function setUp(): void
{
$this->resetRepositoryData();
$this->client = self::createClient();
}
private function resetRepositoryData(): void
{
if (file_exists('repository.data')) {
unlink('repository.data');
}
}
protected function tearDown(): void
{
$this->resetRepositoryData();
}
}
Básicamente hemos reescrito el test usando un estilo Behavior Driven Development. No nos ha hecho falta hacer un Gherkin aquí, pero hubiésemos podido hacerlo.
Esto nos ha permitido desprendernos de la llamada directa al motor de almacenamiento que habíamos introducido al principio, y al hacerlo conseguimos que el test sea más portable, ya que solo usa las llamadas a los endpoints, por lo que puede funcionar en distintos entornos (local e integración contínua, por ejemplo).
24 Resolviendo bugs con TDD
En nuestro proyecto de lista de tareas hemos desarrollado lo que podríamos llamar el happy path de la aplicación. Es decir, hemos supuesto que al crear una tarea la consumidora del API no cometería errores como intentar crear una tarea sin nombre. Otro supuesto es que al marcar una tarea como completada se usarán id de tareas que existan en la lista.
Esto significa que la aplicación puede fallar si no se cumple alguno de estos supuestos. ¿Es esto un bug? En cierto sentido sí, aunque también podemos argumentar que son prestaciones no implementadas.
Cuando desarrollamos usando TDD podemos prevenir muchos defectos debidos a implementaciones con errores. Por ejemplo, imagina que no hemos implementado un método Task::markComplete y no tenemos tests cuya ejecución implique esa llamada. El resultado será un bug.
Obviamente, si no hemos escrito un test para verificar un comportamiento específico, como podría ser impedir que se puedan crear tareas sin descripción, ese defecto acabará apareciendo.
Se dice que ni el testing ni el TDD nos libran de que un software tenga defectos. Sin embargo, creo que podemos estar muy seguras de que usando TDD los defectos aparecerán en aquellas partes que no estén cubiertas por un test. Considerados así, por tanto, los defectos son más bien circunstancias no previstas o casos no implementados todavía. Esto es interesante y bastante liberador, porque en cierto modo, hace que los defectos del software sean bastante previsibles y manejables, motivados por la falta de definición o, simplemente, por falta de información en el momento del desarrollo.
Así que vamos a ver cómo trabajaríamos en el caso de que se reporta un bug sobre nuestro proyecto To-do list.
Defectos en To-do list
Después de un tiempo utilizando nuestra API para generar listas de tareas, vemos que hay algunos defectos. Uno de ellos es que podemos introducir tareas sin descripción, lo que no tiene mucho sentido, ya que no nos sirve para saber qué tenemos que hacer.
Este bug es debido a que no controlamos en ningún momento que efectivamente recibimos la descripción de la tarea, es decir, estamos confiando en que el input es siempre correcto. En ese caso, caben dos posibilidades: que el payload de la petición al endpoint del POST esté completamente vacía o que el campo task venga vacío.
En esta ocasión, el comportamiento del sistema no está especificado para estas circunstancias y no está expresado en tests. En otros casos, el bug es algún tipo de error no cubierto por los tests actuales.
Así que nuestra primera aproximación será crear un test que ponga de manifiesto el bug.
Ahora bien, ¿en dónde nos interesa poner ese test? Vamos a intentar pensar un poco en esto.
Por un lado, los endpoints afectados deberían devolver una respuesta 400 (Bad Request) porque en este caso, lo que ocurre es que la request está mal construída y el endpoint no la entiende.
Según esto, tendría sentido añadir un test de aceptación. Sin embargo, también tenemos tests unitarios del controlador, que son mucho más rápidos y también nos permitirían comprobar que la respuesta tiene el código adecuado.
Por otro lado, debemos tomar en consideración qué componente se responsabiliza de validar qué cuestiones.
Así por ejemplo, si la request no trae ninguna payload o la estructura no incluye los campos requeridos, tiene sentido que el controlador sea el responsable de verificarlo y fallar en cuanto lo detecta. El test tiene sentido a nivel del controlador.
En cambio, si la request tiene la estructura correcta y se pueden encontrar los campos requeridos, puede que la validación de sus valores corresponda a capas más internas. Así, por ejemplo, si el valor de task en la payload es una cadena vacía el controlador puede intentar pasarlo al caso de uso y que sea el constructor de Task quien valide si ese valor es aceptable o no. El test, en este caso, sería en el nivel del caso de uso AddTaskHandler.
Esto abre entonces una nueva problemática para el controlador y es gestionar los errores o excepciones que vengan del caso de uso para devolver la respuesta de error adecuada.
Como se puede ver, se plantean un montón de circunstancias que nos obligan a intervenir en distintos niveles de la aplicación.
Un principio que podríamos tratar de seguir es que si falla algo en el nivel de aceptación debería tener un reflejo en el nivel unitario. El primer fallo nos indica que la aplicación tiene un defecto, mientras que el fallo en el nivel unitario nos indicaría el componente que falla.
Así que vamos a ir por partes, atacando cada uno de los problemas.
Payload inválida
El supuesto que vamos a tratar de resolver es enviar una petición al endpoint que esté mal formada o vacía. En cualquier caso no incluye el campo task.
Empezaremos por el test de aceptación y vamos a intentar reproducir el error lanzando una petición a la API con una payload inválida.
namespace App\Tests\Katas\TodoList;
use Symfony\Bundle\FrameworkBundle\Client;
use Symfony\Bundle\FrameworkBundle\Test\WebTestCase;
use Symfony\Component\HttpFoundation\Response;
class TodoListAcceptanceTest extends WebTestCase
{
private Client $client;
// ...
/** @test */
public function asUserITryToAddTaskWithInvalidPayload(): void
{
$this->client->request(
'POST',
'/api/todo',
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['bad payload'], JSON_THROW_ON_ERROR)
);
$response = $this->client->getResponse();
self::assertEquals(400, $response->getStatusCode());
$body = json_decode($response->getContent(), true);
self::assertEquals('Invalid payload', $body['error']);
}
// ...
}
El test falla porque el endpoint devuelve un error 500 en lugar del error 400 que sería deseable en este caso. ¿Qué podemos hacer ahora?
Pues nos moveremos al nivel del controlador, para ver qué podemos hacer allí al respecto. Y tendremos que escribir otro test caracterizando la misma situación.
namespace App\Tests\TodoList\Infrastructure\EntryPoint\Api;
use App\TodoList\Application\AddTaskHandler;
use App\TodoList\Application\GetTaskListHandler;
use App\TodoList\Application\MarkTaskCompletedHandler;
use App\TodoList\Application\TaskListTransformer;
use App\TodoList\Infrastructure\EntryPoint\Api\TodoListController;
use PHPUnit\Framework\TestCase;
use Symfony\Component\HttpFoundation\Request;
class TodoListControllerTest extends TestCase
{
private const TASK_DESCRIPTION = 'Task Description';
private const COMPLETED_TASK_ID = 1;
private AddTaskHandler $addTaskHandler;
private TodoListController $todoListController;
private GetTaskListHandler $getTaskListHandler;
private TaskListTransformer $taskListTransformer;
private MarkTaskCompletedHandler $markTaskCompletedHandler;
protected function setUp(): void
{
$this->addTaskHandler = $this->createMock(AddTaskHandler::class);
$this->getTaskListHandler = $this->createMock(GetTaskListHandler::class);
$this->taskListTransformer = $this->createMock(TaskListTransformer::class);
$this->markTaskCompletedHandler = $this->createMock(MarkTaskCompletedHandler::cla\
ss);
$this->todoListController = new TodoListController(
$this->addTaskHandler,
$this->getTaskListHandler,
$this->taskListTransformer,
$this->markTaskCompletedHandler
);
}
// ...
/** @test */
public function shouldFailWithBadRequestIfInvalidPayload(): void
{
$request = new Request(
[],
[],
[],
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['invalid payload'], JSON_THROW_ON_ERROR)
);
$response = $this->todoListController->addTask($request);
self::assertEquals(400, $response->getStatusCode());
$body = json_decode($response->getContent(), true);
self::assertEquals('Invalid payload', $body['error']);
}
}
Fíjate que he eliminado que se haga alguna expectativa sobre el mock del caso de uso. En mi opinión se trata de un test que no aportaría nada en este caso y contribuye a acoplarnos a la implementación. Es cierto que eso ocurre en todos los test del controlador que tenemos hasta ahora, pero no hay razón para aumentar el acoplamiento.
Al ejecutar el test falla porque ya no encuentra el índice task cuando lo necesita en TodoListController:
public function addTask(Request $request): Response
{
$payload = $this->obtainPayload($request);
$this->addTaskHandler->execute($payload['task']);
return new JsonResponse('', Response::HTTP_CREATED);
}
Esto forma parte de la lógica del controlador por lo que no vamos a necesitar profundizar más. Si lo arreglamos aquí, habremos resuelto el problema.
Parece bastante claro que tenemos que chequear si la payload tiene la estructura correcta y responder en consecuencia:
namespace App\TodoList\Infrastructure\EntryPoint\Api;
use App\TodoList\Application\AddTaskHandler;
use App\TodoList\Application\GetTaskListHandler;
use App\TodoList\Application\MarkTaskCompletedHandler;
use App\TodoList\Application\TaskListTransformer;
use Symfony\Component\HttpFoundation\JsonResponse;
use Symfony\Component\HttpFoundation\Request;
use Symfony\Component\HttpFoundation\Response;
class TodoListController
{
private AddTaskHandler $addTaskHandler;
private GetTaskListHandler $getTaskListHandler;
private TaskListTransformer $taskListTransformer;
private MarkTaskCompletedHandler $markTaskCompletedHandler;
public function __construct(
AddTaskHandler $addTaskHandler,
GetTaskListHandler $getTaskListHandler,
TaskListTransformer $taskListTransformer,
MarkTaskCompletedHandler $markTaskCompletedHandler
) {
$this->addTaskHandler = $addTaskHandler;
$this->getTaskListHandler = $getTaskListHandler;
$this->taskListTransformer = $taskListTransformer;
$this->markTaskCompletedHandler = $markTaskCompletedHandler;
}
public function addTask(Request $request): Response
{
$payload = $this->obtainPayload($request);
if (!isset($payload['task'])) {
return new JsonResponse(['error' => 'Invalid payload'], Response::HTTP_BAD_RE\
QUEST);
}
$this->addTaskHandler->execute($payload['task']);
return new JsonResponse('', Response::HTTP_CREATED);
}
# ...
}
Con el test del controlador pasando, volvemos al de aceptación. Los ejecutamos todos y vemos que también pasan perfectamente.
Y con ello hemos resuelto el bug.
Valores de negocio no válidos
Una cosa es que el payload sea incorrecto estructuralmente, validación de la que se tiene que ocupar el controlador. Sin embargo, dado un payload estructuralmente válido, en el que el controlador pueda encontrar los valores que necesita, ¿qué ocurre si esos valores no son aceptables según las reglas de negocio?
Lo que ocurre es que la responsabilidad de detectar el problema está en los objetos de dominio, los cuales lanzarán excepciones que tienen que ir subiendo hasta que algún componente pueda gestionarlas.
Por ejemplo, en el caso de Task, esperamos que tenga alguna descripción. No ha sido definido en las historias de usuario, pero es algo que damos por hecho. Puede ocurrir, entonces, que la payload nos traiga un campo task con alguno de estos valores:
null- Un tipo de dato que no sea
string - Un string vacío o demasiado corto
- Un string de longitud suficiente
Los dos primeros puntos son particularmente técnicos. A nivel del controlador podríamos validar que task en un string y fallar si no es así.
Sin embargo, los dos últimos apuntan a reglas que tiene que definir negocio. Es decir, ¿consideraríamos aceptable una tarea con una descripción de dos caracteres? Es una decisión de negocio. Supongamos que nos dicen que nos basta con un carácter para admitir una cadena como descripción válida de una tarea, así que simplemente tendremos que controlar que no es una cadena vacía.
Esta regla, en todo caso, tendría que estar en el dominio, porque se trata de una regla de negocio.
Es más discutible la ubicación de las otras dos restricciones, que se pueden resumir en que el sistema no puede aceptar task si no es un string.
Pero lo mejor es ver esto partiendo de un test, así que vamos a introducir uno. En este caso, para comprobar qué pasa si task es null:
namespace App\Tests\Katas\TodoList;
use Symfony\Bundle\FrameworkBundle\Client;
use Symfony\Bundle\FrameworkBundle\Test\WebTestCase;
use Symfony\Component\HttpFoundation\Response;
class TodoListAcceptanceTest extends WebTestCase
{
private Client $client;
# ...
/** @test */
public function asUserITryToAddTaskWithABadTaskDescription(): void
{
$this->client->request(
'POST',
'/api/todo',
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['task' => null], JSON_THROW_ON_ERROR)
);
$response = $this->client->getResponse();
self::assertEquals(400, $response->getStatusCode());
$body = json_decode($response->getContent(), true);
self::assertEquals('Invalid payload', $body['error']);
}
# ...
}
Es muy interesante comprobar que este test pasa. Posiblemente, el arreglo del bug anterior ha evitado que nos encontremos con este.
¿Merece la pena dejar este test aquí? Yo diría que no, ya que no hemos tenido que añadir nada en el código. Lo aprovecharé para probar qué ocurriría si enviamos un dato que no sea string, como un número.
namespace App\Tests\Katas\TodoList;
use Symfony\Bundle\FrameworkBundle\Client;
use Symfony\Bundle\FrameworkBundle\Test\WebTestCase;
use Symfony\Component\HttpFoundation\Response;
class TodoListAcceptanceTest extends WebTestCase
{
private Client $client;
# ...
/** @test */
public function asUserITryToAddTaskWithABadTaskDescription(): void
{
$this->client->request(
'POST',
'/api/todo',
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['task' => 12345], JSON_THROW_ON_ERROR)
);
$response = $this->client->getResponse();
self::assertEquals(400, $response->getStatusCode());
$body = json_decode($response->getContent(), true);
self::assertEquals('Invalid payload', $body['error']);
}
# ...
}
Este test falla por el siguiente motivo:
TypeError : Argument 1 passed to App\TodoList\Application\AddTaskHandler::execute() must \
be of the type string, int given
Es decir. AddTaskHandler espera que pasemos un string en execute, por lo que nunca va a admitir un dato que no lo sea. Esto nos plantea un problema interesante y es si preferiríamos forzar el tipo string para la descripción de modo que si viene, como es el caso, un número lo convierta y siga adelante.
En este ejemplo vamos a suponer que no queremos eso, que el tipo ha de ser string sí o sí.
Como hemos visto, el fallo se ha producido también en el controlador, al intentar invocar el caso de uso. Por tanto, nos vamos de nuevo al test del controlador.
namespace App\Tests\TodoList\Infrastructure\EntryPoint\Api;
use App\TodoList\Application\AddTaskHandler;
use App\TodoList\Application\GetTaskListHandler;
use App\TodoList\Application\MarkTaskCompletedHandler;
use App\TodoList\Application\TaskListTransformer;
use App\TodoList\Infrastructure\EntryPoint\Api\TodoListController;
use PHPUnit\Framework\TestCase;
use Symfony\Component\HttpFoundation\Request;
class TodoListControllerTest extends TestCase
{
private const TASK_DESCRIPTION = 'Task Description';
private const COMPLETED_TASK_ID = 1;
private AddTaskHandler $addTaskHandler;
private TodoListController $todoListController;
private GetTaskListHandler $getTaskListHandler;
private TaskListTransformer $taskListTransformer;
private MarkTaskCompletedHandler $markTaskCompletedHandler;
protected function setUp(): void
{
$this->addTaskHandler = $this->createMock(AddTaskHandler::class);
$this->getTaskListHandler = $this->createMock(GetTaskListHandler::class);
$this->taskListTransformer = $this->createMock(TaskListTransformer::class);
$this->markTaskCompletedHandler = $this->createMock(MarkTaskCompletedHandler::cla\
ss);
$this->todoListController = new TodoListController(
$this->addTaskHandler,
$this->getTaskListHandler,
$this->taskListTransformer,
$this->markTaskCompletedHandler
);
}
# ...
/** @test */
public function shouldFailWithBadRequestIfInvalidTaskField(): void
{
$request = new Request(
[],
[],
[],
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['task' => 12345], JSON_THROW_ON_ERROR)
);
$response = $this->todoListController->addTask($request);
self::assertEquals(400, $response->getStatusCode());
$body = json_decode($response->getContent(), true);
self::assertEquals('Invalid payload', $body['error']);
}
}
El test del controlador falla de la misma forma que el de aceptación. A continuación implementamos lo necesario para hacerlo pasar.
namespace App\TodoList\Infrastructure\EntryPoint\Api;
use App\TodoList\Application\AddTaskHandler;
use App\TodoList\Application\GetTaskListHandler;
use App\TodoList\Application\MarkTaskCompletedHandler;
use App\TodoList\Application\TaskListTransformer;
use Symfony\Component\HttpFoundation\JsonResponse;
use Symfony\Component\HttpFoundation\Request;
use Symfony\Component\HttpFoundation\Response;
use function is_string;
class TodoListController
{
private AddTaskHandler $addTaskHandler;
private GetTaskListHandler $getTaskListHandler;
private TaskListTransformer $taskListTransformer;
private MarkTaskCompletedHandler $markTaskCompletedHandler;
public function __construct(
AddTaskHandler $addTaskHandler,
GetTaskListHandler $getTaskListHandler,
TaskListTransformer $taskListTransformer,
MarkTaskCompletedHandler $markTaskCompletedHandler
) {
$this->addTaskHandler = $addTaskHandler;
$this->getTaskListHandler = $getTaskListHandler;
$this->taskListTransformer = $taskListTransformer;
$this->markTaskCompletedHandler = $markTaskCompletedHandler;
}
public function addTask(Request $request): Response
{
$payload = $this->obtainPayload($request);
if (!isset($payload['task'])) {
return new JsonResponse(['error' => 'Invalid payload'], Response::HTTP_BAD_RE\
QUEST);
}
if (!is_string($payload['task'])) {
return new JsonResponse(['error' => 'Invalid payload'], Response::HTTP_BAD_RE\
QUEST);
}
$this->addTaskHandler->execute($payload['task']);
return new JsonResponse('', Response::HTTP_CREATED);
}
# ...
}
Este cambio hace pasar el test, y es de esperar que también el de aceptación, así que lo comprobamos. Recuerda que es muy importante pasar todos los tests, no solo el específico para el caso, ya que hay que asegurarse de que los cambios introducidos no alteran el comportamiento actual del sistema.
El test de aceptación pasa también. Ahora tenemos que pensar un par de cosas.
Por un lado, el código que hemos introducido es un poco feo y nos distrae del propósito del controlador. Necesitamos hacer un refactor que despeje un poco las cosas.
Esta es una posible solución:
namespace App\TodoList\Infrastructure\EntryPoint\Api;
use App\TodoList\Application\AddTaskHandler;
use App\TodoList\Application\GetTaskListHandler;
use App\TodoList\Application\MarkTaskCompletedHandler;
use App\TodoList\Application\TaskListTransformer;
use Symfony\Component\HttpFoundation\JsonResponse;
use Symfony\Component\HttpFoundation\Request;
use Symfony\Component\HttpFoundation\Response;
use function is_string;
class TodoListController
{
private AddTaskHandler $addTaskHandler;
private GetTaskListHandler $getTaskListHandler;
private TaskListTransformer $taskListTransformer;
private MarkTaskCompletedHandler $markTaskCompletedHandler;
public function __construct(
AddTaskHandler $addTaskHandler,
GetTaskListHandler $getTaskListHandler,
TaskListTransformer $taskListTransformer,
MarkTaskCompletedHandler $markTaskCompletedHandler
) {
$this->addTaskHandler = $addTaskHandler;
$this->getTaskListHandler = $getTaskListHandler;
$this->taskListTransformer = $taskListTransformer;
$this->markTaskCompletedHandler = $markTaskCompletedHandler;
}
public function addTask(Request $request): Response
{
$payload = $this->obtainPayload($request);
if (!$this->isValidPayload($payload)) {
return new JsonResponse(['error' => 'Invalid payload'], Response::HTTP_BAD_RE\
QUEST);
}
$this->addTaskHandler->execute($payload['task']);
return new JsonResponse('', Response::HTTP_CREATED);
}
# ...
private function isValidPayload(array $payload): bool
{
return isset($payload['task']) && is_string($payload['task']);
}
}
Es una primera aproximación. Podríamos avanzar más en ella, pero de momento es suficiente.
La otra cuestión es la siguiente. Los tests de aceptación que hemos añadido nos han servido para reproducir los bugs y guiarnos en la solución. Sin embargo, en el nivel unitario del controlador hemos hecho prácticamente el mismo test. Es más, el test de aceptación verifica exactamente el comportamiento que el test del controlador, ya que es este último el que tiene toda la responsabilidad sobre ese comportamiento.
Esta duplicación no siempre es útil. De hecho, para negocio, a quien interesa el test de aceptación, no le preocupa demasiado el tipo de problemas técnicos que estamos verificando. En cambio, en el nivel unitario este tipo de detalles es más relevante.
Así que en caso de tener tests en el nivel de aceptación que son idénticos a otros en el nivel unitario, es preferible eliminar los de aceptación si no aportan valor a negocio, teniendo cubierta la misma circunstancia en los unitarios.
Así que nosotros vamos a eliminar esos tests antes de continuar.
Garantizando reglas de dominio
Nuestro siguiente test verificará que una descripción vacía, aunque sea un string, no generará una tarea nueva. Lo pondremos en el test de aceptación:
namespace App\Tests\Katas\TodoList;
use Symfony\Bundle\FrameworkBundle\Client;
use Symfony\Bundle\FrameworkBundle\Test\WebTestCase;
use Symfony\Component\HttpFoundation\Response;
class TodoListAcceptanceTest extends WebTestCase
{
private Client $client;
# ...
/** @test */
public function asUserITryToAddTaskWithAnEmptyTaskDescription(): void
{
$this->client->request(
'POST',
'/api/todo',
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['task' => ''], JSON_THROW_ON_ERROR)
);
$response = $this->client->getResponse();
self::assertEquals(400, $response->getStatusCode());
$body = json_decode($response->getContent(), true);
self::assertEquals('Task description should not be empty', $body['error']);
}
# ...
}
Este test ya indica una violación de una regla de negocio. Este es el error que genera:
Nos indica que se estarían creando tareas con la descripción vacía como si fuesen válidas. Tenemos que profundizar en la aplicación para ver dónde deberíamos controlar el error.
Así que vamos al controlador. Pero este no tiene que saber nada de las reglas del negocio, ya que está en la capa de Infraestructura. Sin embargo, tiene que encargarse de dar la respuesta HTTP adecuada y eso solo es posible si el caso de uso le comunica de alguna forma que ha habido problemas.
La mejor forma que tiene de hacerlo es lanzando una excepción que el controlador capturará devolviendo una respuesta adecuada.
De este modo, el test del controlador podría quedar así:
namespace App\Tests\TodoList\Infrastructure\EntryPoint\Api;
use App\TodoList\Application\AddTaskHandler;
use App\TodoList\Application\GetTaskListHandler;
use App\TodoList\Application\MarkTaskCompletedHandler;
use App\TodoList\Application\TaskListTransformer;
use App\TodoList\Infrastructure\EntryPoint\Api\TodoListController;
use InvalidArgumentException;
use PHPUnit\Framework\TestCase;
use Symfony\Component\HttpFoundation\Request;
class TodoListControllerTest extends TestCase
{
private const TASK_DESCRIPTION = 'Task Description';
private const COMPLETED_TASK_ID = 1;
private AddTaskHandler $addTaskHandler;
private TodoListController $todoListController;
private GetTaskListHandler $getTaskListHandler;
private TaskListTransformer $taskListTransformer;
private MarkTaskCompletedHandler $markTaskCompletedHandler;
protected function setUp(): void
{
$this->addTaskHandler = $this->createMock(AddTaskHandler::class);
$this->getTaskListHandler = $this->createMock(GetTaskListHandler::class);
$this->taskListTransformer = $this->createMock(TaskListTransformer::class);
$this->markTaskCompletedHandler = $this->createMock(MarkTaskCompletedHandler::cla\
ss);
$this->todoListController = new TodoListController(
$this->addTaskHandler,
$this->getTaskListHandler,
$this->taskListTransformer,
$this->markTaskCompletedHandler
);
}
# ...
/** @test */
public function shouldFailWithBadRequestIfTaskDescriptionIsEmpty(): void
{
$exceptionMessage = 'Task description should not be empty';
$exception = new InvalidArgumentException($exceptionMessage);
$this->addTaskHandler
->method('execute')
->willThrowException($exception)
->with('');
$request = new Request(
[],
[],
[],
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['task' => ''], JSON_THROW_ON_ERROR)
);
$response = $this->todoListController->addTask($request);
self::assertEquals(400, $response->getStatusCode());
$body = json_decode($response->getContent(), true);
self::assertEquals($exceptionMessage, $body['error']);
}
}
Como se puede ver, simulamos que el caso de uso lanza una excepción y el test falla porque no se captura y, por tanto, no se devuelve una respuesta adecuada. Para no complicar la solución no voy a crear una excepción de dominio, cosa que haría en un proyecto real.
Hagamos pasar el test.
namespace App\TodoList\Infrastructure\EntryPoint\Api;
use App\TodoList\Application\AddTaskHandler;
use App\TodoList\Application\GetTaskListHandler;
use App\TodoList\Application\MarkTaskCompletedHandler;
use App\TodoList\Application\TaskListTransformer;
use InvalidArgumentException;
use Symfony\Component\HttpFoundation\JsonResponse;
use Symfony\Component\HttpFoundation\Request;
use Symfony\Component\HttpFoundation\Response;
use function is_string;
class TodoListController
{
private AddTaskHandler $addTaskHandler;
private GetTaskListHandler $getTaskListHandler;
private TaskListTransformer $taskListTransformer;
private MarkTaskCompletedHandler $markTaskCompletedHandler;
public function __construct(
AddTaskHandler $addTaskHandler,
GetTaskListHandler $getTaskListHandler,
TaskListTransformer $taskListTransformer,
MarkTaskCompletedHandler $markTaskCompletedHandler
) {
$this->addTaskHandler = $addTaskHandler;
$this->getTaskListHandler = $getTaskListHandler;
$this->taskListTransformer = $taskListTransformer;
$this->markTaskCompletedHandler = $markTaskCompletedHandler;
}
public function addTask(Request $request): Response
{
$payload = $this->obtainPayload($request);
if (!$this->isValidPayload($payload)) {
return new JsonResponse(['error' => 'Invalid payload'], Response::HTTP_BAD_RE\
QUEST);
}
try {
$this->addTaskHandler->execute($payload['task']);
} catch (InvalidArgumentException $invalidTaskDescription) {
return new JsonResponse(['error' => $invalidTaskDescription->getMessage()], R\
esponse::HTTP_BAD_REQUEST);
}
return new JsonResponse('', Response::HTTP_CREATED);
}
# ...
}
El test unitario del controlador ha pasado. Sin embargo, el test de aceptación no lo hace. Esto es porque el caso de uso no lo hemos tocado todavía. Tenemos que descender un poco más y hacer un test que pueda fallar para que nos diga qué implementar.
Pero primero, examinemos el código:
namespace App\TodoList\Application;
use App\TodoList\Domain\Task;
use App\TodoList\Domain\TaskRepository;
class AddTaskHandler
{
/** @var TaskRepository */
private TaskRepository $taskRepository;
public function __construct(TaskRepository $taskRepository)
{
$this->taskRepository = $taskRepository;
}
public function execute(string $taskDescription): void
{
$id = $this->taskRepository->nextIdentity();
$task = new Task($id, $taskDescription);
$this->taskRepository->store($task);
}
}
Como se puede ver, el punto en que se debería lanzar la excepción es cuando se crea una tarea (Task), pero no hay razón para que sea el caso de uso quien verifique que $taskDescription tiene una longitud suficiente.
En su lugar, tiene sentido que esta lógica esté en Task. Al fin y al cabo, el caso de uso no es un lugar para aplicar reglas de negocio, sino para coordinar objetos de dominio que son quienes tienen la responsabilidad de mantenerlas.
Así que tendríamos que ir un poco más adentro y modificar el test de Task para que garantice que siempre se construye de forma consistente, con una descripción que tiene al menos un carácter. En caso de que la descripción esté vacía, lanzaremos la excepción.
namespace App\Tests\TodoList\Domain;
use App\TodoList\Domain\Task;
use PHPUnit\Framework\TestCase;
use InvalidArgumentException;
class TaskTest extends TestCase
{
/** @test */
public function shouldNotAllowEmptyDescription(): void
{
$this->expectException(InvalidArgumentException::class);
new Task(1, '');
}
/** @test */
public function shouldProvideRepresentation(): void
{
$expected = '[ ] 1. Task Description';
$task = new Task(1, 'Task Description');
$representation = $task->representedAs('[:check] :id. :description');
self::assertEquals($expected, $representation);
}
/** @test */
public function shouldMarkTaskCompleted(): void
{
$expected = '[√] 1. Task Description';
$task = new Task(1, 'Task Description');
$task->markCompleted();
$representation = $task->representedAs('[:check] :id. :description');
self::assertEquals($expected, $representation);
}
}
Ahora quedaría implementarlo.
namespace App\TodoList\Domain;
use InvalidArgumentException;
class Task
{
private int $id;
private string $description;
private bool $completed;
public function __construct(int $id, string $description)
{
$this->id = $id;
if ($description === '') {
$exceptionMessage = 'Task description should not be empty';
throw new InvalidArgumentException($exceptionMessage);
}
$this->description = $description;
$this->completed = false;
}
public function id(): int
{
return $this->id;
}
public function representedAs(string $format): string
{
$values = [
':check' => $this->completed ? '√' : ' ',
':id' => $this->id,
':description' => $this->description
];
return strtr($format, $values);
}
public function markCompleted(): void
{
$this->completed = true;
}
}
Esta implementación es suficiente para que pase el test unitario. Veamos si también pasan los tests en los demás niveles. Así es, todos los tests unitarios siguen pasando y también lo hace el test de aceptación.
El test de aceptación que acabamos de introducir lo dejaremos ahí porque tiene significado de negocio. Además, el test del controlador en este caso solo verifica que este es capaz de gestionar la excepción lanzada por la capa de dominio, mientras que el test de Task verifica que esta se tiene que construir con una descripción adecuada.
Tareas no encontradas
Otro defecto de nuestra aplicación tiene que ver con intentar marcar como completada una tarea que no existe. Actualmente, el endpoint devolverá un error 500, cuando lo correcto sería un 404 indicando que el recurso que se quiere modificar no existe.
El siguiente test de aceptación lo pone de manifiesto:
namespace App\Tests\Katas\TodoList;
use Symfony\Bundle\FrameworkBundle\Client;
use Symfony\Bundle\FrameworkBundle\Test\WebTestCase;
use Symfony\Component\HttpFoundation\Response;
class TodoListAcceptanceTest extends WebTestCase
{
private Client $client;
# ...
/** @test */
public function asUserITryToMarkNotExistentTasksAsCompleted(): void
{
$this->givenIHaveAddedTasks(
[
'Write a test that fails',
'Write code to make the test pass',
]
);
$response = $this->apiMarkTaskCompleted(3);
self::assertEquals(404, $response->getStatusCode());
}
# ...
}
El resultado es:
Además de que hay un error en:
El error de base se produce en el repositorio. Sin embargo, vamos a proceder sistemáticamente. Como hemos visto en el ejemplo anterior, el error puede manifestarse de distintas maneras en las diferentes capas o niveles de la aplicación, por lo que tenemos que ir paso por paso, decidir si ese error tiene que manifestarse de algún modo e implementar el comportamiento necesario.
El controlador, como ya hemos visto anteriormente, es responsable de interpretar el problema y expresarlo con un error 404 en la respuesta. Por tanto, espera que el caso de uso le comunique eso con una excepción. En la práctica, significa que ese controlador tiene que reaccionar a una excepción determinada que lanzará o relanzará el caso de uso.
Así que expresamos eso en un test.
namespace App\Tests\TodoList\Infrastructure\EntryPoint\Api;
use App\TodoList\Application\AddTaskHandler;
use App\TodoList\Application\GetTaskListHandler;
use App\TodoList\Application\MarkTaskCompletedHandler;
use App\TodoList\Application\TaskListTransformer;
use App\TodoList\Infrastructure\EntryPoint\Api\TodoListController;
use InvalidArgumentException;
use PHPUnit\Framework\TestCase;
use OutOfBoundsException;
use Symfony\Component\HttpFoundation\Request;
class TodoListControllerTest extends TestCase
{
private const TASK_DESCRIPTION = 'Task Description';
private const COMPLETED_TASK_ID = 1;
private AddTaskHandler $addTaskHandler;
private TodoListController $todoListController;
private GetTaskListHandler $getTaskListHandler;
private TaskListTransformer $taskListTransformer;
private MarkTaskCompletedHandler $markTaskCompletedHandler;
protected function setUp(): void
{
$this->addTaskHandler = $this->createMock(AddTaskHandler::class);
$this->getTaskListHandler = $this->createMock(GetTaskListHandler::class);
$this->taskListTransformer = $this->createMock(TaskListTransformer::class);
$this->markTaskCompletedHandler = $this->createMock(MarkTaskCompletedHandler::cla\
ss);
$this->todoListController = new TodoListController(
$this->addTaskHandler,
$this->getTaskListHandler,
$this->taskListTransformer,
$this->markTaskCompletedHandler
);
}
# ...
/** @test */
public function shouldFailWithNotFoundIdCompletingNotExistentTask(): void
{
$exceptionMessage = 'Task 3 doesn\'t exist';
$exception = new OutOfBoundsException($exceptionMessage);
$this->markTaskCompletedHandler
->method('execute')
->willThrowException($exception);
$request = new Request(
[],
[],
[],
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['completed' => true], JSON_THROW_ON_ERROR)
);
$response = $this->todoListController->markTaskCompleted(self::COMPLETED_TASK_ID,\
$request);
self::assertEquals(400, $response->getStatusCode());
$body = json_decode($response->getContent(), true);
self::assertEquals($exceptionMessage, $body['error']);
}
}
Como era de esperar, el test del controlador fallará porque no se captura la excepción simulada en el mock. Nos toca implementar el código para hacerlo:
namespace App\TodoList\Infrastructure\EntryPoint\Api;
use App\TodoList\Application\AddTaskHandler;
use App\TodoList\Application\GetTaskListHandler;
use App\TodoList\Application\MarkTaskCompletedHandler;
use App\TodoList\Application\TaskListTransformer;
use InvalidArgumentException;
use OutOfBoundsException;
use Symfony\Component\HttpFoundation\JsonResponse;
use Symfony\Component\HttpFoundation\Request;
use Symfony\Component\HttpFoundation\Response;
use function is_string;
class TodoListController
{
private AddTaskHandler $addTaskHandler;
private GetTaskListHandler $getTaskListHandler;
private TaskListTransformer $taskListTransformer;
private MarkTaskCompletedHandler $markTaskCompletedHandler;
public function __construct(
AddTaskHandler $addTaskHandler,
GetTaskListHandler $getTaskListHandler,
TaskListTransformer $taskListTransformer,
MarkTaskCompletedHandler $markTaskCompletedHandler
) {
$this->addTaskHandler = $addTaskHandler;
$this->getTaskListHandler = $getTaskListHandler;
$this->taskListTransformer = $taskListTransformer;
$this->markTaskCompletedHandler = $markTaskCompletedHandler;
}
# ...
public function markTaskCompleted(int $taskId, Request $request): Response
{
$payload = $this->obtainPayload($request);
try {
$this->markTaskCompletedHandler->execute($taskId, $payload['completed']);
} catch (OutOfBoundsException $taskNotFound) {
return new JsonResponse(['error' => $taskNotFound->getMessage()], Response::H\
TTP_NOT_FOUND);
}
return new JsonResponse('', Response::HTTP_OK);
}
# ...
}
Dado que ahora el test pasa en el controlador, volvemos al nivel de aceptación. Este nivel todavía falla porque, de hecho, no se lanza realmente ninguna excepción en el flujo de esta acción.
Necesitamos ir un poco más adentro.
Si examinamos la capa de Aplicación, el caso de uso tiene poco que hacer. Al igual que en el problema anterior, su trabajo es delegar en objetos de dominio, por lo que son estos los que deben fallar. Como he señalado antes, estoy usando excepciones genéricas, pero en proyectos reales usaríamos también excepciones del dominio en distintos niveles. Por ejemplo, una TaskNotFound que perfectamente podría extender de OutOfBoundsException.
Así que no haremos nada en el caso de uso, pero observamos que el responsable de decir que una tarea no existe será el repositorio. La primera línea del método execute es clara.
namespace App\TodoList\Application;
use App\TodoList\Domain\TaskRepository;
class MarkTaskCompletedHandler
{
private TaskRepository $taskRepository;
public function __construct(TaskRepository $taskRepository)
{
$this->taskRepository = $taskRepository;
}
public function execute(int $taskId, bool $completed): void
{
$task = $this->taskRepository->retrieve($taskId);
if ($completed) {
$task->markCompleted();
}
$this->taskRepository->store($task);
}
}
No merece la pena escribir un test que simule que el repositorio lanza una excepción y el caso de uso no hace nada. Si el caso de uso capturase excepciones que vienen de un nivel más interno para relanzarlas como una excepción distinta, una técnica que podríamos denominar de anidado de excepciones, entonces sí lo haríamos para verificar eso.
Por tanto, nos vamos al nivel del repositorio y hacemos un test:
namespace App\Tests\TodoList\Infrastructure\Persistence;
use App\Lib\FileStorageEngine;
use App\TodoList\Domain\Task;
use App\TodoList\Domain\TaskRepository;
use App\TodoList\Infrastructure\Persistence\FileTaskRepository;
use PHPUnit\Framework\TestCase;
use Symfony\Component\DependencyInjection\Exception\OutOfBoundsException;
class FileTaskRepositoryTest extends TestCase
{
private FileStorageEngine $fileStorageEngine;
private TaskRepository $taskRepository;
public function setUp(): void
{
$this->fileStorageEngine = $this->createMock(FileStorageEngine::class);
$this->taskRepository = new FileTaskRepository($this->fileStorageEngine);
}
# ...
/** @test */
public function shouldFailIfTaskNotFound(): void
{
$storedTasks = [
1 => new Task(1, 'Write a test that fails'),
2 => new Task(2, 'Write code to make the test pass'),
];
$this->fileStorageEngine
->method('loadObjects')
->willReturn(
$storedTasks
);
$this->expectException(OutOfBoundsException::class);
$this->taskRepository->retrieve(3);
}
}
El test falla, puesto que no se lanza la excepción. Así que vamos al código de producción:
namespace App\TodoList\Infrastructure\Persistence;
use App\Lib\FileStorageEngine;
use App\TodoList\Domain\Task;
use App\TodoList\Domain\TaskRepository;
use OutOfBoundsException;
class FileTaskRepository implements TaskRepository
{
private FileStorageEngine $fileStorageEngine;
public function __construct(FileStorageEngine $fileStorageEngine)
{
$this->fileStorageEngine = $fileStorageEngine;
}
# ...
public function retrieve(int $taskId): Task
{
$tasks = $this->findAll();
if (!isset($tasks[$taskId])) {
throw new OutOfBoundsException(
sprintf('Task %s doesn\'t exist', $taskId)
);
}
return $tasks[$taskId];
}
# ...
}
Con esta sencilla solución hacemos pasar el test. Ejecutamos de nuevo el test de aceptación para ver si el problema está resuelto.
Resolviendo defectos
Una conclusión interesante sobre lo que acabamos de hacer es que, en realidad, resolver bugs no es más que implementar un comportamiento inexistente en el software. En este contexto, prefiero usar el término defecto en lugar de bug.
Es más, se podría argumentar que este capítulo más que tratar de resolución de bugs, trata de añadir características al software que se habían dejado atrás de manera consciente o no. En la vida real, este tipo de cosas se suele reportar como bug, aunque nosotros sepamos que es una feature no desarrollada todavía o que no tuvimos en cuenta en su momento.
De hecho, al desarrollar el software usando TDD normalmente evitamos el tipo de defectos que se asocia habitualmente con bugs, como podría ser un problema de tipado o algún despiste en el código que el lenguaje, por la razón que sea, permita que pase desapercibido.
En cualquier caso, el procedimiento es más o menos el siguiente:
- Lo primero es reproducir el bug mediante un test en el nivel más externo posible. Lo más seguro es que se manifieste en el test de aceptación y es lo esperable si es un problema detectado por las usuarias. Pero eso puede depender del contexto también.
- Seguidamente, vamos al siguiente nivel de la aplicación, intentando reproducir el mismo bug con un test unitario. Habrá niveles en que esto no sea posible y el test pase. Como hemos visto en el último ejemplo, la manifestación del bug en cada nivel puede ser diferente o puede no darse incluso. Si no podemos demostrar el bug en ese nivel, nos vamos al siguiente.
- En cada nivel, implementamos código para hacer que el test que demuestra el bug pase. Una vez que los tests de ese nivel están en verde, volvemos al test de aceptación.
- Si el test de aceptación continúa sin pasar, tendremos que ir un nivel más adentro en la aplicación, crear un test que describa el bug y resolverlo. Después de eso, volvemos al nivel de aceptación hasta que el test vuelva a pasar.
- En el momento en que el test de aceptación pase, es que ya está resuelto el defecto.
25 Introducción de nuevas características
En el capítulo anterior comentábamos que desde el punto del desarrollo basado en TDD los defectos pueden considerarse casi como features no definidas inicialmente. Otra forma de verlo es que son features cuando nos las piden explícitamente y son defecto cuando van implícitas en otra feature, pero no las hemos desarrollado.
Es decir, cuando decimos que queremos poder marcar una tarea como completada, por seguir con nuestro proyecto de lista de tareas, se asume que debería evitarse que el sistema se rompa si intentamos marcar una tarea inexistente. Por eso diríamos que esa feature tenía un defecto y es lo que hemos arreglado en el capítulo anterior.
Pero en este capítulo vamos a tratar sobre cómo añadir nuevas prestaciones a un software existente utilizando una aproximación TDD. Y, como cabe esperar, en realidad no vamos a introducir cambios en nuestra metodología. Seguiremos empezando con un test de aceptación y profundizando en la aplicación y los cambios necesarios.
Con todo se trata de un escenario distinto. Un nuevo comportamiento puede requerir modificar unidades de software existentes y necesitamos que los cambios no rompan funcionalidad ya creada.
Nueva historia de usuario
La siguiente petición de negocio es permitir editar una tarea existente.
US-4
- As a user
- I want to modify an existing task in the list
- So that, I can express my ideas better
Inicialmente, esta historia requiere crear un nuevo endpoint con el que cambiar la información de una tarea.
PUT /api/todo/{taskId}
Si nuestra aplicación tiene un front-end es posible que necesitemos un endpoint para recuperar la información de la tarea que queremos editar, a fin de poder rellenar el formulario con los datos actuales. En ese caso, sería:
GET /api/todo/{taskId}
En ambos casos, el procedimiento será el mismo: empezaremos creando un test de aceptación, iniciando el proceso de desarrollo. Lo que sí nos encontraremos es que algunos componentes necesarios están ya creados.
namespace App\Tests\Katas\TodoList;
use Symfony\Bundle\FrameworkBundle\Client;
use Symfony\Bundle\FrameworkBundle\Test\WebTestCase;
use Symfony\Component\HttpFoundation\Response;
class TodoListAcceptanceTest extends WebTestCase
{
private Client $client;
# ...
public function asUserIWantToModifyAnExistingTask(): void
{
$this->givenIHaveAddedTasks(
[
'Write a test that fails',
'Write code to make the test pass',
]
);
$this->client->request(
'PUT',
'/api/todo/2',
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['task' => 'Write production code to make the test pass'], JSON_T\
HROW_ON_ERROR)
);
$putResponse = $this->client->getResponse();
self::assertEquals(204, $putResponse->getStatusCode());
$response = $this->whenIRequestTheListOfTasks();
$this->thenICanSeeAddedTasksInTheList(
[
'[ ] 1. Write a test that fails',
'[ ] 2. Write production code to make the test pass',
],
$response
);
}
# ...
}
Así que ejecutamos el test para ver qué nos dice. Como era de esperar, el endpoint no se puede encontrar porque no tenemos la ruta, así que empezamos por definirla.
api_add_task:
path: /api/todo
controller: App\TodoList\Infrastructure\EntryPoint\Api\TodoListController::addTask
methods: ['POST']
api_get_task_list:
path: /api/todo
controller: App\TodoList\Infrastructure\EntryPoint\Api\TodoListController::getTaskList
methods: ['GET']
api_mark_task_completed:
path: /api/todo/{taskId}
controller: App\TodoList\Infrastructure\EntryPoint\Api\TodoListController::markTaskComp\
leted
methods: ['PATCH']
api_edit_task:
path: /api/todo/{taskId}
controller: App\TodoList\Infrastructure\EntryPoint\Api\TodoListController::modifyTask
methods: ['PUT']
Al volver a lanzar el test tras este cambio, nos indicará que no una acción en el controlador para responder a esta ruta.
"The controller for URI "/api/todo/2" is not callable. Expected method "modifyTask"
Así que tendremos que añadir una nueva acción vacía.
namespace App\TodoList\Infrastructure\EntryPoint\Api;
use App\TodoList\Application\AddTaskHandler;
use App\TodoList\Application\GetTaskListHandler;
use App\TodoList\Application\MarkTaskCompletedHandler;
use App\TodoList\Application\TaskListTransformer;
use InvalidArgumentException;
use OutOfBoundsException;
use Symfony\Component\HttpFoundation\JsonResponse;
use Symfony\Component\HttpFoundation\Request;
use Symfony\Component\HttpFoundation\Response;
use function is_string;
class TodoListController
{
private AddTaskHandler $addTaskHandler;
private GetTaskListHandler $getTaskListHandler;
private TaskListTransformer $taskListTransformer;
private MarkTaskCompletedHandler $markTaskCompletedHandler;
public function __construct(
AddTaskHandler $addTaskHandler,
GetTaskListHandler $getTaskListHandler,
TaskListTransformer $taskListTransformer,
MarkTaskCompletedHandler $markTaskCompletedHandler
) {
$this->addTaskHandler = $addTaskHandler;
$this->getTaskListHandler = $getTaskListHandler;
$this->taskListTransformer = $taskListTransformer;
$this->markTaskCompletedHandler = $markTaskCompletedHandler;
}
# ...
public function modifyTask(int $taskId, Request $request): Response
{
throw new \RuntimeException(sprintf('Implement %s', __METHOD__));
}
# ...
}
En la nueva ejecución del test, el error será:
Lo que nos dice que tenemos que entrar al nivel unitario para implementar esta acción en el controlador. Todo este ciclo te sonará porque es lo que hemos estado haciendo en toda esta parte del libro.
Pero lo cierto es que esta rutina es algo positivo. En cada momento siempre tenemos una tarea concreta que afrontar, ya sea crear un test, ya sea código de producción, y no tenemos que preocuparnos de ninguna otra cosa. El test de aceptación nos va diciendo qué hacer, y en cada nivel solo tenemos que pensar en ese componente concreto.
A nosotras ahora nos toca implementar el controlador. Como ya sabemos, en esta fase tenemos que diseñar. Básicamente, es una acción similar a la de añadir una tarea, pero en este caso recibimos el ID de la tarea que vamos a cambiar y su nueva descripción.
Necesitaremos un caso de uso que expresa esta intención de las usuarias al que le pasaremos los dos datos que necesitamos. Si todo va como es debido, devolvemos la respuesta 204 (no content).
Añadimos un test que recoge todo esto:
namespace App\Tests\TodoList\Infrastructure\EntryPoint\Api;
use App\TodoList\Application\AddTaskHandler;
use App\TodoList\Application\GetTaskListHandler;
use App\TodoList\Application\MarkTaskCompletedHandler;
use App\TodoList\Application\TaskListTransformer;
use App\TodoList\Infrastructure\EntryPoint\Api\TodoListController;
use InvalidArgumentException;
use PHPUnit\Framework\TestCase;
use OutOfBoundsException;
use Symfony\Component\HttpFoundation\Request;
class TodoListControllerTest extends TestCase
{
private const TASK_DESCRIPTION = 'Task Description';
private const COMPLETED_TASK_ID = 1;
private const TASK_ID = 1;
private AddTaskHandler $addTaskHandler;
private TodoListController $todoListController;
private GetTaskListHandler $getTaskListHandler;
private TaskListTransformer $taskListTransformer;
private MarkTaskCompletedHandler $markTaskCompletedHandler;
private UpdateTaskHandler $updateTaskHandler;
protected function setUp(): void
{
$this->addTaskHandler = $this->createMock(AddTaskHandler::class);
$this->getTaskListHandler = $this->createMock(GetTaskListHandler::class);
$this->taskListTransformer = $this->createMock(TaskListTransformer::class);
$this->markTaskCompletedHandler = $this->createMock(MarkTaskCompletedHandler::cla\
ss);
$this->updateTaskHandler = $this->createMock(UpdateTaskHandler::class);
$this->todoListController = new TodoListController(
$this->addTaskHandler,
$this->getTaskListHandler,
$this->taskListTransformer,
$this->markTaskCompletedHandler,
$this->updateTaskHandler
);
}
# ...
/** @test */
public function shouldModifyATask(): void
{
$this->updateTaskHandler
->expects(self::once())
->method('execute')
->with(self::TASK_ID, self::TASK_DESCRIPTION);
$request = new Request(
[],
[],
[],
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['task' => self::TASK_DESCRIPTION], JSON_THROW_ON_ERROR)
);
$response = $this->todoListController->modifyTask(self::TASK_ID,$request);
self::assertEquals(204, $response->getStatusCode());
}
# ...
}
Si ejecutamos el test nos pedirá crear el caso de uso UpdateTaskHandler.
namespace App\TodoList\Application;
class UpdateTaskHandler
{
}
Y seguidamente nos pedirá introducir el método execute.
namespace App\TodoList\Application;
class UpdateTaskHandler
{
public function execute()
{
throw new \RuntimeException(sprintf('Implement %s', __METHOD__));
}
}
Una vez que tenemos eso ya nos vuelve a pedir implementar la acción del controlador. Así que vamos a ello:
namespace App\TodoList\Infrastructure\EntryPoint\Api;
use App\TodoList\Application\AddTaskHandler;
use App\TodoList\Application\GetTaskListHandler;
use App\TodoList\Application\MarkTaskCompletedHandler;
use App\TodoList\Application\UpdateTaskHandler;
use App\TodoList\Application\TaskListTransformer;
use InvalidArgumentException;
use OutOfBoundsException;
use Symfony\Component\HttpFoundation\JsonResponse;
use Symfony\Component\HttpFoundation\Request;
use Symfony\Component\HttpFoundation\Response;
use function is_string;
class TodoListController
{
private AddTaskHandler $addTaskHandler;
private GetTaskListHandler $getTaskListHandler;
private TaskListTransformer $taskListTransformer;
private MarkTaskCompletedHandler $markTaskCompletedHandler;
private UpdateTaskHandler $updateTaskHandler;
public function __construct(
AddTaskHandler $addTaskHandler,
GetTaskListHandler $getTaskListHandler,
TaskListTransformer $taskListTransformer,
MarkTaskCompletedHandler $markTaskCompletedHandler,
UpdateTaskHandler $updateTaskHandler
) {
$this->addTaskHandler = $addTaskHandler;
$this->getTaskListHandler = $getTaskListHandler;
$this->taskListTransformer = $taskListTransformer;
$this->markTaskCompletedHandler = $markTaskCompletedHandler;
$this->updateTaskHandler = $updateTaskHandler;
}
# ...
public function modifyTask(int $taskId, Request $request): Response
{
$payload = $this->obtainPayload($request);
$this->updateTaskHandler->execute($taskId, $payload['task']);
return new JsonResponse('', Response::HTTP_NO_CONTENT);
}
# ...
}
Y el test unitario del controlador ya pasa. Si volvemos al test de aceptación, como corresponde ahora, nos dirá que es lo que tenemos que hacer a continuación:
Así que nos toca meternos en la capa de Aplicación. De nuevo, tenemos que diseñar este nivel, que nos plantea un problema interesante.
En principio hemos definido que lo que se puede cambiar en la tarea es su descripción, por lo que esta acción tiene que respetar el estado actual del flag de completado. Así que queremos obtener la tarea guardada, modificar su descripción y guardarla.
Por tanto, pediremos la tarea al repositorio, la cambiaremos y la guardaremos de nuevo.
namespace App\Tests\TodoList\Application;
use App\TodoList\Application\UpdateTaskHandler;
use App\TodoList\Domain\Task;
use App\TodoList\Domain\TaskRepository;
use PHPUnit\Framework\TestCase;
class UpdateTaskHandlerTest extends TestCase
{
private const TASK_ID = 1;
public function testShouldUpdateATask(): void
{
$task = new Task(self::TASK_ID, 'Task Description');
$taskRepository = $this->createMock(TaskRepository::class);
$taskRepository
->method('retrieve')
->with(self::TASK_ID)
->willReturn($task);
$taskRepository
->expects(self::once())
->method('store')
->with(new Task(self::TASK_ID, 'New Task Description'));
$updateTaskHandler = new UpdateTaskHandler($taskRepository);
$updateTaskHandler->execute(self::TASK_ID, 'New Task Description');
}
}
Cuando ejecutamos el test, nos pedirá implementar el caso de uso, puesto que el repositorio ya está definido con anterioridad.
La implementación seguramente nos forzará a introducir algún nuevo método en Task, de modo que se pueda actualizar la descripción. Esta implementación, por ejemplo:
namespace App\TodoList\Application;
use App\TodoList\Domain\TaskRepository;
class UpdateTaskHandler
{
private TaskRepository $taskRepository;
public function __construct(TaskRepository $taskRepository)
{
$this->taskRepository = $taskRepository;
}
public function execute(int $taskId, string $newTaskDescription): void
{
$task = $this->taskRepository->retrieve($taskId);
$task->updateDescription($newTaskDescription);
$this->taskRepository->store($task);
}
}
He elegido esta implementación para simplificar, sin embargo, a medida que hago esta prueba se me ocurren algunas ideas que podrían ser interesantes en un caso de uso realista, como podría ser aplicar cierta inmutabilidad. Es decir, en lugar de actualizar el objeto Task, crearíamos uno nuevo con nuevos valores.
Pero dejaremos estos refinamientos para otra ocasión. Si ejecutamos el test, nos dirá que Task carece del método updateDescription, que tendremos que desarrollar con ayuda de un test unitario.
namespace App\Tests\TodoList\Domain;
use App\TodoList\Domain\Task;
use PHPUnit\Framework\TestCase;
use InvalidArgumentException;
class TaskTest extends TestCase
{
/** @test */
public function shouldNotAllowEmptyDescription(): void
{
$this->expectException(InvalidArgumentException::class);
new Task(1, '');
}
/** @test */
public function shouldProvideRepresentation(): void
{
$expected = '[ ] 1. Task Description';
$task = new Task(1, 'Task Description');
$representation = $task->representedAs('[:check] :id. :description');
self::assertEquals($expected, $representation);
}
/** @test */
public function shouldMarkTaskCompleted(): void
{
$expected = '[√] 1. Task Description';
$task = new Task(1, 'Task Description');
$task->markCompleted();
$representation = $task->representedAs('[:check] :id. :description');
self::assertEquals($expected, $representation);
}
/** @test */
public function shouldUpdateDescription(): void
{
$expected = '[ ] 1. New Task Description';
$task = new Task(1, 'Task Description');
$task->updateDescription('New Task Description');
$representation = $task->representedAs('[:check] :id. :description');
self::assertEquals($expected, $representation);
}
}
Para hacer pasar el test tenemos que introducir el método.
namespace App\TodoList\Domain;
use InvalidArgumentException;
class Task
{
private int $id;
private string $description;
private bool $completed;
public function __construct(int $id, string $description)
{
$this->id = $id;
if ($description === '') {
$exceptionMessage = 'Task description should not be empty';
throw new InvalidArgumentException($exceptionMessage);
}
$this->description = $description;
$this->completed = false;
}
public function id(): int
{
return $this->id;
}
public function representedAs(string $format): string
{
$values = [
':check' => $this->completed ? '√' : ' ',
':id' => $this->id,
':description' => $this->description
];
return strtr($format, $values);
}
public function markCompleted(): void
{
$this->completed = true;
}
public function updateDescription(string $newTaskDescription): void
{
$this->description = $newTaskDescription;
}
}
El test pasa, pero nos hemos dado cuenta un problema. Hace nada hemos implementado una validación para impedir que Task::description pueda ser una cadena vacía. Para asegurar que cumplimos esta regla de negocio, deberíamos introducir otro test que lo verifique e implementar la respuesta que queramos dar a este caso.
Sin embargo, esto no lo hemos cubierto en el nivel de aceptación o en el del controlador. ¿Qué deberíamos hacer entonces? ¿Resolverlo ahora y añadir tests en los otros niveles después o esperar y añadir esa protección en una nueva iteración?
En este caso, creo que la mejor respuesta es tomar nota de esto y resolverlo en un nuevo ciclo. Es importante centrarnos ahora en la característica que estamos desarrollando y terminar este ciclo.
Por tanto, al hacer pasar el test unitario de Task, volvemos primero al test de UpdateTaskHandler y comprobamos si ya pasa, cosa que ocurre.
Y con este nivel en verde, probamos de nuevo en el de aceptación, que también pasa sin más problemas.
El resultado es que la nueva historia está implementada, aunque como hemos descubierto necesitamos hacer una iteración para prevenir el problema de intentar cambiar la descripción de una historia con un valor no válido.
¿Lo hubiésemos podido prevenir antes? Puede ser, sin embargo, igualmente necesitaríamos introducir tests en los distintos niveles, al igual que hicimos en el capítulo anterior. El valor de usar TDD es justamente desarrollar una serie de hábitos de pensamiento y una cierta automatización. En otras palabras, desarrollar una disciplina y llegar a todos los objetivos paso a paso.
Completar la historia
En cualquier caso, todo nuevo comportamiento del sistema tendría que estar definido mediante un test. Así que necesitaremos un test para incluir el cumplimiento de la regla de negocio, lo que nos lleva de nuevo al nivel de aceptación.
Puesto que es una regla de negocio, este test lo conservaremos después.
namespace App\Tests\Katas\TodoList;
use Symfony\Bundle\FrameworkBundle\Client;
use Symfony\Bundle\FrameworkBundle\Test\WebTestCase;
use Symfony\Component\HttpFoundation\Response;
class TodoListAcceptanceTest extends WebTestCase
{
private Client $client;
# ..
/** @test */
public function asUserITryToUpdateTaskWithAnEmptyTaskDescription(): void
{
$this->givenIHaveAddedTasks(
[
'Write a test that fails',
'Write code to make the test pass',
]
);
$this->client->request(
'PUT',
'/api/todo/1',
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['task' => ''], JSON_THROW_ON_ERROR)
);
$response = $this->client->getResponse();
self::assertEquals(400, $response->getStatusCode());
$body = json_decode($response->getContent(), true);
self::assertEquals('Task description should not be empty', $body['error']);
}
# ...
}
El test falla:
Lo que nos indica que se pueden crear tareas y modificarlas vaciando la descripción.
Ahora veamos cómo solucionar esto. Con la información disponible no tenemos una pista sobre dónde hay que intervenir.
Matizo: obviamente sabemos que hay que añadir una validación en el método updateDescription que hemos añadido en Task. Sin embargo, saltarnos los pasos solo nos llevaría a generar puntos ciegos en el desarrollo. No basta con lanzar una excepción desde Task, tenemos que asegurarnos de que el componente adecuado la captura y reacciona de la forma adecuada. Proceder sistemáticamente nos ayudará a evitar estos riesgos.
De hecho, el componente que tiene la responsabilidad de comunicarse en primera instancia con el test de aceptación es el controlador y, como ya hemos visto, es quien produce el código de respuesta que evaluamos en el test de aceptación. Por tanto, es el primer lugar en el que vamos a intervenir. Por supuesto, definiendo con un test el comportamiento que esperamos.
namespace App\Tests\TodoList\Infrastructure\EntryPoint\Api;
use App\TodoList\Application\AddTaskHandler;
use App\TodoList\Application\GetTaskListHandler;
use App\TodoList\Application\MarkTaskCompletedHandler;
use App\TodoList\Application\UpdateTaskHandler;
use App\TodoList\Application\TaskListTransformer;
use App\TodoList\Infrastructure\EntryPoint\Api\TodoListController;
use InvalidArgumentException;
use PHPUnit\Framework\TestCase;
use OutOfBoundsException;
use Symfony\Component\HttpFoundation\Request;
class TodoListControllerTest extends TestCase
{
private const TASK_DESCRIPTION = 'Task Description';
private const COMPLETED_TASK_ID = 1;
private const TASK_ID = 1;
private AddTaskHandler $addTaskHandler;
private TodoListController $todoListController;
private GetTaskListHandler $getTaskListHandler;
private TaskListTransformer $taskListTransformer;
private MarkTaskCompletedHandler $markTaskCompletedHandler;
private UpdateTaskHandler $updateTaskHandler;
protected function setUp(): void
{
$this->addTaskHandler = $this->createMock(AddTaskHandler::class);
$this->getTaskListHandler = $this->createMock(GetTaskListHandler::class);
$this->taskListTransformer = $this->createMock(TaskListTransformer::class);
$this->markTaskCompletedHandler = $this->createMock(MarkTaskCompletedHandler::cla\
ss);
$this->updateTaskHandler = $this->createMock(UpdateTaskHandler::class);
$this->todoListController = new TodoListController(
$this->addTaskHandler,
$this->getTaskListHandler,
$this->taskListTransformer,
$this->markTaskCompletedHandler,
$this->updateTaskHandler
);
}
# ...
/** @test */
public function shouldFailWithBadRequestIfTaskDescriptionIsEmptyWhenUpdating(): void
{
$exceptionMessage = 'Task description should not be empty';
$exception = new InvalidArgumentException($exceptionMessage);
$this->updateTaskHandler
->method('execute')
->willThrowException($exception)
->with(1, '');
$request = new Request(
[],
[],
[],
[],
[],
['CONTENT-TYPE' => 'json/application'],
json_encode(['task' => ''], JSON_THROW_ON_ERROR)
);
$response = $this->todoListController->modifyTask(1, $request);
self::assertEquals(400, $response->getStatusCode());
$body = json_decode($response->getContent(), true);
self::assertEquals($exceptionMessage, $body['error']);
}
}
Al ejecutar el test en este nivel, vemos que falla porque se tira la excepción y no se controla. Implementamos la gestión de excepciones exactamente igual que en la acción de crear.
namespace App\TodoList\Infrastructure\EntryPoint\Api;
use App\TodoList\Application\AddTaskHandler;
use App\TodoList\Application\GetTaskListHandler;
use App\TodoList\Application\MarkTaskCompletedHandler;
use App\TodoList\Application\UpdateTaskHandler;
use App\TodoList\Application\TaskListTransformer;
use InvalidArgumentException;
use OutOfBoundsException;
use Symfony\Component\HttpFoundation\JsonResponse;
use Symfony\Component\HttpFoundation\Request;
use Symfony\Component\HttpFoundation\Response;
use function is_string;
class TodoListController
{
private AddTaskHandler $addTaskHandler;
private GetTaskListHandler $getTaskListHandler;
private TaskListTransformer $taskListTransformer;
private MarkTaskCompletedHandler $markTaskCompletedHandler;
private UpdateTaskHandler $updateTaskHandler;
public function __construct(
AddTaskHandler $addTaskHandler,
GetTaskListHandler $getTaskListHandler,
TaskListTransformer $taskListTransformer,
MarkTaskCompletedHandler $markTaskCompletedHandler,
UpdateTaskHandler $updateTaskHandler
) {
$this->addTaskHandler = $addTaskHandler;
$this->getTaskListHandler = $getTaskListHandler;
$this->taskListTransformer = $taskListTransformer;
$this->markTaskCompletedHandler = $markTaskCompletedHandler;
$this->updateTaskHandler = $updateTaskHandler;
}
# ...
public function markTaskCompleted(int $taskId, Request $request): Response
{
$payload = $this->obtainPayload($request);
try {
$this->markTaskCompletedHandler->execute($taskId, $payload['completed']);
} catch (OutOfBoundsException $taskNotFound) {
return new JsonResponse(['error' => $taskNotFound->getMessage()], Response::H\
TTP_NOT_FOUND);
}
return new JsonResponse('', Response::HTTP_OK);
}
public function modifyTask(int $taskId, Request $request): Response
{
$payload = $this->obtainPayload($request);
try {
$this->updateTaskHandler->execute($taskId, $payload['task']);
} catch (\InvalidArgumentException $invalidTaskDescription) {
return new JsonResponse(['error' => $invalidTaskDescription->getMessage()], R\
esponse::HTTP_BAD_REQUEST);
}
return new JsonResponse('', Response::HTTP_NO_CONTENT);
}
# ...
}
Esto hace que el test de controlador pase. Si chequeamos el test de aceptación vemos que sigue dando el mismo error.
El siguiente nivel es el caso de uso, que como hemos visto antes, es irrelevante porque simplemente dejará subir la excepción. Como ya sabemos, es Task quien se debe responsabilizar, así que ahora es el momento de abordar ese cambio, definiendo el comportamiento deseado en el test:
namespace App\Tests\TodoList\Domain;
use App\TodoList\Domain\Task;
use PHPUnit\Framework\TestCase;
use InvalidArgumentException;
class TaskTest extends TestCase
{
/** @test */
public function shouldNotAllowEmptyDescription(): void
{
$this->expectException(InvalidArgumentException::class);
new Task(1, '');
}
/** @test */
public function shouldProvideRepresentation(): void
{
$expected = '[ ] 1. Task Description';
$task = new Task(1, 'Task Description');
$representation = $task->representedAs('[:check] :id. :description');
self::assertEquals($expected, $representation);
}
/** @test */
public function shouldMarkTaskCompleted(): void
{
$expected = '[√] 1. Task Description';
$task = new Task(1, 'Task Description');
$task->markCompleted();
$representation = $task->representedAs('[:check] :id. :description');
self::assertEquals($expected, $representation);
}
/** @test */
public function shouldUpdateDescription(): void
{
$expected = '[ ] 1. New Task Description';
$task = new Task(1, 'Task Description');
$task->updateDescription('New Task Description');
$representation = $task->representedAs('[:check] :id. :description');
self::assertEquals($expected, $representation);
}
/** @test */
public function shouldFailUpdatingWithInvalidDescription(): void
{
$this->expectException(InvalidArgumentException::class);
$task = new Task(1, 'Task Description');
$task->updateDescription('');
}
}
Al no haber nada implementado, el test fallará.
Empezamos con una implementación bastante obvia:
namespace App\TodoList\Domain;
use InvalidArgumentException;
class Task
{
private int $id;
private string $description;
private bool $completed;
public function __construct(int $id, string $description)
{
$this->id = $id;
if ($description === '') {
$exceptionMessage = 'Task description should not be empty';
throw new InvalidArgumentException($exceptionMessage);
}
$this->description = $description;
$this->completed = false;
}
public function id(): int
{
return $this->id;
}
public function representedAs(string $format): string
{
$values = [
':check' => $this->completed ? '√' : ' ',
':id' => $this->id,
':description' => $this->description
];
return strtr($format, $values);
}
public function markCompleted(): void
{
$this->completed = true;
}
public function updateDescription(string $newTaskDescription): void
{
if ($newTaskDescription === '') {
$exceptionMessage = 'Task description should not be empty';
throw new InvalidArgumentException($exceptionMessage);
}
$this->description = $newTaskDescription;
}
}
El test unitario de Task ya está en verde. Antes de nada, volvemos a lanzar el test de aceptación para ver si hemos resuelto el problema y no nos hemos dejado ningún cabo suelto. Y todo funciona.
Sin embargo, podríamos refactorizar un poco nuestra solución, ya que estamos intentando mantener la misma regla de negocio en dos lugares. Deberíamos unificarlo. Para ello utilizaremos auto-encapsulación. Es decir, crearemos un método privado con el cual asignar el valor de la descripción y validarlo. Así queda Task con este cambio.
namespace App\TodoList\Domain;
use InvalidArgumentException;
class Task
{
private int $id;
private string $description;
private bool $completed;
public function __construct(int $id, string $description)
{
$this->id = $id;
$this->setDescription($description);
$this->completed = false;
}
public function id(): int
{
return $this->id;
}
public function representedAs(string $format): string
{
$values = [
':check' => $this->completed ? '√' : ' ',
':id' => $this->id,
':description' => $this->description
];
return strtr($format, $values);
}
public function markCompleted(): void
{
$this->completed = true;
}
public function updateDescription(string $newTaskDescription): void
{
$this->setDescription($newTaskDescription);
}
private function setDescription(string $description): void
{
if ($description === '') {
$exceptionMessage = 'Task description should not be empty';
throw new InvalidArgumentException($exceptionMessage);
}
$this->description = $description;
}
}
Y con esto, hemos implementado la nueva historia de usuario. Te habrás dado cuenta de que en todos los casos, ya sean nuevas historias de usuario, modificación de prestaciones o corrección de defectos, nuestro procedimiento es siempre el mismo. Definir el comportamiento deseado del sistema mediante un test y añadir el código de producción que sea necesario para hacerlo pasar.
Epílogo
26 TDD y calidad de vida (la tuya)
Ya sea como empleados o freelance vendemos nuestro tiempo y trabajo a empresas y clientes. Una cosa que distingue nuestra profesión de otras es el hecho de que vendemos trabajo intelectual. A veces, incluso, trabajo intelectual de alto nivel.
Así que cuidar de nuestra mente e inteligencia parece ser una actividad razonable que deberíamos practicar con frecuencia.
Hay mucha gente en el mundo del desarrollo de software que piensa, o incluso afirma, que hacer testing es duro o caro. Y eso sin mencionar el Test Driven Development. Pero lo que queremos demostrar es que TDD es el camino más recomendable si quieres tener una vida más sana en el campo del desarrollo de software.
Pero primero, veamos un par de cuestiones acerca de cómo funciona nuestro cerebro.
Conocimiento en el mundo, conocimiento en la cabeza
Puertas
¿Sabes utilizar una puerta? ¿Segura? ¿Has visto alguna vez una puerta con manual de instrucciones? Yo sí. Montones de ellas en realidad: todas esas que tienen letreros indicando si se debe empujar o tirar. Me apuesto algo a que te has encontrado con más de una de esas.
¿Te has visto alguna vez ante una puerta cerrada sin saber cómo abrirla? Yo sí. De hecho las hay por docenas en el mundo, como puertas deslizantes con sensores que no están bien ajustados, o puertas que abren hacia adentro cuando todo indica que abren hacia fuera.
El caso es que una puerta debería ser algo fácil de usar y no siempre sucede. La forma en que se usa una puerta debería ser obvia, ¿no?
Interruptores
¿Y qué tal si hablamos de interruptores? Me refiero a esos paneles de interruptores cuya disposición no está relacionada con la de las luces que controlan. A veces están situados en lugares en donde no se pueden ver las lámparas y necesitas probar varias veces hasta encontrar la combinación secreta que enciende la lámpara que quieres.
La relación entre un interruptor y la lámpara que controla debería ser obvia, ¿no?
Hablemos de lo obvio
Cuando hablamos de algo obvio, nos referimos a conocimiento que no deberíamos tener que buscar en nuestra cabeza. El conocimiento está ahí, en el mundo. Solo tenemos que usarlo mientras hacemos otras cosas. Queremos poder abrir puertas y encender luces sin tener que pensar ni una fracción de segundo acerca de ello.
Por eso, cuando nos vemos obligadas a pensar en cosas que deberían ser obvias, estamos desperdiciando parte de nuestros recursos mentales, utilizando espacio en nuestra memoria de trabajo que preferiríamos, o incluso deberíamos, estar empleando en otros propósitos.
El conocimiento está en el mundo cuando todas las pistas que necesitamos para usar o interactuar con un objeto están presentes en el objeto mismo. Por eso no necesitamos preocuparnos, razonar o recordar cómo utilizarlos. Si necesitamos hacerlo, es decir cuando necesitamos razonar o recordar instrucciones, tenemos que poner el conocimiento en nuestra cabeza para poder alcanzar nuestro objetivo.
Por esto, si disponemos de más conocimiento en el mundo cuando ejecutamos una tarea, necesitamos menos conocimiento la cabeza, dejando espacio libre en ella que podemos usar para pensar mejor acerca de lo que estamos haciendo.
Cuanto menos tengamos que pensar en la forma de usar las herramientas, más podemos pensar en lo que estamos haciendo con ellas.
Pero, ¿de cuánto espacio disponemos en nuestra memoria de trabajo?
Bueno…, el caso es que no mucho.
La capacidad de nuestra memoria de trabajo
Disponemos de una capacidad de almacenamiento prácticamente infinita es nuestra memoria. Piensa en ella como un enorme e inteligente disco duro que puede guardar recuerdos y datos durante años. No se trata de un almacén pasivo. De hecho, reconstruye nuestra memoria constantemente para guardar y recuperar cosas. Esto es importante, porque cuando lo pensamos, necesitamos usar nuestra memoria de trabajo para mantener los datos que estamos usando. Muy parecido a un ordenador.
Sin embargo, nuestra memoria de trabajo es bastante diferente de nuestra memoria a largo plazo. Hay quien la llama “memoria a corto plazo” y hay quien “memoria de trabajo”. Creo que podemos verla como un procesador, con algunos registros que pueden almacenar una cantidad limitada de unidades de información llamadas chunks mientras trabaja. Los chunks pueden tener un tamaño variable, pero son unidades significativas.
Como nos dedicamos a la programación, una buena forma de entender de estos chunks es pensar que son punteros que indican posiciones de memoria. En esas posiciones puede haber estructuras de cualquier tamaño. A veces son muy pequeñas, como una letra o un número, y otras veces son enormes.
¿Puedes recordar un número de teléfono? Me apuesto a que has agrupado los dígitos de modo que solo tines dos o tres números que retener.
Esto es porque nuestro procesador puede manejar un número limitado de chunks. Este número es aproximadamente 7 (más o menos dos). Es algo que varía con la edad y entre los individuos, pero es una aproximación muy buena. Por tanto, intentamos ahorrar tantos registros como podemos, agrupando la información en chunks, y manteniendo alguno de los registros libre.
¿Qué sucede ti llenamos todos los registros? Pues la precisión y la velocidad al realizar la tarea disminuyen, aumentando los errores. En general, el desempeño es peor si tratamos de mantener muchas cosas en nuestra memoria de trabajo al mismo tiempo.
Por supuesto, se trata de una sobre simplificación. Sin embargo, creo que puedes hacerte una idea. Podemos reducir la sobrecarga si ponemos el conocimiento el mundo, en lugar de mantenerlo en nuestra cabeza, con lo que nuestro desempeño será mejor en cualquier tarea.
Puedes poner conocimiento fuera de la memoria de trabajo mediante la práctica. Eso es lo que ocurre cuando introducimos una nueva técnica, intentamos aplicar una novedad del lenguaje de programación o utilizar una nueva herramienta. Al principio vamos lentos y cometemos errores. Necesitamos tiempo para automatizar cosas en nuestra mente mientras ponemos conocimiento en el mundo.
Es hora de volver al objetivo principal de este artículo. Hablemos acerca de nuestra vida como desarrolladora.
Un día en la vida
Programando sin test
Analicemos por un momento qué sucede cuando programamos sin hacer tests.
De hecho, en realidad siempre hacemos tests, pero con frecuencia tendemos a que sean manuales. Lo llamamos “depurar”. Usamos un proceso de prueba y error: ¿Esto funciona? ¿No…? Prueba otra vez. ¿Sí…? Sigue adelante.
Intentamos escribir código y verificar que funciona al mismo tiempo que lo escribimos, hasta que nos parece que está terminado. Tras eso, intentamos verificar que el código funciona como un todo. Entonces descubrimos que habíamos olvidado algunos detalles… Tras eso, desplegamos y descubrimos nuevos detalles que no funcionan, así que necesitamos corregirlos.
Al final del día, nos encontramos con grandes dolores de cabeza y bajo la impresión de habernos perdido algo.
Esto sucede porque intentamos mantener toda la información en la cabeza al mismo tiempo (recuerda que tiene capacidad limitada). Nos sobrecargamos nosotras mismas. La mejor estrategia es hacer una lista de metas y tareas, y ayudarnos a mantener cierta organización y foco con estos soportes externos.
Por ejemplo: escribir un simple endpoint para una API necesita un montón de cosas:
1. Una acción en un controlador
2. Una ruta a ese controlador
3. Un caso de uso o comando que ejecute la acción
4. Probablemente una o más entidades de dominio y su repositorio
5. La definición en el contenedor de dependencias
6. Posiblemente algún servicio
7. La definición del mismo en el contenedor de dependencias
8. Un objeto de respuesta
9. etc.
Con esto nuestra memoria se sobrecarga, ya que superamos ampliamente los 7+/-2 items. Esto explica por qué nos sentimos cansadas y estresadas, con el sentimiento de que podríamos haber olvidado algo. E inseguras sobre los que estamos haciendo o si nos hemos dejado atrás algo importante.
Así que, echemos una mirada a cómo ejecutaríamos el mismo proceso, esta vez con testing al final.
Programando con tests al final
En realidad es casi lo mismo, pero ahora hay tests al final del proceso. La clase de tests que automatizamos.
El resultado final es mejor, porque ahora tenemos más confianza con el código. Pero seguimos teniendo ese mismo dolor de cabeza al final del día.
Sí. Hemos hecho la misma cantidad de trabajo, con la misma sobrecarga mental y con el añadido de tener que escribir una suite de tests, mientras nuestro cerebro nos grita: “¡Hey! ¡Pero si el trabajo está terminado! ¿Qué estás haciendo?”
En estas condiciones, puede que nuestros tests no sean los mejores tests del mundo. Ni la suite cubra todos los escenarios posibles.
De hecho, ya estamos cansadas cuando empezamos la fase de testing. Esto explica por qué mucha gente piensa que el testing es duro y hasta que es doloroso.
Así que los test mejoran nuestra confianza en el código, pero al coste de obligarnos a un montón de trabajo extra. Nuestra vida no es mejor con tests, incluso si dormimos mejor por la noche. Entonces, ¿qué es lo que está mal?
Para mejorar tu vida deberías probar una aproximación diferente. Debería probar Test Driven Development.
Programando con TDD
En esto consiste TDD: una cosa cada vez y posponer decisiones.
- Un test sencillo que falle: no escribas código mientras no tengas un test.
- Añade código que haga pasar el test: no escribas ni más ni menos de lo necesario.
- Revisa el código para mejorar cosas, pero no implementes nada nuevo y mantienes los tests existentes pasando.
Veamos el proceso desde el punto de vista de nuestro modelo de la memoria de trabajo. Cuando escribimos el primer test que falla estamos enfocándonos en este test. Por tanto, no tenemos que poner atención a nada más fuera de eso. Escribir el test también significa que ponemos el conocimiento que necesitamos en el mundo. Nuestra memoria está casi desocupada.
A continuación, nos enfocamos en escribir el código necesario para hacer que el test pase. El conocimiento que necesitamos está en el test, no en nuestra cabeza, y es lo que necesitamos para conseguir el objetivo inmediato.
Solo tenemos que pensar en una forma de hacer que el test pase. Si es el primer test, solo necesitamos escribir la implementación más obvia que sea posible. Incluso si esa implementación es tan simple como devolver la misma respuesta esperada por el test.
Y una vez que el test ha pasado, podemos echar un vistazo al código y ver si podemos hacer mejoras mediante refactoring. No tenemos que añadir prestaciones. Debemos mantener el test pasando mientras ordenamos las cosas, eliminando duplicación innecesaria, introduciendo mejores nombres, etc.
Repetiremos el ciclo hasta tener la funcionalidad completamente implementada. No necesitamos escribir tests extras, no tenemos el riesgo de haber olvidado nada. Nuestra cabeza no duele. Hemos usado el cerebro para pensar evitando la sobrecarga.
No es magia, es TDD. Por supuesto, para lograr esto se necesita entrenamiento. TDD es una herramienta intelectual, y el uso de una herramienta debe automatizarse. Por tanto, deberías hacer ejercicios, como las katas, tanto individualmente, como con la ayuda de colegas, en una comunidad de práctica, de la forma que mejor te convenga a ti o a tu equipo. Practicar, practicar y practicar. Una vez que seas capaz de proceder paso a paso, descubrirás que estás más feliz y menos estresada en el medio y largo plazo.
Un consejo final
Almacena la mayor cantidad de conocimiento que necesites en el mundo: usa un backlog, usa post-its, escribe una lista de tareas, dibujas esquemas, modelos, mapas conceptuales… Liberta tu cabeza y deja espacio para trabajar en una cosa cada vez.
TDD es más que escribir tests. Es poner el conocimiento que necesitas en el código y liberar tu mente. Es posponer decisiones hasta el momento en que estés lista para tomarlas.
De verdad, prueba TDD, tu vida como desarrolladora mejorará.
Notas
Conceptos básicos de TDD
¿Qué es TDD y por qué debería importarme?
1https://en.wikipedia.org/wiki/Test-driven_development↩
2http://derekbarber.ca/blog/2012/03/27/why-test-driven-development/↩
3https://pdfs.semanticscholar.org/ad0f/dd36aa09d25b739b1649bfa5e20c9e46eb65.pdf↩
4https://shorturl.at/kdR0j↩
5https://www.thedroidsonroids.com/blog/pros-of-tdd-test-driven-development-for-business↩
6https://medium.com/@philborlin/tdd-is-about-design-not-testing-e42af0b28475↩
7https://codurance.com/2015/05/12/does-tdd-lead-to-good-design/↩
8https://www.thoughtworks.com/insights/blog/using-tdd-influence-design↩
Coding-dojo y katas
1https://pragprog.com/titles/tpp20/the-pragmatic-programmer-20th-anniversary-edition/↩
2https://katalyst.codurance.com↩
3https://kata-log.rocks/index.html↩
4http://codingdojo.org↩
5http://codekata.com↩
6http://agilekatas.co.uk↩
7http://www.butunclebob.com/ArticleS.UncleBob.TheProgrammingDojo)↩
8http://codingdojo.org/WhatIsCodingDojo/↩
9https://link.springer.com/chapter/10.1007%2F11499053_54↩
TDD clásica
Las leyes de TDD
1http://butunclebob.com/ArticleS.UncleBob.TheThreeRulesOfTdd↩
2https://www.youtube.com/watch?v=AoIfc5NwRks↩
3http://www.javiersaldana.com/articles/tech/refactoring-the-three-laws-of-tdd↩
4https://es.slideshare.net/CiaranMcNulty/tdd-with-phpspec↩
5https://qualitycoding.org/3-laws-tdd/↩
6https://martinfowler.com/bliki/TestDrivenDevelopment.html↩
7https://blog.cleancoder.com/uncle-bob/2014/12/17/TheCyclesOfTDD.html↩
Fizz Buzz
1http://codingdojo.org/kata/FizzBuzz/↩
2https://jesuslc.com/2016/02/17/kata-fizzbuzz/)↩
3https://kata-log.rocks/fizz-buzz-kata)↩
4https://www.youtube.com/watch?v=BV86r2k6QI8)↩
5https://www.youtube.com/watch?v=JyRouDwzCoo)↩
6https://cloudnative.ly/which-order-to-write-your-tests-7ea2937761a1)↩
7https://www.linkedin.com/learning/unit-testing-and-test-driven-development-in-python/example-tdd-session-the-fizzbuzz-kata)↩
Evolución del comportamiento mediante tests
1http://blog.cleancoder.com/uncle-bob/2013/05/27/TheTransformationPriorityPremise.html↩
2https://codurance.com/2015/05/18/applying-transformation-priority-premise-to-roman-numerals-kata/↩
3http://blog.cleancoder.com/uncle-bob/2013/05/27/TheTransformationPriorityPremise.html↩
4http://blog.cleancoder.com/uncle-bob/2013/05/27/TheTransformationPriorityPremise.html↩
Prime Factors
1http://butunclebob.com/ArticleS.UncleBob.ThePrimeFactorsKata↩
2http://butunclebob.com/ArticleS.UncleBob.ThePrimeFactorsKata↩
3http://blog.cleancoder.com/uncle-bob/2013/05/27/TheTransformationPriorityPremise.html↩
NIF
1https://franiglesias.github.io/iniciacion-tdd/↩
Resolviendo la Kata NIF
1https://flaviocopes.com/golang-is-go-object-oriented/↩
Bowling game
1http://butunclebob.com/files/downloads/Bowling%20Game%20Kata.ppt↩
2https://ronjeffries.com/xprog/articles/acsbowling/↩
Greeting
1https://github.com/testdouble/contributing-tests/wiki/Greeting-Kata↩
Outside-in TDD
1https://www.codurance.com/publications/2017/10/23/outside-in-design↩
2https://www.youtube.com/watch?v=24vzFAvOzo0↩
Enfoques en TDD
1https://codurance.com/2015/05/12/does-tdd-lead-to-good-design/↩
2https://codurance.com/2017/10/23/outside-in-design/↩
3https://github.com/testdouble/contributing-tests/wiki/Detroit-school-TDD↩
4https://github.com/testdouble/contributing-tests/wiki/London-school-TDD↩
5https://en.wikipedia.org/wiki/Extreme_programming#Origins↩
6http://blog.testdouble.com/posts/2014-01-25-the-failures-of-intro-to-tdd/↩
7https://shorturl.at/aGwGw↩
8http://coding-is-like-cooking.info/2013/04/the-london-school-of-test-driven-development/↩
9http://coding-is-like-cooking.info/2013/04/outside-in-development-with-double-loop-tdd/↩
10http://coding-is-like-cooking.info/2013/05/tell-dont-ask-object-oriented-design/↩
Proyecto Todo-List
1https://alistair.cockburn.us/hexagonal-architecture/↩