
Table of Contents
- Introduction
- PiMetric
- The History of the Raspberry Pi
- Raspberry Pi Versions
- Raspberry Pi Peripherals
- Operating Systems
- Network connectivity
- How are we going to access PiMetric?
- PiMetric Installation
- Operation
- Configuration
- How to…
- Linux Concepts
- File Editing
- Linux Commands
- Directory Structure Cheat Sheet
- Static IP Address
Introduction
Welcome!
Hi there. Congratulations on getting your hands on this book. This indicates that you’re interested in learning about monitoring ‘stuff’ with a Raspberry Pi. You’ve come to the right place.
This is a journey of discovery for both of us. By experimenting with computers we will be learn about what is happening in the physical environment and on computer networks. This is not a new idea. But in going down this path we’re going to accomplish something. I write books to learn and document what I’ve done. The hope is that by sharing the journey others can learn something from my efforts :-).
Tricky? Maybe :-). But if you’re reading this, you’re on the way. I dare say that like other books I have written (or are currently writing) it will remain a work in progress. They are living documents, open to feedback, comment, expansion, change and improvement. Please feel free to provide your thoughts on ways that I can improve things. Your input would be much appreciated.
You will find that I employ more of a story telling approach to writing. Some explanations are longer and more flowery than might be to everyone’s liking, but there you go, that’s my way :-).
There’s a lot of information in the book. There’s ‘stuff’ that people with a reasonable understanding of computers will find excessive. Sorry about that. I have gathered a lot of the content from other books I’ve written to create this guide. As a result, it is as full of usable information as possible to help people who could be using the Pi and coding for the first time. Please bear in mind, this is the description of a single project. I could describe it in 20 pages but I have stretched it out into a lot more. If we need to recreate the project from scratch, this guide should leave nothing out. It will also link to other books (as books before this one have done). As the Raspberry Pi’s and OS’s improve, the descriptions will evolve.
I’m sure most authors try to be as accessible as possible. I’d like to do the same, but be warned… There’s a good chance that if you ask me a technical question I may not know the answer. So please be gentle with your emails :-).
Email: d3noobmail+pimetric@gmail.com
What are we trying to do?
Put simply, we are going to examine the wonder that is the Raspberry Pi computer and use it to accomplish something.
In this specific case we will be installing and configuring a monitoring system that will allow us to;
- Measure the resources of the Pi.
- Measure the resources of other computers
- Examine the performance of your network.
- Gather data from various data sources. Some of which you can build yourself!
Along the way you’ll get to write some simple code and see the information you’re measuring in a nice graphical form.
It’s possible that you could use PiMetric to know when something has failed and needs attention or when it looks like a failure is imminent.
Whare are we not going to be doing?
Well PiMetric isn’t written to exist in a hostile security environment. By that I mean, you and anyone else on the network has full access to the system. Better security controls can be implemented, but is currently out of scope.
This is not something that is intended for use to protect services that are really important. Maybe one day, but that’s a long way off. So fair warning. Regard this project as fun for a home enthusiast, but not suitable for monitoring nuclear reactors or hospitals.
Who is this book for?
You!
By getting hold of a copy of this book you have demonstrated a desire to learn and to challenge yourself. That’s the most important criteria you will want to have when trying something new. Your experience level will come second place to a desire to learn.
It may be useful to be comfortable using the Windows operating system (I’ll be using Windows 7 for the initial set-up of the devices). You should be aware of Linux as an alternative operating system, but you needn’t have tried it before. Before you learn anything new, it pretty much always appears indistinguishable from magic. but once you start having a play, the mystery falls away.
What will we need?
Well, you could just read the book and learn a bit. By itself that’s not a bad thing, but trust me when I say that actually just experimenting with physical computers is fun and rewarding.
The list below is flexible in most cases and will depend on how you want to measure the values.
- A Raspberry Pi (I’ve used a Raspberry Pi Model B+, 3B+ and Zero W)
- Probably a case for the Pi
- A MicroSD card
- A power supply for the Pi
- A keyboard and monitor that you can plug into the Pi (there are a few options here, read on for details)
- A remote computer (like your normal desktop PC that you can use to talk to connect to the Pi).
- An Internet connection for getting and updating the software.
As we work through the book we will be covering off the different options and you should get a good overview.
Why on earth did I write this rambling tome?
That’s a really good question. It came about while working on a project to measure the level in my water tank using an ultrasonic sensor. When I had it working I realised that it was a neat thing to do, but what I really needed was a way to automatically gather the data and tell me when there was a problem. This would have been easy enough to do for the project but I have quite a number of projects around the house and it made good sense to have a system that could check all of them. At the time of writing it is checking local CPU load, temperature, memory and hard drive space, light levels from a Pi connected to an analog sensor, weather data from my weather station, network connectivity to a range of devices in the house, ping time to Google’s 8.8.8.8 server, temperature in my pool’s filtration system and in the pantry. There’s a lot more that I’d like to measure and I expect that to develop over time. This book fits really well with the ones in the ‘Raspberry Pi Computing’ series, so I suppose it’s a ‘thing’ by now. Will this continue? Who knows, stay tuned…
Included is a bunch of information from my books on the Raspberry Pi, Linux and d3.js. I hope you find it useful.
Where can you get more information?
The Raspberry Pi as a concept has provided an extensible and practical framework for introducing people to the wonders of computing in the real world. At the same time there has been a boom of information available for people to use them. The following is a far from exhaustive list of sources, but from my own experience it represents a useful subset of knowledge.
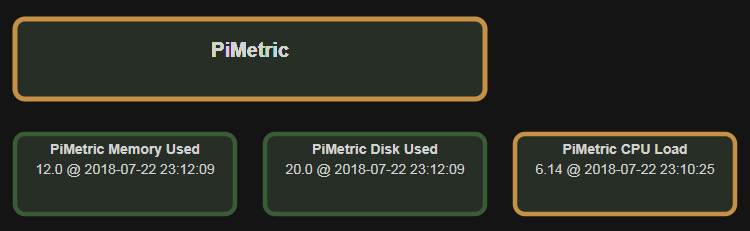
PiMetric

‘Pi’ - as in Raspberry Pi and ‘Metric’ as in Metrics. I was thinking about using the ‘Pi’ symbol in the name, but the angst that could come about by using a symbol scared me off.
What’s this all about then?
PiMetric is a project that runs on a Raspberry Pi that will check parameters (metrics) from computers or connected devices on your network.
It will do this on a regular schedule and show you a graph of the results.
You can also tell PiMetric what ‘normal’ values will look like for a metric. If the measured value falls outside that range it will show a colour that represents a level of severity (‘normal’, ‘caution’, ‘danger’ and ‘interesting’).
You can also represent the values in different ways. Grouped by what their state is or even in a combined graph to compare when changes occured.
How is this different from Nagios / Icinga / Prometheus?
There are plenty of different ways to look at monitoring in terms of what is required and the output. I’ve played with Nagios and Icinga in the past and they are great platforms. I felt that they were well suited to larger installations and had tremendous flexibility. With that flexibility came detail and complexity. PiMetric is designed to use a fairly light weight install and it comes with default metric monitoring that checks itself to see how much load is on its own system.
One thing I can say for sure is that PiMetric is young. There will be inevitable bugs and problems that will need to be ironed out. Frankly, I’m no expert on using GitHub to host a project, so I expect that the first time someone proposes a code change will be very exciting (perhaps no-one will :-)).
Overview
PiMetric is a system designed to allow the user to see what is going on in the world around us in a simple way. With it we can measure values, see when they exceed set limits and view their history from a web interface.
It was written to be as simple as possible to allow it to run on a Raspberry Pi but there is no reason why it couldn’t scale up for larger installations.
It uses the concept of ‘metrics’, where each ‘metric’ has a measurable value which is recorded and evaluated for correct operation.
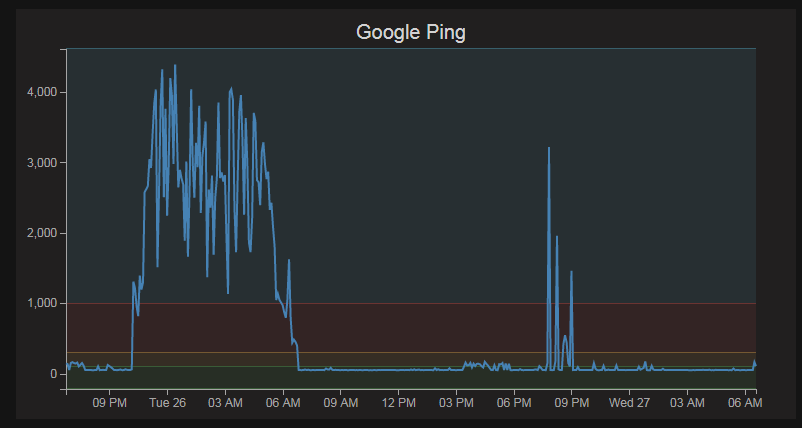
Examples of the type of metrics include;
- Data pulled from SNMP requests (hard drive space, memory, CPU load)
- Information scraped from a web page.
- Values parsed from a text file (logs)
- HTTP RESTful/API queries (via Nagios, bespoke systems, external providers)
- Database content
Installation
The installation instructions include a description of getting the Pi ready for use from scratch and describes how to start the mainly automated process.
Structure
The project is roughly divided into three parts. The measurement core, the management interface and the operating layer.
Measurement
The measurement core focuses on getting information and recording it.
It utilities separate processes to gather data in a programmatic way via Python based data gathering modules. These processes store measured values in a SQLite database. It contains a table for stored metric values and a table for the configuration.
The metrics can be arranged in a hierarchy. This is a tree structure to create greater context for evaluation.
The processes are individually scheduled and run via a cron job.
Management
The management is carried out using a simple CRUD (Create, Read, Update, Delete) system. This provides the ability create, edit, delete and view the metric information. While it is not intended to be a operational interface, it shares some features of one.
The management system includes logging, validation and sanitization. This maintains the integrity of the SQLite database and the structure of the metrics.
It is built from HTML, PHP and JavaScript, using a lightly modified Bootstrap front end and d3.js graphing components.
Operating
The operating layer provides an end user with the ability to explore the monitoring environment and the values that it has collected.
It is designed to display information in different ways depending on the role or end use of the data. For example, a ‘weather’ role might include information from a local weather station and external services. Whereas a ‘network’ function might include data rates, access availability, ping delays.
The way that it displays information is designed to allow an overview of what metrics are being measured in context with their roles. The user can also drill into the data and discover information that is useful to them.
It is also designed to respond to alerts when the metrics exceed their stated operating parameters. This provides a mechanism to manage faults, error conditions and to aid troubleshooting.
Like the management layer, this part of the project uses HTML, PHP and JavaScript. Bootstrap is at the front end and d3.js looks after the graphing components
The History of the Raspberry Pi
The story of the Raspberry Pi starts in 2006 at the University of Cambridge’s Computer Laboratory. Eben Upton, Rob Mullins, Jack Lang and Alan Mycroft became concerned at the decline in the volume and skills of students applying to study Computer Science. Typical student applicants did not have a history of hobby programming and tinkering with hardware. Instead they were starting with some web design experience, but little else.
They established that the way that children were interacting with computers had changed. There was more of a focus on working with Word and Excel and building web pages. Games consoles were replacing the traditional hobbyist computer platforms. The era when the Amiga, Apple II, ZX Spectrum and the ‘build your own’ approach was gone. In 2006, Eben and the team began to design and prototype a platform that was cheap, simple and booted into a programming environment. Most of all, the aim was to inspire the next generation of computer enthusiasts to recover the joy of experimenting with computers.
Between 2006 and 2008, they developed prototypes based on the Atmel ATmega644 microcontroller. By 2008, processors designed for mobile devices were becoming affordable and powerful. This allowed the boards to support an graphical environment. They believed this would make the board more attractive for children looking for a programming-oriented device.
Eben, Rob, Jack and Alan, then teamed up with Pete Lomas, and David Braben to form the Raspberry Pi Foundation. The Foundation’s goal was to offer two versions of the board, priced at US$25 and US$35.
50 alpha boards were manufactured in August 2011. These were identical in function to what would become the model B. Assembly of twenty-five model B Beta boards occurred in December 2011. These used the same component layout as the eventual production boards.

Interest in the project increased. They were demonstrated booting Linux, playing a 1080p movie trailer and running benchmarking programs. During the first week of 2012, the first 10 boards were put up for auction on eBay. One was bought anonymously and donated to the museum at The Centre for Computing History in Suffolk, England. While the ten boards together raised over 16,000 Pounds (about $25,000 USD) the last to be auctioned (serial number No. 01) raised 3,500 Pounds by itself.
The Raspberry Pi Model B entered mass production with licensed manufacturing deals through element 14/Premier Farnell and RS Electronics. They started accepting orders for the model B on the 29th of February 2012. It was quickly apparent that they had identified a need in the marketplace. Servers struggled to cope with the load placed by watchers repeatedly refreshing their browsers. The official Raspberry Pi Twitter account reported that Premier Farnell sold out within few minutes of the initial launch. RS Components took over 100,000 pre orders on the first day of sales.
Within two years they had sold over two million units.
The the lower cost model A went on sale for $25 on 4 February 2013. By that stage the Raspberry Pi was already a hit. Manufacturing of the model B hit 4000 units per day and the amount of on-board ram increased to 512MB.
The official Raspberry Pi blog reported that the three millionth Pi shipped in early May 2014. In July of that year they announced the Raspberry Pi Model B+, “the final evolution of the original Raspberry Pi. For the same price as the original Raspberry Pi model B, but incorporating numerous small improvements”. In November of the same year the even lower cost (US$20) A+ was announced. Like the A, it would have no Ethernet port, and just one USB port. But, like the B+, it would have lower power requirements, a micro-SD-card slot and 40-pin HAT compatible GPIO.
On 2 February 2015 the official Raspberry Pi blog announced that the Raspberry Pi 2 was available. It had the same form factor and connector layout as the Model B+. It had a 900 MHz quad-core ARMv7 Cortex-A7 CPU, twice the memory (for a total of 1 GB) and complete compatibility with the original generation of Raspberry Pis.

Following a meeting with Eric Schmidt (of Google fame) in 2013, Eben embarked on the design of a new form factor for the Pi. On the 26th of November 2015 the Pi Zero was released. The Pi Zero is a significantly smaller version of a Pi with similar functionality but with a retail cost of $5. On release it sold out (20,000 units) World wide in 24 hours and a free copy was affixed to the cover of the MagPi magazine.
The Raspberry Pi 3 was released in February 2016. The most notable change being the inclusion of on-board WiFi and Bluetooth.
In February 2017 the Raspberry Pi Zero W was announced. This device had the same small form factor of the Pi Zero, but included the WiFi and Bluetooth functionality of the Raspberry Pi 3.
On Pi day (the 14th of March (Get it? 3-14?)) in 2018 the Raspberry Pi 3+ was announced. It included dual band WiFi, upgraded Bluetooth, Gigabit Ethernet and support for a future PoE card. The Ethernet speed was actually 300Mpbs since it still needs to operate on a USB2 bus. By this stage there had been over 9 million Raspberry Pi 3’s sold and 19 million Pi’s in total.
It would be easy to consider the measurement of the success of the Raspberry Pi in the number of computer boards sold. Yet, this would most likely not be the opinion of those visionaries who began the journey to develop the boards. Their stated aim was to re-invigorate the desire of young people to experiment with computers and to have fun doing it. We can thus measure their success by the many projects, blogs and updated school curriculum’s that their efforts have produced.
Raspberry Pi Versions
In the words of the totally awesome Raspberry Pi foundation;
The Raspberry Pi is a low cost, credit-card sized computer that plugs into a computer monitor or TV, and uses a standard keyboard and mouse. It’s capable of doing everything you’d expect a desktop computer to do, from browsing the internet and playing high-definition video, to making spreadsheets, word-processing, playing games and learning how to program in languages like Scratch and Python.
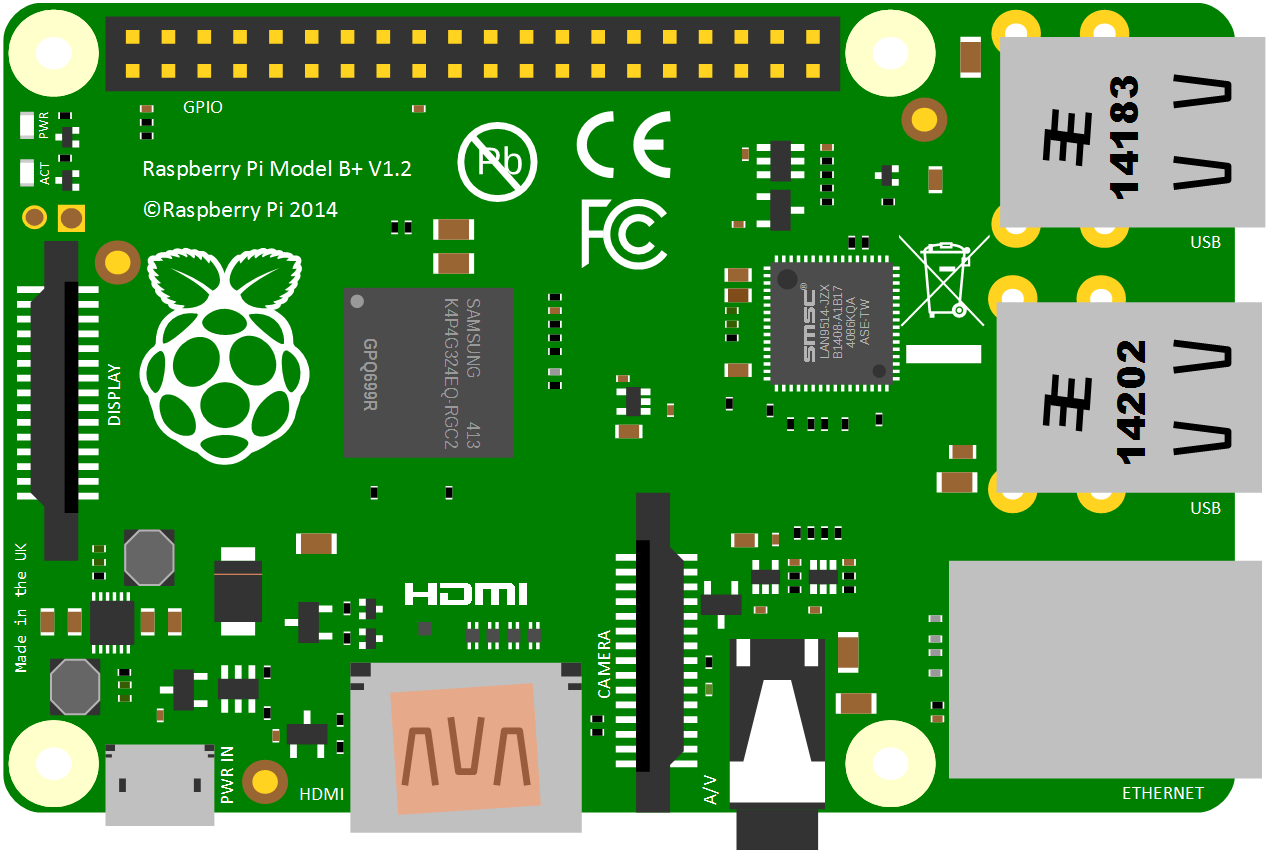
There are (at time of writing) eight different models on the market. The A, B, A+, B+, ‘model B 2’, ‘model B 3’, ‘model B 3+’ (which I’m just going to call the B2, B3 and B3+ respectively), the Zero and Zero W. A lot of projects will typically use either the the B2, B3 or the B3+ for no reason other than they offer a good range of USB ports (4), 1024 MB of RAM, an HMDI video connection and an Ethernet connection. For all intents and purposes either the B2, B3 or B3+ can be used interchangeably for the projects depending on connectivity requirements as the B3 and B3+ has WiFi and Bluetooth built in. For size limited situations or where lower power is an advantage, the Zero or Zero W is useful, although there is a need to cope with reduced connectivity options (a single micro USB connection) although the Zero W has WiFi and Bluetooth built in. Always aim to use the latest version of the Raspbian operating system (or at least one released on or after the 14th of March 2018). For best results browse the ‘Downloads’ page of raspberrypi.org.
Raspberry Pi B+, B2, B3 and B3+

The model B+, B2, B3 and B3+ all share the same form factor and have been a consistent standard for the layout of connectors since the release of the B+ in July 2014. They measure 85 x 56 x 17mm, weighs 45g and are powered by Broadcom chipsets of varying speeds, numbers of cores and architectures.
USB Ports
They include 4 x USB Ports (with a maximum output of 1.2A)

Video Out
Integrated Videocore 4 graphics GPU capable of playing full 1080p HD video via a HDMI video output connector. HDMI standards rev 1.3 & 1.4 are supported with 14 HDMI resolutions from 640×350 to 1920×1200 plus various PAL and NTSC standards.

Ethernet Network Connection
There is an integrated Ethernet Port for network access. On the B2 and B3 the connection speed is fast ethernet (10/100 bps). The B3+ introduced a 300bps connection speed.

USB Power Input Jack
The boards include a 5V 2A Micro USB Power Input Jack.

MicroSD Flash Memory Card Slot
There is a microSD card socket on the ‘underside ‘of the board. On the Model B2 this is a ‘push-push’ socket. On the B3 and later this is a simple friction fit.

Stereo and Composite Video Output
The B+, B2, B3 and B3+ includes a 4-pole (TRRS) type connector that can provide stereo sound if you plug in a standard headphone jack and composite video output with stereo audio if you use a TRRS adapter.

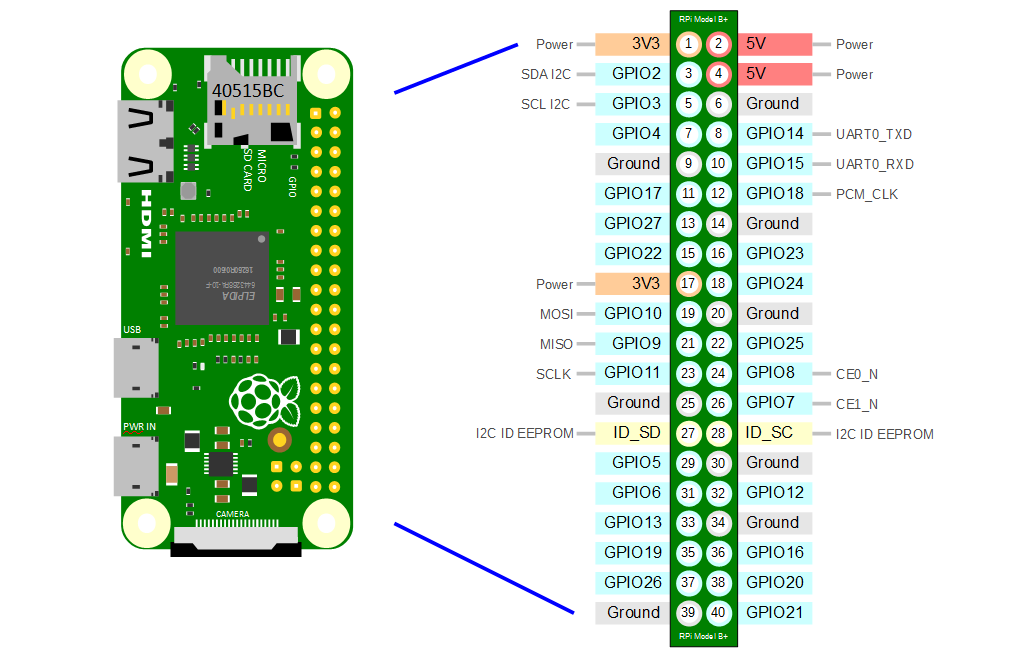
40 Pin Header
The Raspberry Pi B+, B2, B3 and B3+ include a 40-pin, 2.54mm header expansion slot (Which allows for peripheral connection and expansion boards).

Raspberry Pi Zero

The Raspberry Pi Zero has been designed to scale to as small a size as practical while retaining the standard 40 pin GPIO header arrangement. It is half the size of the Model A+ with twice as much memory (512MB) and a CPU running at a higher clock speed (1 GHz). However, it’s size remains it’s main feature. It is 65 x 30 x 5mm and weighs 9g. Like the Models A, A+, B and B+ it is powered by a Broadcom BCM2835 ARM11.
To make the Zero as small as possible there have been some significant connectivity changes. There is a mini-HDMI connector with a single Micro-USB connector for peripherals and another dedicated to applying power. The other striking difference is that while the GPIO ports remain and are configured the same, the header pins themselves have not been soldered onto the board. These connector choices mean that the 5mm thickness provides ample opportunities for applications where thickness is an issue.
In May of 2016, a new version of the Pi Zero (ver 1.3) was announced that includes a camera port on one of the narrower edges. While there will be a number of the original version in circulation, the 1.3 version will be the default version for resellers and customers who don’t need or want a wireless connection.
At the end of February 2017 the Pi Zero W (‘W’ for Wireless) was released that added WiFi and Bluetooth connectivity. The Zero W model was released with a price tag of $10 (USD)

USB Port
It includes 1 x Micro-USB Port

Video Out
Integrated Videocore 4 graphics GPU capable of playing full 1080p HD video via a mini-HDMI video output connector. HDMI resolutions up to 1080p at 60fps are supported.

USB Power Input Jack
The board includes a 5V Micro-USB Power Input Jack.

MicroSD Flash Memory Card Slot
The Pi Zero includes a push-push microSD card socket. This is on the ‘topside ‘of the board unlike most of the other more standard models which locate the memory card socket on the ‘underside’.

MIPI Camera Interface
Versions of the Pi Zero from 1.3 onwards includes a fine-pitch FPC connector for connecting a camera. This is a different size connector to that used on the A and B, 2, 3 models. so just be aware that you will want a specific cable to ensure a satisfactory fit.

Stereo and Composite Video Output
The Zero does not include a connector for composite video out, but it does have two solder points where composite output could be soldered. There is no audio output available from the Zero other than via the mini HDMI connector, so this is not really a board designed for easy composite or audio output.
40 Pin Header
The Raspberry Pi Zero includes a 40-pin, 2.54mm header expansion slot (Which allows for peripheral connection and expansion boards).
Raspberry Pi Peripherals
To make a start using the Raspberry Pi we will need to have some additional hardware to allow us to configure it.
SD Card
Traditionally the Raspberry Pi needs to store the Operating System and working files on a MicroSD card (actually a MicroSD card all models except the older A or B models which use a full size SD card). There is the ability to boot from a mass storage device or the network, but it is slightly ‘non-trivial’, so we won’t cover it.

The MicroSD card receptacle is on the rear of the board. On the Model B2 it is a ‘push-push’ type which means that you push the card in to insert it and then to remove it, give it a small push and it will spring out. The other models employ a push-pull fit.
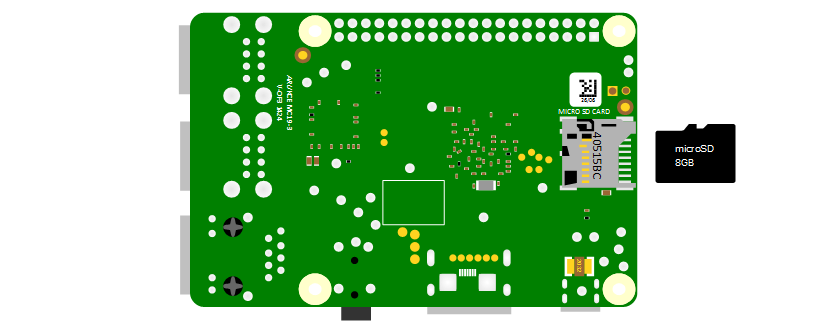
This is the equivalent of a hard drive for a regular computer, but we’re going for a minimal effect. We will want to use a minimum of an 8GB card (smaller is possible, but 8 is recommended). Also try to select a higher speed card if possible (class 10 or similar) as this will speed things up a bit.
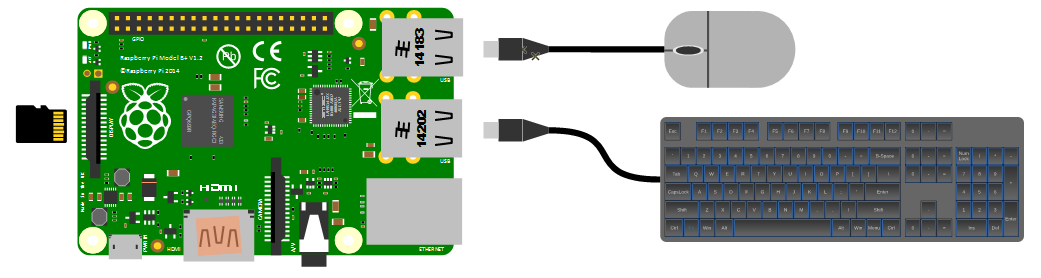
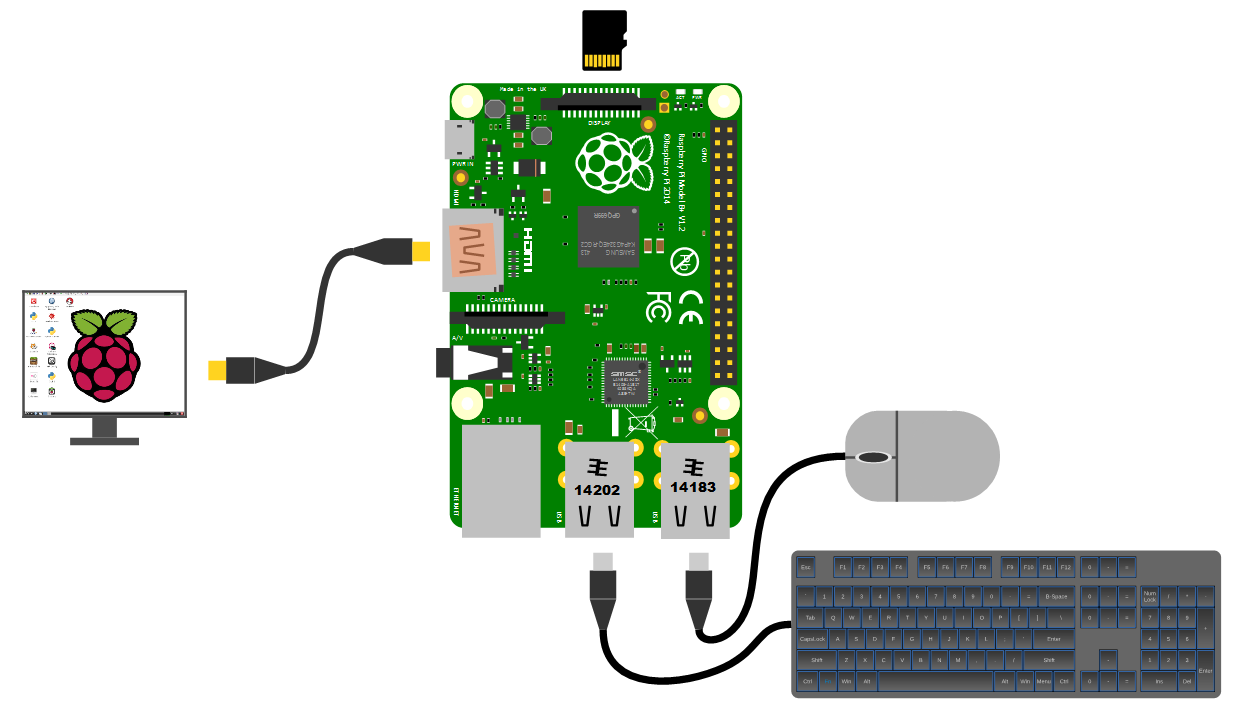
Keyboard / Mouse
While we will be making the effort to access our system via a remote computer, you may want a keyboard and a mouse for the initial set-up. Because the B+, B2, B3 and B3+ models of the Pi have 4 x USB ports, there is plenty of space for us to connect wired USB devices.
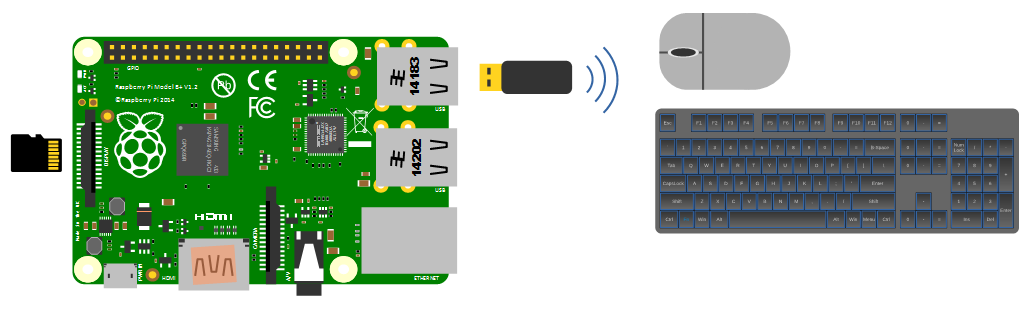
An external wireless combination would most likely be recognised without any problem and would only take up a single USB port, but if we build towards a remote capacity for using the Pi (using it headless, without a keyboard / mouse / display), the nicety of a wireless connection is not strictly required.
Video
The Raspberry Pi comes with an HDMI port ready to go which means that any monitor or TV with an HDMI connection should be able to connect easily. The Pi Zero models have a mini HDMI port.
Because this is kind of a hobby thing you might want to consider utilising an older computer monitor with a DVI or 15 pin ‘D’ connector. If you want to go this way you will need an adapter to convert the connection.

Network
The B+, B2, B3 and B3+ models of the Raspberry Pi have a standard RJ45 network connector on the board ready to go. In a domestic installation this is most likely easiest to connect into a home ADSL modem or router.
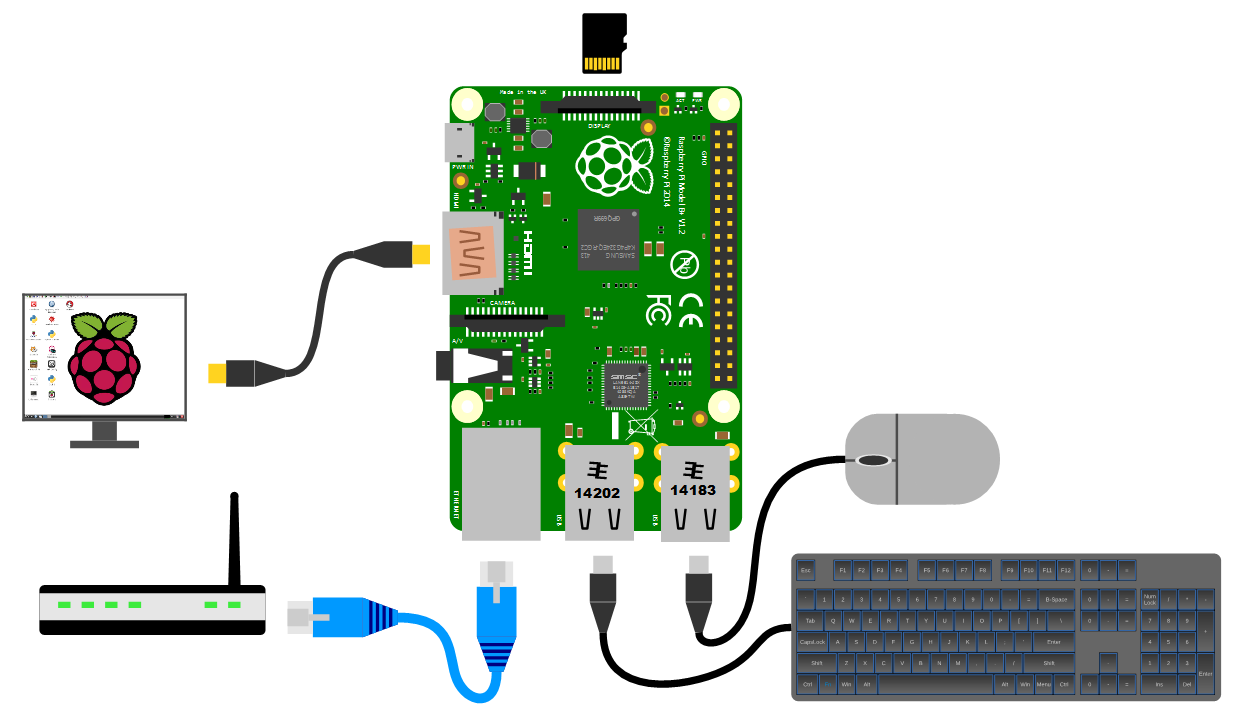
The B3, B3+ and Zero W also have wireless built in.
The ‘hard-wired’ connection is great simple way to get started, but we will work through using a wireless solution later in the book.
Power supply
The Pi can be powered up in a few ways. The simplest is to use the micro USB port to connect from a standard USB charging cable. You probably have a few around the house already for phones or tablets.
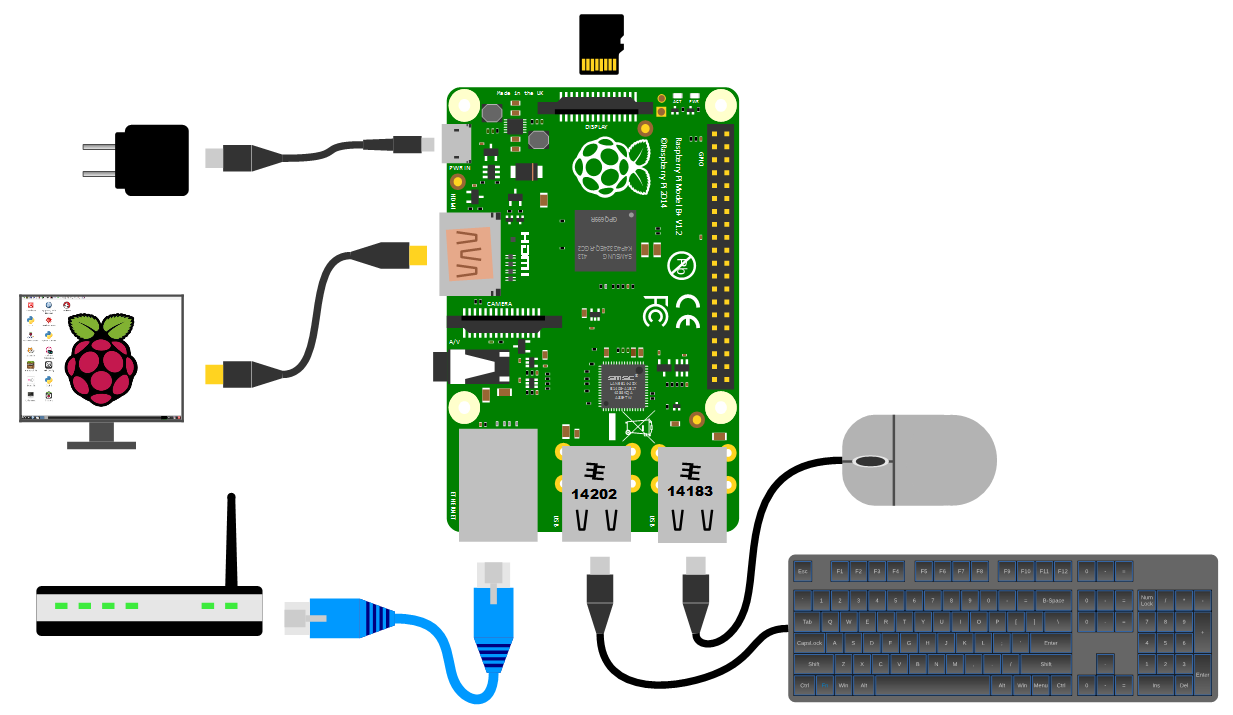
However, it’s worth paying attention to the amount of current that our power supply can deliver. The A+, B+ and Zero models will function adequately with a 700mA supply, but the B2, B3 and B3+ models will draw more current and if we want to use multiple wireless devices or supplying sensors that demand increased power, we will need to consider a supply that is capable of an output up to 2.5A.
Cases
We should get ourselves a simple case to keep the Pi reasonably secure. There are a wide range of options to select from. These range from cheap but effective to more costly than the Pi itself (not hard) and looking fancy.
You could use a simple plastic case that can be brought for a few dollars;

For a very practical design and a warm glow from knowing that you’re supporting a worthy cause, you could go no further than the official Raspberry Pi case that includes removable side-plates and loads of different types of access. All for the paltry sum of about $9.

Operating Systems
An operating system is software that manages computer hardware and software resources for computer applications. For example Microsoft Windows could be the operating system that will allow the browser application Firefox to run on our desktop computer.
Variations on the Linux operating system are the most popular on our Raspberry Pi. Often they are designed to work in different ways depending on the function of the computer.
Linux is a computer operating system that is can be distributed as free and open-source software. The defining component of Linux is the Linux kernel, an operating system kernel first released on 5 October 1991 by Linus Torvalds.
Linux was originally developed as a free operating system for Intel x86-based personal computers. It has since been made available to a huge range of computer hardware platforms and is one of the most popular operating systems on servers, mainframe computers and supercomputers. Linux also runs on embedded systems, which are devices whose operating system is typically built into the firmware and is highly tailored to the system; this includes mobile phones, tablet computers, network routers, automation controls, televisions and video game consoles. Android, the most widely used operating system for tablets and smart-phones, is built on top of the Linux kernel. In our case we will be using a version of Linux that is assembled to run on the ARM CPU architecture used in the Raspberry Pi.
The development of Linux is one of the most prominent examples of free and open-source software collaboration. Typically, Linux is packaged in a form known as a Linux ‘distribution’, for both desktop and server use. Popular mainstream Linux distributions include Debian, Ubuntu and the commercial Red Hat Enterprise Linux. Linux distributions include the Linux kernel, supporting utilities and libraries and usually a large amount of application software to carry out the distribution’s intended use.
A distribution intended to run as a server may omit all graphical desktop environments from the standard install, and instead include other software to set up and operate a solution stack such as LAMP (Linux, Apache, MySQL and PHP). Because Linux is freely re-distributable, anyone may create a distribution for any intended use.
Welcome to Raspbian
The Raspbian Linux distribution is based on Debian Linux. At the time of writing there have been three different editions published. ‘Wheezy’, ‘Jessie’ and ‘Stretch’. Debian is a widely used Linux distribution that allows Raspbian users to leverage a huge quantity of community based experience in using and configuring software. The Wheezy edition is the earlier of the three and was the stock edition from the inception of the Raspberry Pi till the end of 2015. From that point Jessie was the default distribution until mid 2017 when Stretch took over.
Downloading
The best place to source the latest version of the Raspbian Operating System is to go to the raspberrypi.org page; http://www.raspberrypi.org/downloads/. We will download the ‘Lite’ version (which doesn’t use a desktop GUI). If you’ve never used a command line environment, then good news! You’re about to enter the World of ‘real’ computer users :-).

You can download via bit torrent or directly as a zip file, but whatever the method you should eventually be left with an ‘img’ file for Raspbian.
To ensure that the projects we work on can be used with any of the Pis we need to make sure that the version of Raspbian we download is from 2018-03-04 or later. Earlier downloads will not support the more modern CPU of the B3+.

We should always try to download our image files from the authoritative source!
Writing the Operating System image to the SD Card
Once we have an image file we need to get it onto our SD card.
We will work through an example using Windows 7 but the process should be very similar for other operating systems as we will be using the excellent open source software Etcher which is available for Windows, Linux and macOS.
Download and install Etcher and start it up.
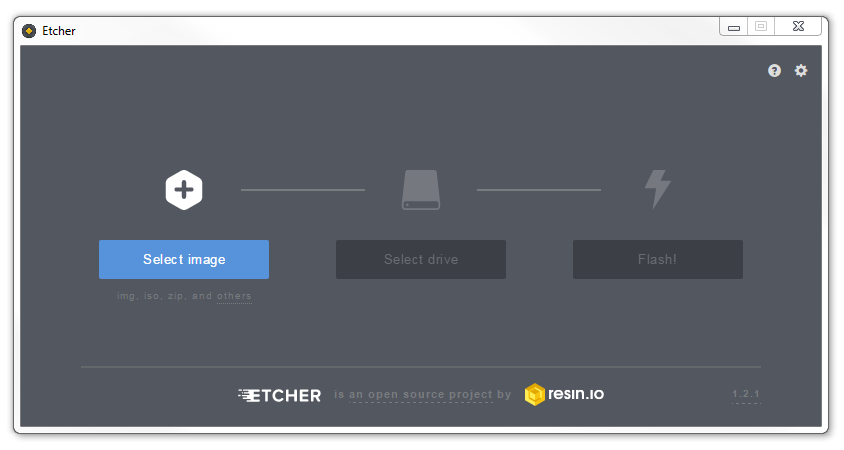
Select the img file that you want to install.
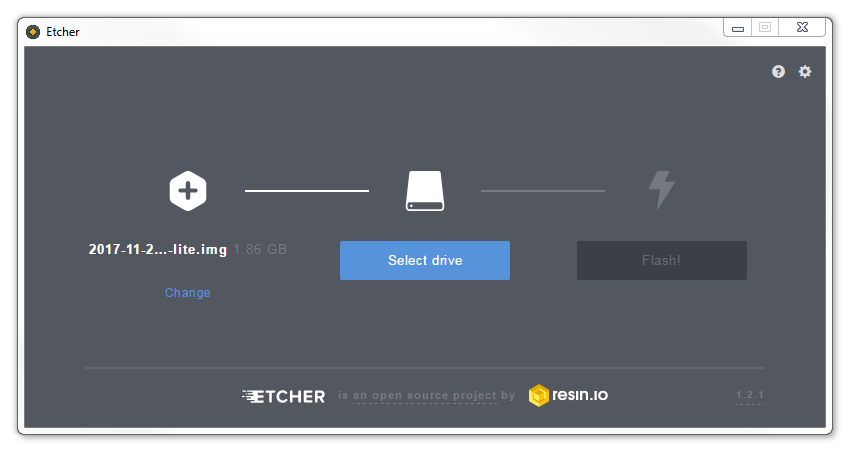
You will need an SD card reader capable of accepting your MicroSD card (you may require an adapter or have a reader built into your desktop or laptop). Place the card in the reader and you should see Etcher automatically select it for writing (Etcher is very good at presenting options for installing that are only SD cards).
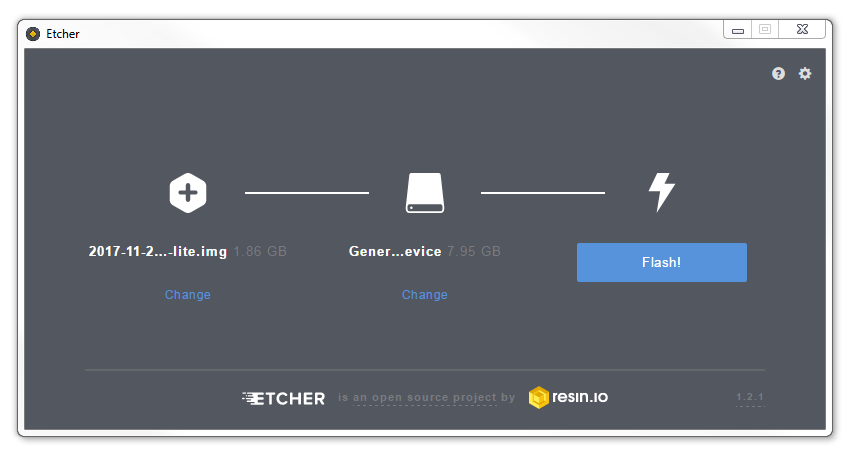
Then click on ‘Flash!’ to burn the card.
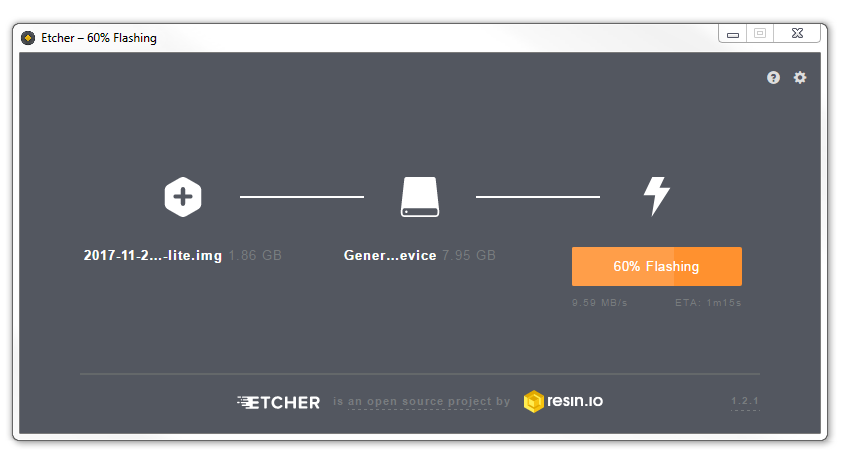
Etcher will write the image to the SD card. The time taken can vary a little, but it should only take about 3-4 minutes with a class 10 SD card.
Once written, Etcher will validate the write process (this can be disabled if desired).
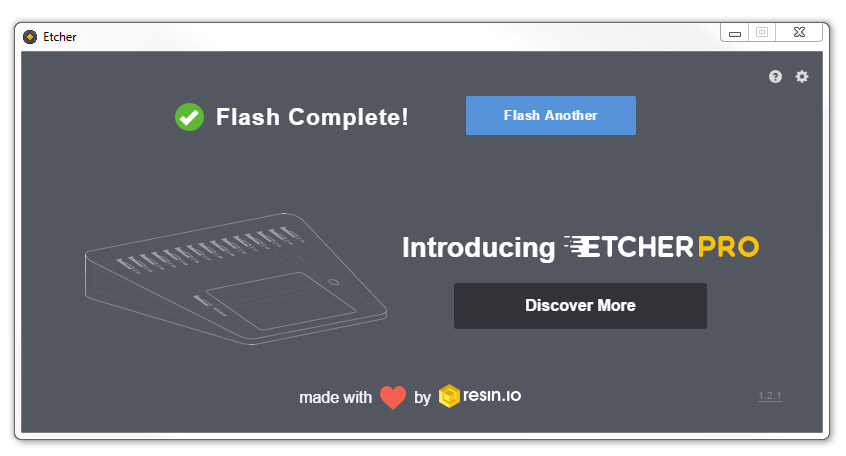
When the process is finished Etcher will automatically unmount the SD card. Remove the card from the desktop computer.
Enabling Secure Shell Access
One of the awesome things when learning to use a Raspberry Pi comes when you begin to access it remotely from another computer. This is a bit of an ‘Ah Ha!’ moment for some people as they begin to appreciate just how networks and the Internet is built. We are going to enable and use remote access via what is called ‘SSH’. We’ll start using it later in the book, but for now we can take the opportunity to enable it for later use. We do this by creating a file called ‘ssh’ on our freshly written SD card. Then, when the Pi starts up for the first time it ‘sees’ the file and automatically knows to enable SSH.
SSH used to be enabled by default, but doing so presents a potential security concern, so it has been disabled by default as of the end of 2016. In our case it’s a feature that we want to use.
Re-insert the SD card into the desktop computer. When it recognises the card again, open it and right-click in the folder to create a new file. This can be a simple txt file so long as the file prefix is ‘ssh’. It doesn’t need to have anything in it, there just needs to be a file there.
Network connectivity
Now you have a decision to make.
PiMetric is a system designed to utilise a network to connect to the things that it measures. To do this we need to use a hard wired connection on one of the larger models (A, B, A+, B+, 2B, 3B or 3B+) or a WiFi connection on the 3, 3B+ or Zero W.
The installation of PiMetric is agnostic of the connection method, but we need to connect somehow.
The other thing to consider is whether or not you are using the Pi connected to a keyboard and monitor or ‘headless’ (without a keyboard and monitor). With a keyboard and monitor is slightly easier, but I strongly recommend that you try the exercise headless, because it is a fantastic way of demonstrating the real power of networked computers if you haven’t done that sort of thing before.
I’ll only describe the keyboard and monitor connected method for the wired connection since connecting these to the Pi Zero W is slightly more tricky (just a little).
Whichever of these methods you have ready to go, the assumption is made that your network employs a thing called DHCP (Dynamic Host Configuration Protocol). This sounds like kind of a big deal, but in fact it is a very common service to be running on even a small home network. The most likely place to find a DHCP service running in a normal domestic situation would be an an ADSL modem or router. You can start with the assumption that it already exists :-).
The other assumption we should make is that your network is connected to the Internet.
How are we going to access PiMetric?
Host name or IP address?
Here’s the point where we decide what we are going to call our server. The default name for the server that comes with Raspbian is ‘raspberrypi’. That means that we can access it later from a web browser at raspberrypi.local. However, I’m going to try to convince you that the name ‘pimetric’ might be a better choice (which would mean accessing the server at pimetric.local). Let’s work on the assumption that that’s what’s going to happen and if you change your mind later there is an option to do so during the installation.
Alternatively, you could choose to use the IP address of the Pi on the network. Normally I would be a big fan of this, but I’m trying something different with this project and part of the plan is to avoid setting a static IP address. So, if you’re keen to work through the options of setting a static IP address, feel free to read all about how to do that in the static IP annex.
Setting up a client for remote access
Because I want to avoid duplicating the explanation of how to install software for connecting to our Pi remotely, I’ve decided to put it here.
This will mean that we don’t need to have the keyboard and video connected to the Raspberry Pi and we can physically place it somewhere else and still work on it without problem. This process is called ‘remotely accessing’ our computer.
To do this we need to install an application on our windows desktop which will act as a ‘client’ in the process and have software on our Raspberry Pi to act as the ‘server’ (it’s called a client-server model). There are a couple of different ways that we can accomplish this task.
Remote access via SSH
Secure Shell (SSH) is a network protocol that allows secure data communication, remote command-line login, remote command execution, and other secure network services between two networked computers. It connects, via a secure channel over an insecure network, a server and a client running SSH server and SSH client programs, respectively (there’s the client-server model again).
In our case the SSH program on the server (our Pi) is running sshd and on the Windows machine we will use a program called ‘PuTTY’.
Setting up the Server (Raspberry Pi)
Already done! Remember when I told you to create a file on the SD card called ‘ssh’? Well, when we boot our Pi for the first time it’s going to enable ssh access for us and we can set up a connection.
Setting up the Client (Windows)
The client software we will use is called ‘Putty’. It is open source and available for download from here.
On the download page there are a range of options available for use. The best option for us is most likely under the ‘For Windows on Intel x86’ heading and we should just download the ‘putty.exe’ program.
Save the file somewhere logical as it is a stand-alone program that will run when you double click on it (you can make life easier by placing a short-cut on the desktop).
Once we have the file saved, run the program by double clicking on it and it will start without problem.
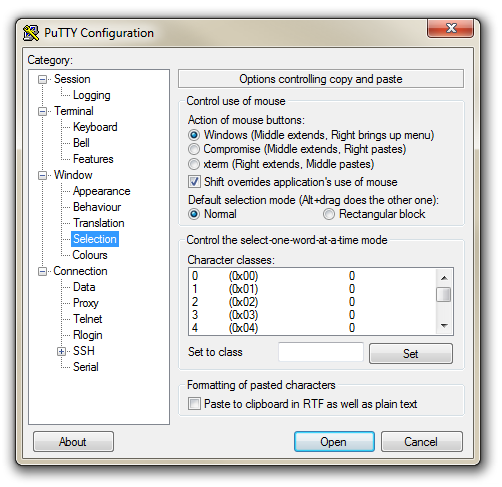
The first thing we will set-up for our connection is the way that the program recognises how the mouse works. In the ‘Window’ Category on the left of the PuTTY Configuration box, click on the ‘Selection’ option. On this page we want to change the ‘Action of mouse’ option from the default of ‘Compromise (Middle extends, Right paste)’ to ‘Windows (Middle extends, Right brings up menu)’. This keeps the standard Windows mouse actions the same when you use PuTTY.
Now select the ‘Session’ Category on the left hand menu. Here we want to enter our static IP address (or our host name) that we set up earlier (10.1.1.160 in the example, or pimetric.local if using the default host name) and because we would like to access this connection on a frequent basis we can enter a name for it as a saved session (In the screen-shot below it is imaginatively called ‘Raspberry Pi’). Then click on ‘Save’.
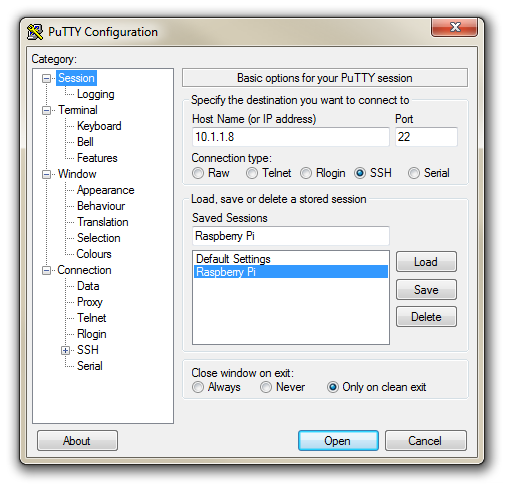
Now we can select our raspberry Pi Session (per the screen-shot above) and click on the ‘Open’ button.
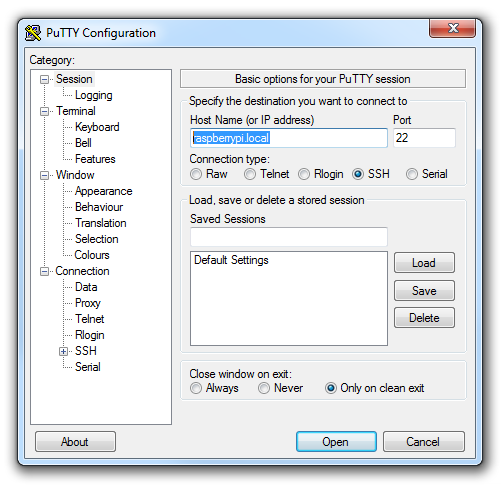
The first thing you will be greeted with is a window asking if you trust the host that you’re trying to connect to.
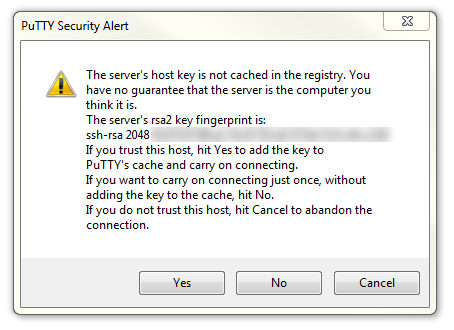
In this case it is a pretty safe bet to click on the ‘Yes’ button to confirm that we know and trust the connection.
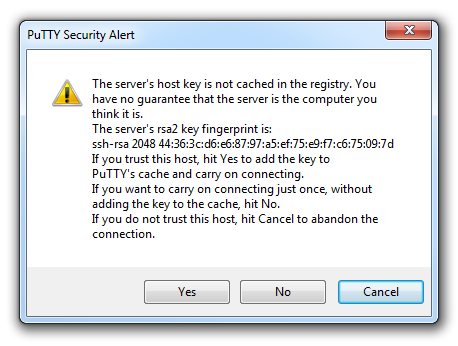
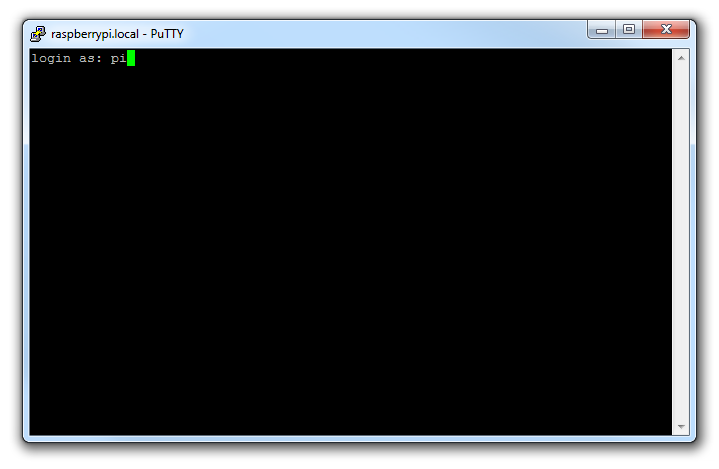
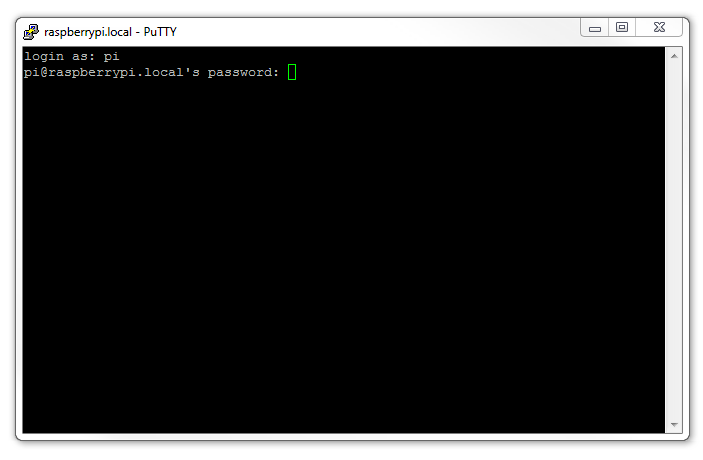
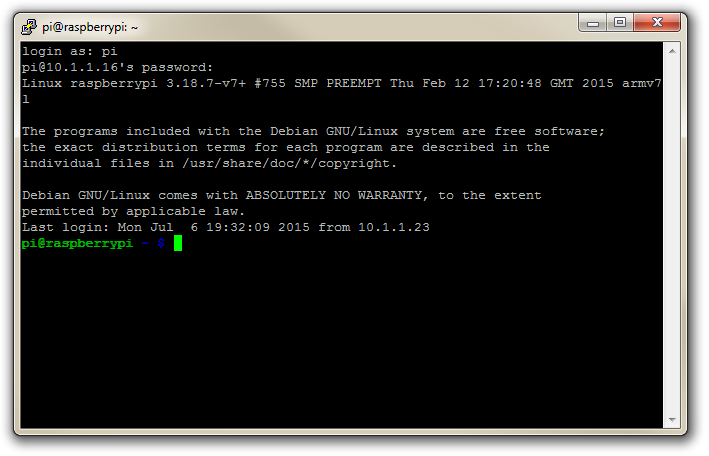
Once this is done, a new terminal window will be shown with a prompt to login as: . Here we can enter our user name (‘pi’) and then our password (if it’s still the default, the password is ‘raspberry’).
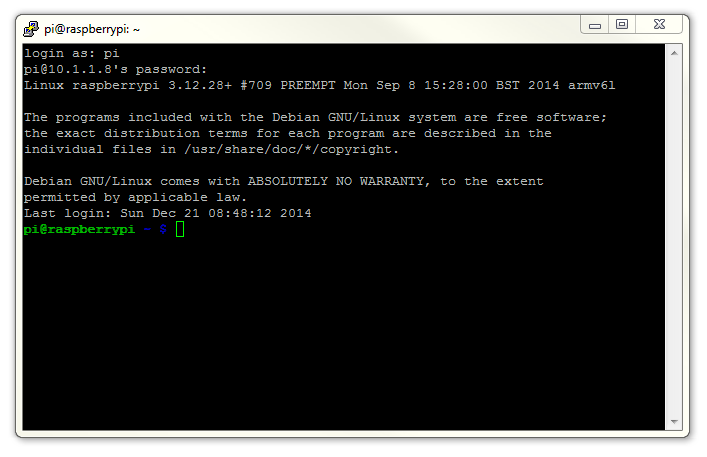
There you have it. A command line connection via SSH. Well done.
If this is the first time that you’ve done something like this it can be a very liberating feeling.
WinSCP
To make the process of transferring files from Windows easier I would recommend looking to the program WinSCP.
This provides a very intuitive way to copy files between your desktop and the Pi.
Download and install the program. Once installed, click on the desktop icon.
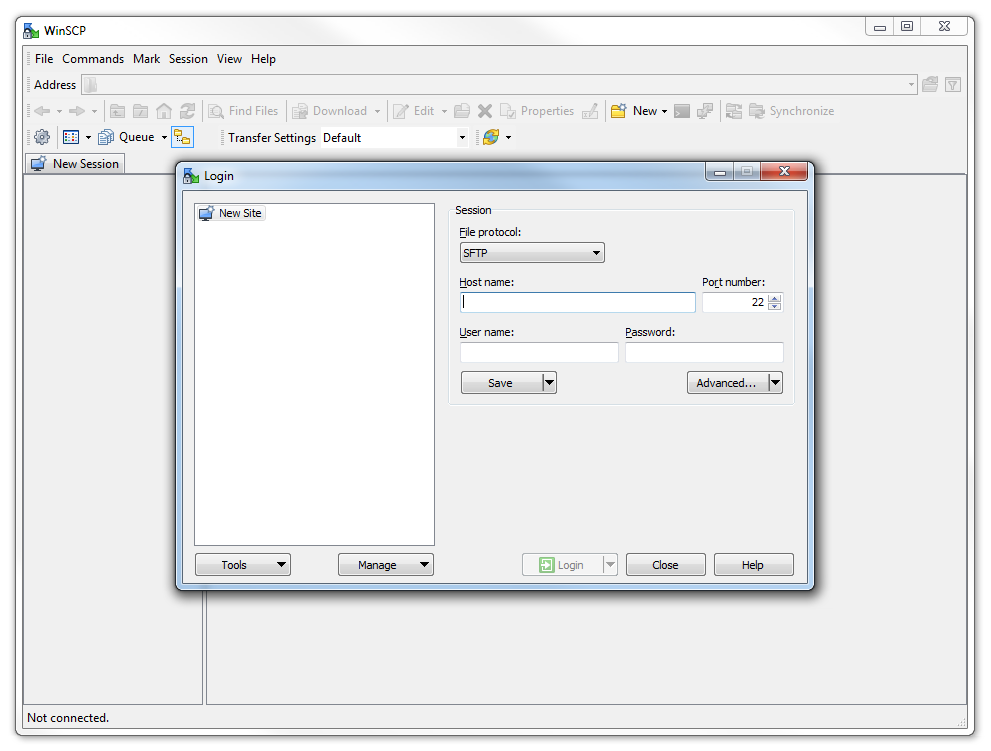
The program opens with default login page. Enter the ‘Host name’ field with the IP address of the Pi or its host name. Also put in the username and password of the Pi.
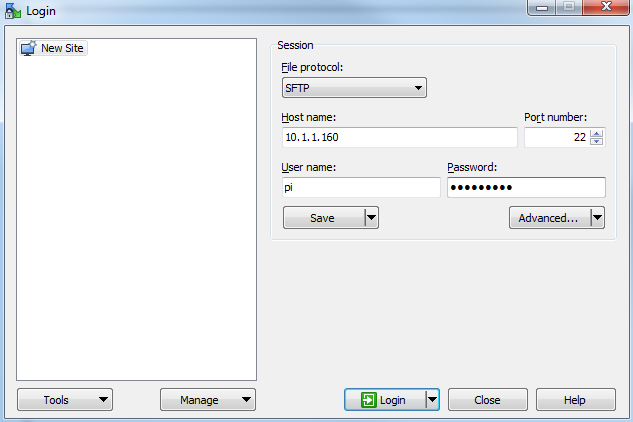
Click on ‘Save’ to save the login details for ease of future access.
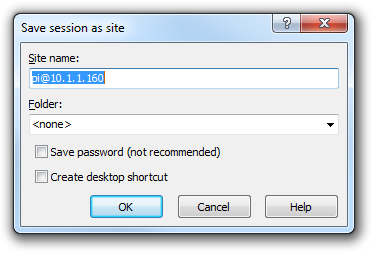
Enter the ‘Site name’ as a name of the Pi or leave it as the default, with the user and IP address. Check the ‘Save password’ for a convenient but insecure way to avoid typing in the username and password in the future. Then press OK
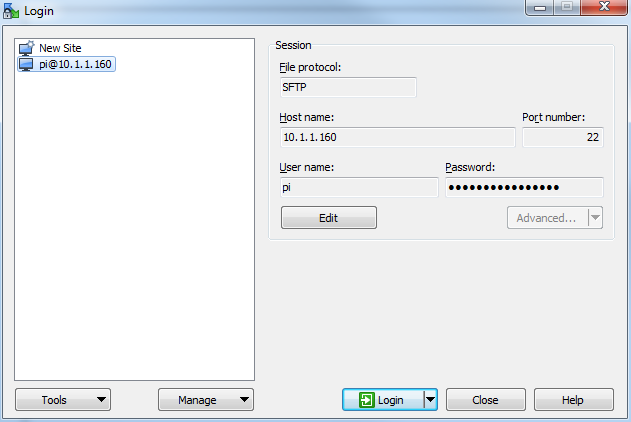
The saved login details now appear on the left hand pane. Click on ‘Login’ to log in to the Pi.
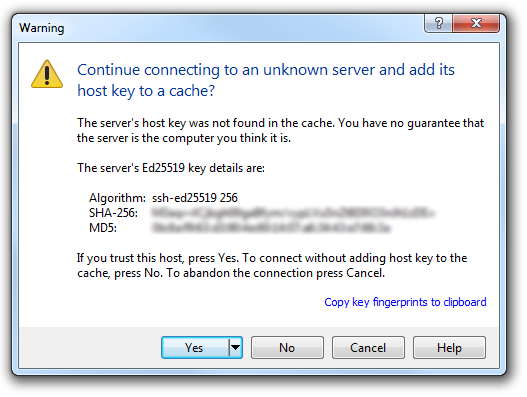
We will receive a warning about connecting to an unknown server for the first time. Assuming that we are comfortable doing this (i.e. that we know that we are connecting the Pi correctly) we can click on ‘Yes’.
There is a possibility that it might fail on its first attempt, but tell it to reconnect if it does and we should be in!
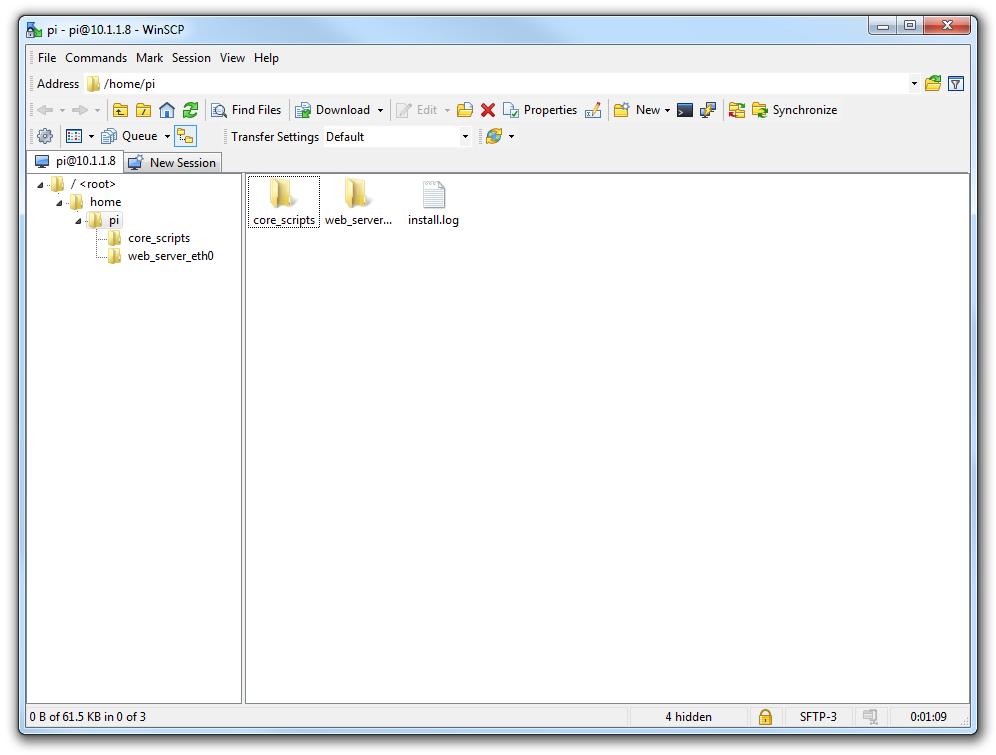
Here we can see a familiar tree structure for file management and we have the ability to copy files via dragging and dropping them into place.
Assuming that we already have PuTTY installed we should be able to click on the ‘Open Session in PuTTY’ icon and we will get access to the command line.

Wired Connection
For the wired connection your Raspberry Pi is connected to your local network via a cable plugged into the RJ45 connector on the board.
This method has the advantage of being slightly easier to manage the network connection, but it has the disadvantage of being dependent on locating the Pi within reach of a network cable.
Connected with a keyboard and monitor (cheating)
For this installation you have your SD card prepared as per earlier, with the Raspbian Lite Operating installed and SSH enabled.
As well as that you have the Pi plugged into your keyboard and monitor (you should really try it headless).
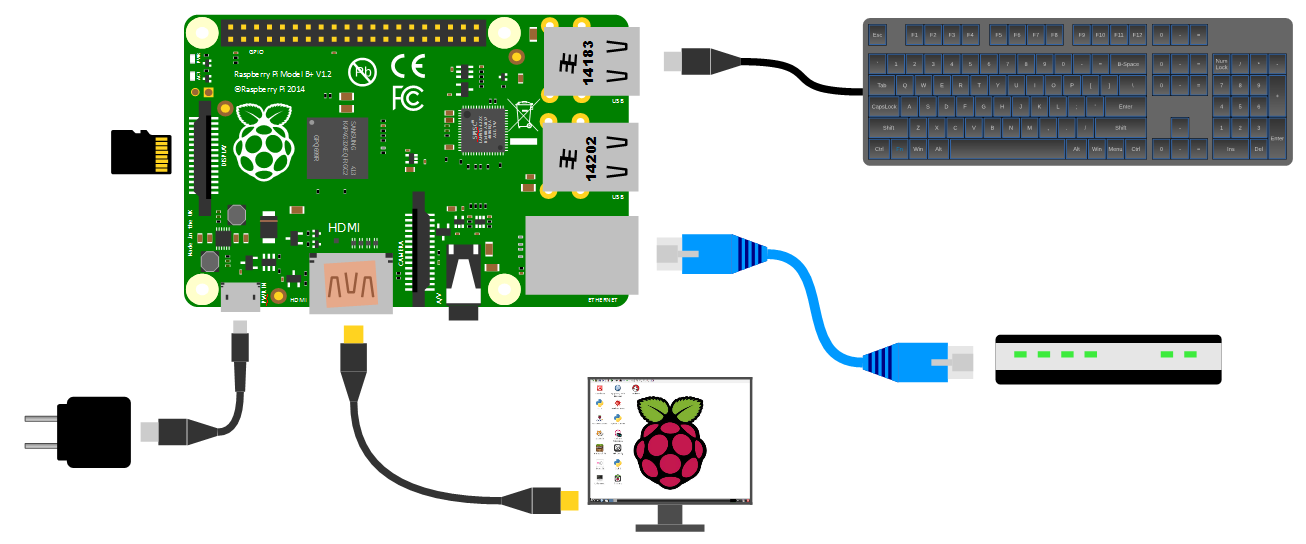
Insert the micro SD card into the slot on the Raspberry Pi and turn on the power.
You will see a range of information scrolling up the screen, the Raspberry Pi will reboot (as it automagically expands the size available to it on your SD card) before eventually being presented with a login prompt.
Once the reboot is complete you will be presented with the console prompt to log on that looks a bit like this;
Here you can enter the username that we will use for the install an it’s password. The default username and password is:
- Username: pi
- Password: raspberry
Enter the username and then the password.
Congratulations, you have a working Raspberry Pi, you have logged in and you are now ready to start the installation of PiMetric!
Headless (kudos)
For this installation you have your SD card prepared as per earlier, with the Raspbian Lite Operating installed and SSH enabled. Your Pi is connected to your network via an Ethernet cable.
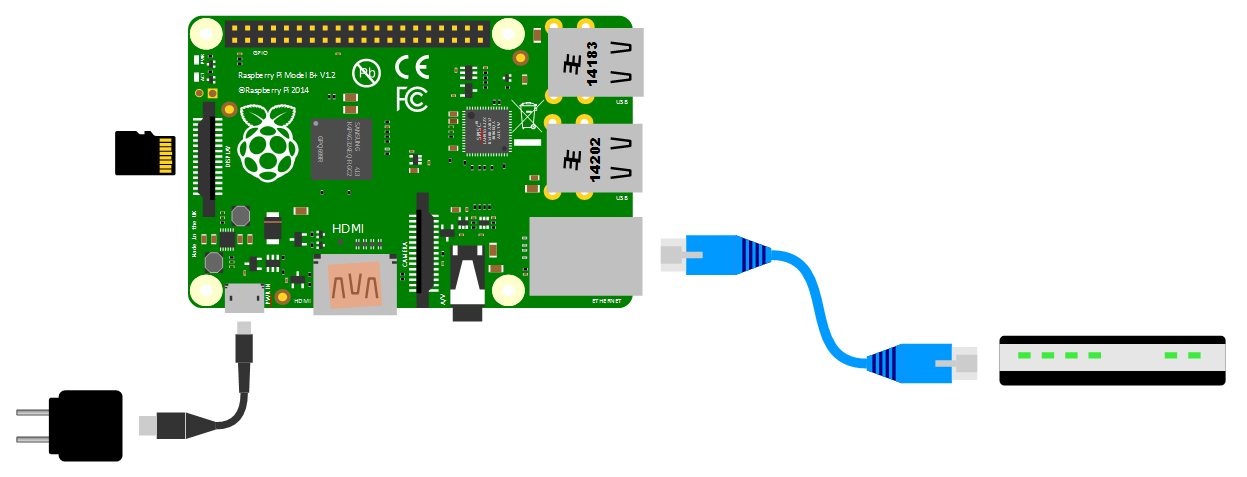
Put the SD card into the Pi and turn on the power!
You should see the activity light going through some flashing cycles. During this time it’s booting up, expanding the available space on the SD card and negotiating a connection on the network. This should take about 90 seconds.
Now you’re sitting there and wondering what to do. Good news. Read on for the remote access experience!
Connecting to the Pi Remotely.
Hopefully you set up one of the remote access options from earlier in the book. Putty would be just fine. We can connect with the host name ‘raspberrypi.local’ using the user ‘pi’ and the password ‘raspberry’.
Firstly starting Putty and putting ‘raspberrypi.local’ in the Host Name space.
The first time we connect we’ll get a warning that we need to be sure that we trust the new host. We do. Click on yes.
Then put in ‘pi’ as the user to login as;
And enter the default password for pi (spoiler alert, it’s ‘raspberry’).
You will then be logged in!
Congratulations, you have a working Raspberry Pi, you have logged in REMOTELY (kudos achieved) and you are now ready to start the installation of PiMetric!
Wireless connection
Headless (full kudos+)
For this installation you have your SD card prepared as per earlier, with the Raspbian Lite Operating installed and SSH enabled. Don’t put your SD card into your Pi just yet though, because first we need to tell you how to pre-configure your Pi to boot up and connect to your WiFi network automagically.
To do this we need to create another file on the SD card. So put it back in the desktop computer and create a file called wpa_supplicant.conf in the same main directory that we put the ‘ssh’ file in.
Just be careful that the file is named wpa_supplicant.conf since Windows may try to force the suffix of the file to be a ‘.txt’ file or similar.
When you’ve got the file created, paste the following contents in there (Change ssid (the name of your WiFi network) and password (psk) according to your own network).
wpa_supplicant.conf file will be copied to /etc/wpa_supplicant/ directory on boot and our Pi will be connected to the WiFi network automatically.
Finalize basic setup
Unmount the SD card and install it in the Pi.
Power on and let the device go through the first boot routine which will expand the disk and reboot. Be patient. This may take around 90 seconds or so.
Now you’re sitting there and wondering what to do. Good news. Read on for the remote access experience!
Connecting to the Pi Remotely.
Hopefully you set up one of the remote access options from earlier in the book. Putty would be just fine. We can connect with the host name ‘raspberrypi.local’ using the user ‘pi’ and the password ‘raspberry’.
Firstly starting Putty and putting ‘raspberrypi.local’ in the Host Name space.
The first time we connect we’ll get a warning that we need to be sure that we trust the new host. We do. Click on yes.
Then put in ‘pi’ as the user to login as;
And enter the default password for pi (spoiler alert, it’s ‘raspberry’).
You will then be logged in!
Congratulations, you have a working Raspberry Pi, you have logged in REMOTELY via WIFI (kudos + achieved) and you are now ready to start the installation of PiMetric!
PiMetric Installation
The installation process is based on the presumption that is is carried out on a Raspberry Pi. This is obviously not the only platform that could be used, but at this stage in development, any variation from that will be going beyond what has been tested (Fair warning).
The instructions below should be sufficient to get you running, assuming that you have some basic Linux and computing skills or are willing to be brave and step outside your comfort zone.
Starting point
The starting point should be a Raspberry Pi with a fresh installation of Raspbian-Lite loaded. It should also either have a keyboard / monitor connected or have ssh enabled with access from a remote computer (remote access is definitely preferred).
Carry out the installation
The general overview of the process from here is that we’re going to download a set-up script from the PiMetric GitHub code repository, make any changes required to run the script and let it do the rest! It sounds pretty easy, but behind that simplicity there are a bunch of installation commends that get called to carry out the magic. I won’t claim to be very experienced at this sort of thing, so if you come across something that can be improved with the process I would be very interested to hear from you :-).
Once we are logged into the Pi we can download the set-up script, assign appropriate permissions and get started
So at the command line on the terminal of your Raspberry Pi let’s download our set-up script;
cURL is a command line tool for downloading or sending files from the command line. It has a large number of different features and capabilities. In the example above we use the -O option to ensure that the downloaded file that has the same name as on the system it originates from and the -L option ensures that if the server reports that the requested page has moved to a different location it will still retrieve it.
Once we have downloaded the file we make sure that we have the correct permissions to run it using the chmod command.
At this point we need to decide what the domain name of the raspberry pi will be. The default is pimetric. This means that when we go to access the server from a web page, we do so using the address http://pimetric.local/main.php. If you want to change that name to something else, we will need to edit the setup-pimetric-full.sh file with the ‘nano’ editor…
… and change the name on the line that says;
Once you’ve finished editing, stop editing using ctrl-X and then confirm the file name.
Now we can run the script to get the installation underway.
The sudo prefix to the command tells the computer to run the script as the ‘superuser’ There are a number of commends in the set-up script that require that level of permission and that gets things going.
Then script will take over from this point. Depending on your Internet connection speed and the type of Pi you’re using the speed of the install will vary.
During the process it will complete the installation by doing the following;
- Update and upgrade the OS
- Get the PiMetric files from GitHub
- Unzip the Files
- Change the name of the directory
- Change the permissions / ownership of the directory and files
- Allow the ‘www-data’ group permission to write to the directory
- Add the ‘pi’ user to the ‘www-data’ group.
- Give the database the appropriate permissions for access
- Install the NGINX web server and php
- Configure NGINX to include php support and change the root location for the web server
- Restart the NGINX service
- Install the SQLite database and programs for accessing different metrics
- Install the Python 3 script modules
- Add the crontab lines
- Reboot
Hopefully everything goes smoothly. If not you can check out the log file that gets built in the pi home directory.
We’re done
We should now have a functional installation of PiMetric. We should be able to browse to ‘http://pimetric.local/read.php’ to see the list of metrics currently installed and operating. Likewise we should be able to go to ‘http://pimetric.local/main.php’ to look at the operational view.
From here you will want to think about adding your own metrics!
Operation
Todo: A description of the overall concept of operations of PiMetric
Measurement
Todo: A description of the measurement function. The measurement core focuses on getting information and recording it.
The processes are individually scheduled and run via a cron job.
Management
The management is carried out using a simple CRUD (Create, Read, Update, Delete) system. This provides the ability create, edit, delete and view the metric information. While it is not intended to be a operational interface, it shares some features of one.
The management system includes logging, validation and sanitization. This maintains the integrity of the SQLite database and the structure of the metrics.
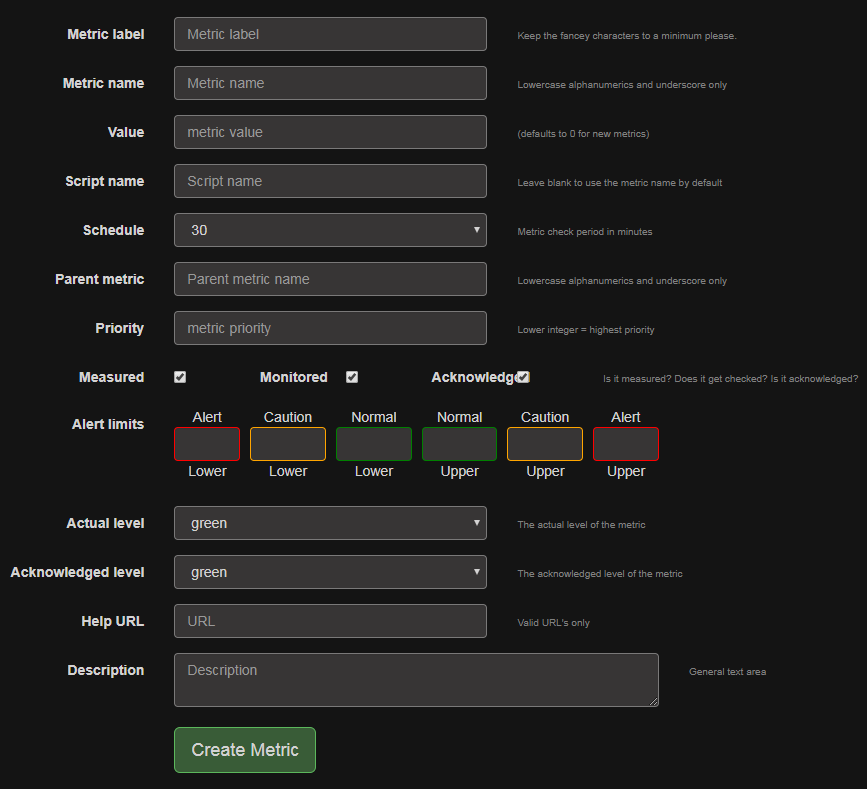
Create
Todo: A description of the Create function including the screens
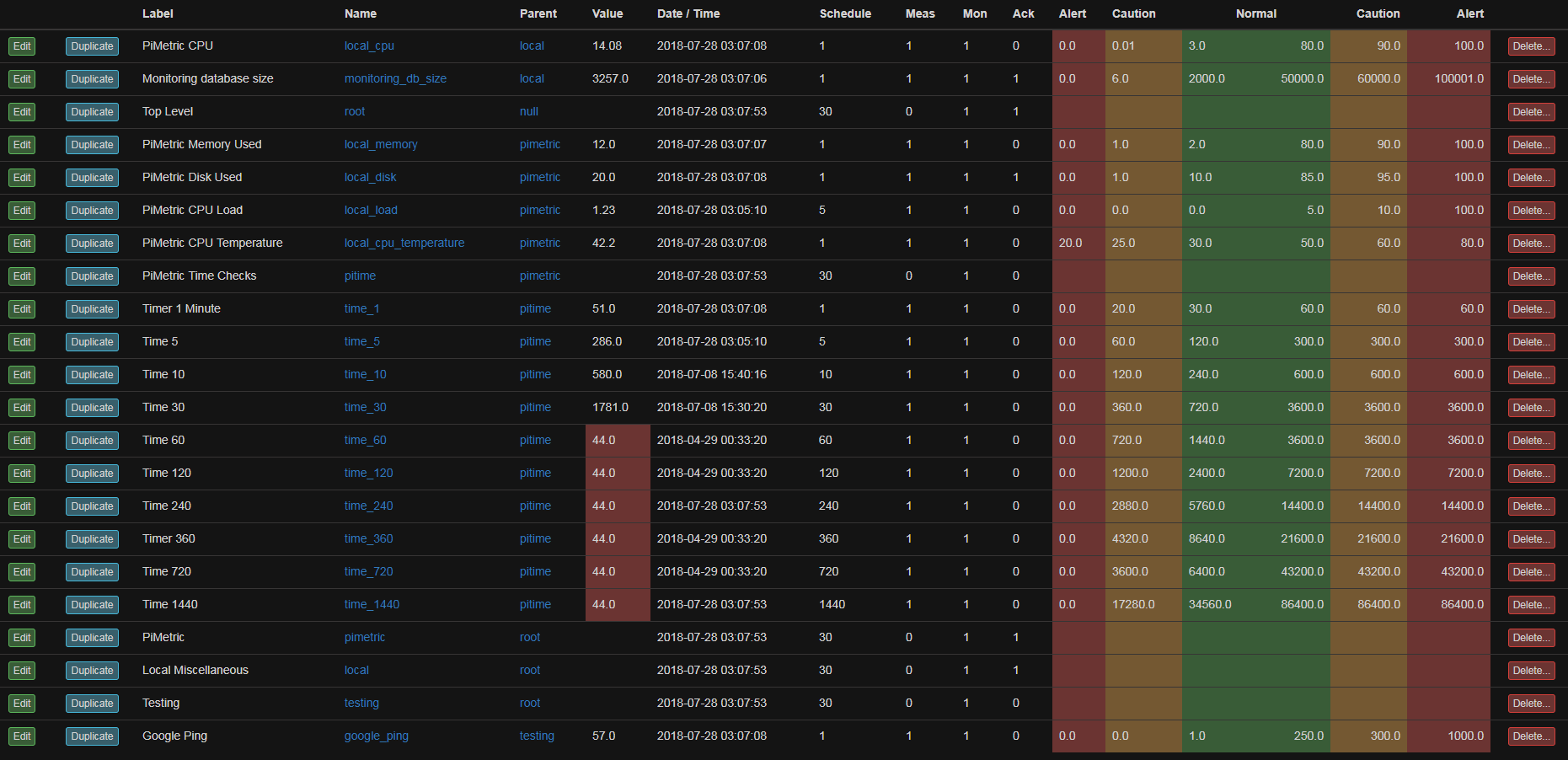
Read
Todo: A description of the Read function including the screens
Edit
Todo: A description of the Edit function including the screen
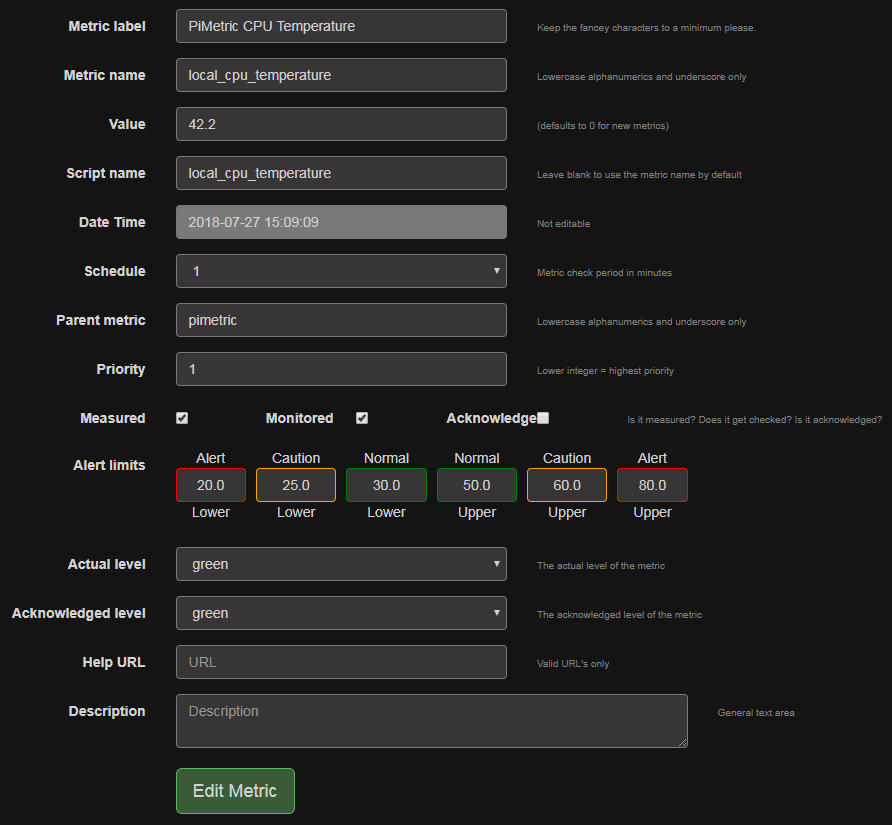
Fields
Todo: A breakdown of the fields
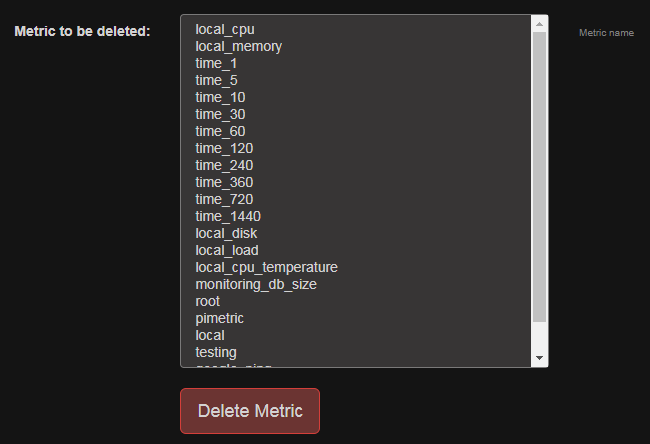
Delete
Todo: A description of the Delete function including the screens
Duplicate
Todo: A description of the Duplicate function including the screens
Operating
The operating layer provides an end user with the ability to explore the monitoring environment and the values that it has collected.
The way that it displays information is designed to allow an overview of what metrics are being measured in context with their roles. The user can also drill into the data and discover information that is useful to them.
It is also designed to respond to alerts when the metrics exceed their stated operating parameters. This provides a mechanism to manage faults, error conditions and to aid troubleshooting.
Operating Environment
Todo:
Tree Hierarchy
Todo:
Limits
Todo:
Acknowledged
Todo:
General Graphing
Todo:
View Metric
Todo:
Graphs
Todo:
Multi Graphs
Todo:
Configuration
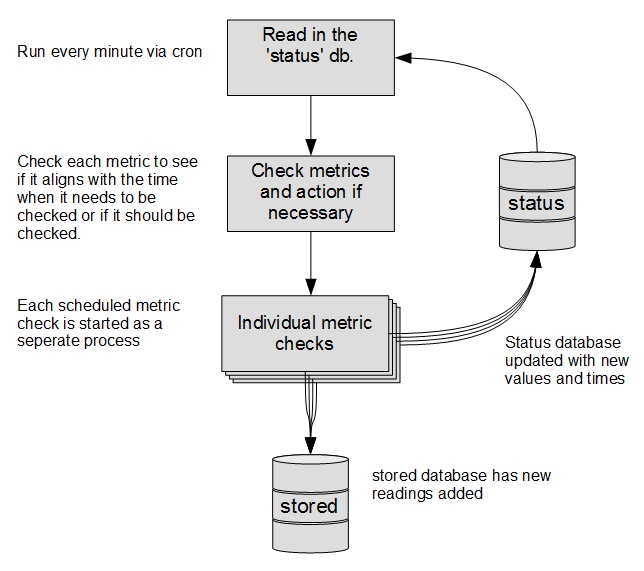
PiMetric relies on the collection of metrics taking place via a common method. That method involves individual python scripts that retrieve a value for each metric and then record it into the database.
The method allows for programmatic execution of the scripts in parallel (which reduces the time required to gather the values) and it uses python’s wide range of options for interfacing with external services
SNMP
For insturctions on setting up a Pi so that we have a device that we can monitor using SNMP see the instructions in the How To guide.
The following is the code to gather the percentage of used hard drive space on a remote Raspberry Pi (which has SNMP installed).
#!/usr/bin/python
#encoding:utf-8
# name of the metric
name = "used_disk_space"
# libraries required for metric measurement
import netsnmp
# Get the value
## Disk used (as a percentage) is hrStorageUsed.31/hrStorageSize.31
session = netsnmp.Session( DestHost='192.168.1.111', Version=1, Community='public\
' )
used_raw = netsnmp.VarList( netsnmp.Varbind('.1.3.6.1.2.1.25.2.3.1.6.31') )
size_raw = netsnmp.VarList( netsnmp.Varbind('.1.3.6.1.2.1.25.2.3.1.5.31') )
# correct for string to float and the bytes literal value
used = float(session.get(used_raw)[0].decode('utf-8'))
size = float(session.get(size_raw)[0].decode('utf-8'))
value = float("{0:.2f}".format(100*(used/size)))
############## Check Update and Store ##################
# Import the local python module
import checkupdatestore
checkupdatestore.row(name,value)
The code starts by importing the netsnmp module. It then declares the variables for the session that we will be accessing and the two values that we will be gathering.
The session variable is connecting to the Pi on the IP address 192.168.1.111.
The value that we want to read is the percentage of the hard drive that is used. This is a combination of the used space divided by the total space available. We need to check both so that we can calculate the percentage.
Using these variables we read the SNMP values used and size.
Then we can calculate and format the value for the percentage
How to…
Set-up SNMP on a Raspberry Pi to monitor it
This tutorial shows how to install SNMP on a Raspberry Pi so that we can monitor it remotely.
Be aware. This doesn’t let you monitor other Raspberry Pis. This is the preparation that you need to carry out on a Raspberry Pi so that you can monitor it.
Firstly we need to update/upgrade the system and install the programs reguired for SNMP.
Then we need to edit the configuration file to allow remote access.
Comment out the line below by putting a # in front of it;
Then we need to allow connections on all network interfaces (both IPv4 and IPv6) by un-commenting (removing the ‘#’ mark) the following line;
Now below the line;
add;
Save the file.
Now we restart the SNMP daemon:
To make sure that it has worked correctly, on the Pi (being monitored) we can walk the MIB (there’s a lot of info here) using the following command;
Towards the end you might see something like the following;
This shows the network interfaces that have been set up on the Pi and their snmp addresses.
To report back the information coded with MIBs (assuming that they’re loaded) use;
On the Pi (being monitored) we can check that our snmp requests are working using the following;
Which should output the following;
Linux Concepts
What is Linux?
In it’s simplest form, the answer to the question “What is Linux?” is that it’s a computer operating system. As such it is the software that forms a base that allows applications that run on that operating system to run.
In the strictest way of speaking, the term ‘Linux’ refers to the Linux kernel. That is to say the central core of the operating system, but the term is often used to describe the set of programs, tools, and services that are bundled together with the Linux kernel to provide a fully functional operating system.
An operating system is software that manages computer hardware and software resources for computer applications. For example Microsoft Windows could be the operating system that will allow the browser application Firefox to run on our desktop computer.
Linux is a computer operating system that is can be distributed as free and open-source software. The defining component of Linux is the Linux kernel, an operating system kernel first released on 5 October 1991 by Linus Torvalds.
Linux was originally developed as a free operating system for Intel x86-based personal computers. It has since been made available to a huge range of computer hardware platforms and is a leading operating system on servers, mainframe computers and supercomputers. Linux also runs on embedded systems, which are devices whose operating system is typically built into the firmware and is highly tailored to the system; this includes mobile phones, tablet computers, network routers, facility automation controls, televisions and video game consoles. Android, the most widely used operating system for tablets and smart-phones, is built on top of the Linux kernel.

The development of Linux is one of the most prominent examples of free and open-source software collaboration. Typically, Linux is packaged in a form known as a Linux distribution, for both desktop and server use. Popular mainstream Linux distributions include Debian, Ubuntu and the commercial Red Hat Enterprise Linux. Linux distributions include the Linux kernel, supporting utilities and libraries and usually a large amount of application software to carry out the distribution’s intended use.
A distribution intended to run as a server may omit all graphical desktop environments from the standard install, and instead include other software to set up and operate a solution stack such as LAMP (Linux, Apache, MySQL and PHP). Because Linux is freely re-distributable, anyone may create a distribution for any intended use.
Linux is not an operating system that people will typically use on their desktop computers at home and as such, regular computer users can find the barrier to entry for using Linux high. This is made easier through the use of Graphical User Interfaces that are included with many Linux distributions, but these graphical overlays are something of a shim to the underlying workings of the computer. There is a greater degree of control and flexibility to be gained by working with Linux at what is called the ‘Command Line’ (or CLI), and the booming field of educational computer elements such as the Raspberry Pi have provided access to a new world of learning opportunities at this more fundamental level.
Linux Directory Structure
To a new user of Linux, the file structure may feel like something at best arcane and in some cases arbitrary. Of course this isn’t entirely the case and in spite of some distribution specific differences, there is a fairly well laid out hierarchy of directories and files with a good reason for being where they are.
We are frequently comfortable with the concept of navigating this structure using a graphical interface similar to that shown below, but to operate effectively at the command line we need to have a working knowledge of what goes where.
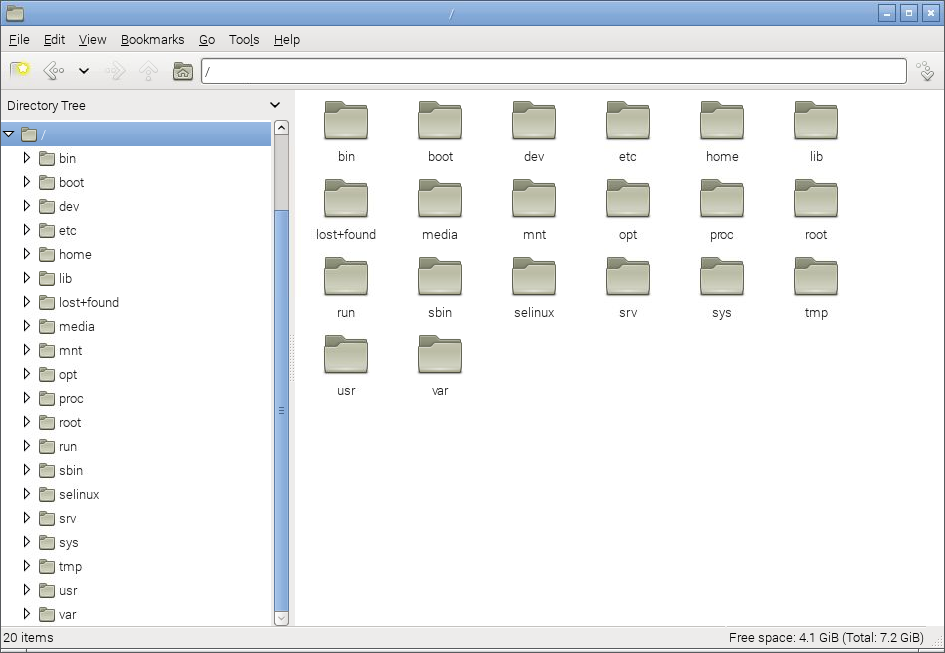
The directories we are going to describe form a hierarchy similar to the following;
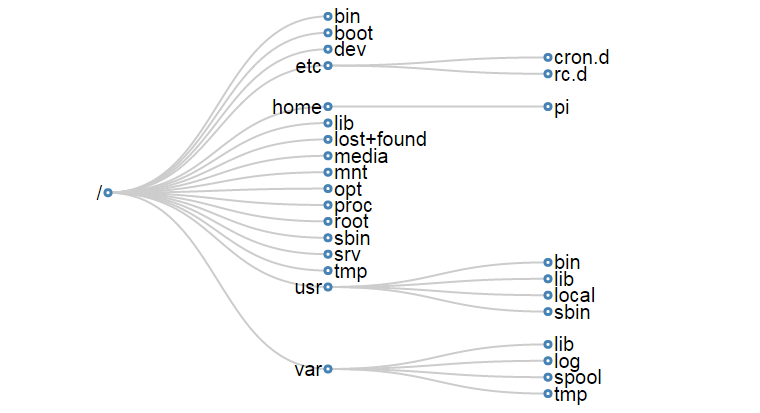
For a concise description of the directory functions check out the cheat sheet. Alternatively their function and descriptions are as follows;
/
The / or ‘root’ directory contains all other files and directories. It is important to note that this is not the root users home directory (although it used to be many years ago). The root user’s home directory is /root. Only the root user has write privileges for this directory.
/bin
The /bin directory contains common essential binary executables / commands for use by all users. For example: the commands cd, cp, ls and ping. These are commands that may be used by both the system administrator and by users, but which are required when no other filesystems are mounted.
/boot
The /boot directory contains the files needed to successfully start the computer during the boot process. As such the /boot directory contains information that is accessed before the Linux kernel begins running the programs and process that allow the operating system to function.
/dev
The /dev directory holds device files that represent physical devices attached to the computer such as hard drives, sound devices and communication ports as well as ‘logical’ devices such as a random number generator and /dev/null which will essentially discard any information sent to it. This directory holds a range of files that strongly reinforces the Linux precept that Everything is a file.
/etc
The /etc directory contains configuration files that control the operation of programs. It also contains scripts used to startup and shutdown individual programs.
/etc/cron.d
The /etc/cron.d, /etc/cron.hourly, /etc/cron.daily, /etc/cron.weekly, /etc/cron.monthly directories contain scripts which are executed on a regular schedule by the crontab process.
/etc/rc?.d
The /rc0.d, /rc1.d, /rc2.d, /rc3.d, /rc4.d, /rc5.d, /rc6.d, /rcS.d directories contain the files required to control system services and configure the mode of operation (runlevel) for the computer.
/home
Because Linux is an operating system that is a ‘multi-user’ environment, each user requires a space to store information specific to them. This is done via the /home directory. For example, the user ‘pi’ would have /home/pi as their home directory.
/lib
The /lib directory contains shared library files that supports the executable files located under /bin and /sbin. It also holds the kernel modules (drivers) responsible for giving Linux a great deal of versatility to add or remove functionality as needs dictate.
/lost+found
The /lost+found directory will contain potentially recoverable data that might be produced if the file system undergoes an improper shut-down due to a crash or power failure. The data recovered is unlikely to be complete or undamaged, but in some circumstances it may hold useful information or pointers to the reason for the improper shut-down.
/media
The /media directory is used as a directory to temporarily mount removable devices (for example, /media/cdrom or /media/cdrecorder). This is a relatively new development for Linux and comes as a result of a degree of historical confusion over where was best to mount these types of devices (/cdrom, /mnt or /mnt/cdrom for example).
/mnt
The /mnt directory is used as a generic mount point for filesystems or devices. Recent use of the directory is directing it towards it being used as a temporary mount point for system administrators, but there is a degree of historical variation that has resulted in different distributions doing things different ways (for example, Debian allocates /floppy and /cdrom as mount points while Redhat places them in /mnt/floppy and /mnt/cdrom respectively).
/opt
The /opt directory is used for the installation of third party or additional optional software that is not part of the default installation. Any applications installed in this area should be installed in such a way that it conforms to a reasonable structure and should not install files outside the /opt directory.
/proc
The /proc directory holds files that contain information about running processes and system resources. It can be described as a pseudo filesystem in the sense that it contains runtime system information, but not ‘real’ files in the normal sense of the word. For example the /proc/cpuinfo file which contains information about the computers cpus is listed as 0 bytes in length and yet if it is listed it will produce a description of the cpus in use.
/root
The /root directory is the home directory of the System Administrator, or the ‘root’ user. This could be viewed as slightly confusing as all other users home directories are in the /home directory and there is already a directory referred to as the ‘root’ directory (/). However, rest assured that there is good reason for doing this (sometimes the /home directory could be mounted on a separate file system that has to be accessed as a remote share).
/sbin
The /sbin directory is similar to the /bin directory in the sense that it holds binary executables / commands, but the ones in /sbin are essential to the working of the operating system and are identified as being those that the system administrator would use in maintaining the system. Examples of these commands are fdisk, shutdown, ifconfig and modprobe.
/srv
The /srv directory is set aside to provide a location for storing data for specific services. The rationale behind using this directory is that processes or services which require a single location and directory hierarchy for data and scripts can have a consistent placement across systems.
/tmp
The /tmp directory is set aside as a location where programs or users that require a temporary location for storing files or data can do so on the understanding that when a system is rebooted or shut down, this location is cleared and the contents deleted.
/usr
The /usr directory serves as a directory where user programs and data are stored and shared. This potential wide range of files and information can make the /usr directory fairly large and complex, so it contains several subdirectories that mirror those in the root (/) directory to make organisation more consistent.
/usr/bin
The /usr/bin directory contains binary executable files for users. The distinction between /bin and /usr/bin is that /bin contains the essential commands required to operate the system even if no other file system is mounted and /usr/bin contains the programs that users will require to do normal tasks. For example; awk, curl, php, python. If you can’t find a user binary under /bin, look under /usr/bin.
/usr/lib
The /usr/lib directory is the equivalent of the /lib directory in that it contains shared library files that supports the executable files for users located under /usr/bin and /usr/sbin.
/usr/local
The /usr/local directory contains users programs that are installed locally from source code. It is placed here specifically to avoid being inadvertently overwritten if the system software is upgraded.
/usr/sbin
The /usr/sbin directory contains non-essential binary executables which are used by the system administrator. For example cron and useradd. If you can’t locate a system binary in /usr/sbin, try /sbin.
/var
The /var directory contains variable data files. These are files that are expected to grow under normal circumstances For example, log files or spool directories for printer queues.
/var/lib
The /var/lib directory holds dynamic state information that programs typically modify while they run. This can be used to preserve the state of an application between reboots or even to share state information between different instances of the same application.
/var/log
The /var/log directory holds log files from a range of programs and services. Files in /var/log can often grow quite large and care should be taken to ensure that the size of the directory is managed appropriately. This can be done with the logrotate program.
/var/spool
The /var/spool directory contains what are called ‘spool’ files that contain data stored for later processing. For example, printers which will queue print jobs in a spool file for eventual printing and then deletion when the resource (the printer) becomes available.
/var/tmp
The /var/tmp directory is a temporary store for data that needs to be held between reboots (unlike /tmp).
Everything is a file in Linux
A phrase that will often come up in Linux conversation is that;
Everything is a file
For someone new to Linux this sounds like some sort of ‘in joke’ that is designed to scare off the unwary and it can sometimes act as a barrier to a deeper understanding of the philosophy behind the approach taken in developing Linux.
The explanation behind the statement is that Linux is designed to be a system built of a group of interacting parts and the way that those parts can work together is to communicate using a common method. That method is to use a file as a common building block and the data in a file as the communications mechanism.
The trick to understanding what ‘Everything is a file’ means, is to broaden our understanding of what a file can be.
Traditional Files
The traditional concept of a file is an object with a specific name in a specific location with a particular content. For example, we might have a file named foo.txt which is in the directory /home/pi/ and it could contain a couple of lines of text similar to the following;
Directories
As unusual as it sounds a directory is also a file. The special aspect of a directory is that is is a file which contains a list of information about which files (and / or subdirectories) it contains. So when we want to list the contents of a directory using the ls command what is actually happening is that the operating system is getting the appropriate information from the file that represents the directory.
System Information
However, files can also be conduits of information. The /proc/ directory contains files that represent system and process information. If we want to determine information about the type of CPU that the computer is using, the file cpuinfo in the /proc/ directory can list it. By running the command `cat /proc/cpuinfo’ we can list a wealth of information about our CPU (the following is a subset of that information by the way);
Now that might not mean a lot to us at this stage, but if we were writing a program that needed a particular type of CPU in order to run successfully it could check this file to ensure that it could operate successfully. There are a wide range of files in the /proc/ directory that represent a great deal of information about how our system is operating.
Devices
When we use different devices in a Linux operating system these are also represented as a file. In the /dev/ directory we have files that represent a range of physical devices that are part of our computer. In larger computer systems with multiple disks they could be represented as /dev/sda1 and /dev/sda2, so that when we wanted to perform an action such as formatting a drive we would use the command mkfs on the /dev/sda1 file.
The /dev/ directory also holds some curious files that are used as tools for generating or managing data. For example /dev/random is an interface to the kernels random number device. /dev/zero represents a file that will constantly stream zeros (while this might sound weird, imagine a situation where you want to write over an area of disk with data to erase it). The most well known of these unusual files is probably /dev/null. This will act as a ‘null device’ that will essentially discard any information sent to it.
File Editing
Working in Linux is an exercise in understanding the concepts that Linux uses as its foundations such as ‘Everything is a file’ and the use of wildcards, pipes and the directory structure.
While working at the command line there will very quickly come the realisation that there is a need to know how to edit a file. Linux being what it is, there are many ways that files can be edited.
An outstanding illustration of this is via the excellent cartoon work of the xkcd comic strip (Buy his stuff, it’s awesome!).
For a taste of the possible options available Wikipedia has got our back. Inevitably where there is choice there are preferences and where there are preferences there is bias. Everyone will have a preference towards a particular editor and don’t let a particular bias influence you to go down a particular direction without considering your options. Speaking from personal experience I was encouraged to use ‘vi’ as it represented the preference of the group I was in, but because I was a late starter to the command line I struggled for the longest time to try and become familiar with it. I know I should have tried harder, but I failed. For a while I wandered in the editor wilderness trying desperately to cling to the GUI where I could use ‘gedit’ or ‘geany’ and then one day I was introduced to ‘nano’.
This has become my preference and I am therefore biased towards it. Don’t take my word for it. Try alternatives. I’ll describe ‘nano’ below, but take that as a possible path and realise that whatever editor works for you will be the right one. The trick is simply to find one that works for you.
The nano Editor
The nano editor can be started from the command line using just the command and the /path/name of the file.
If the file requires administrator permissions it can be executed with ‘sudo`.
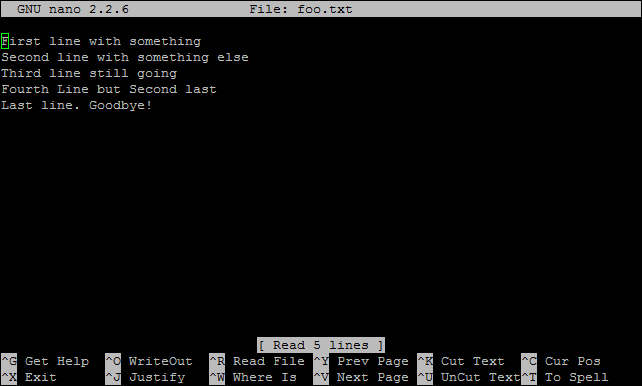
When it opens it presents us with a working space and part of the file and some common shortcuts for use at the bottom of the console;
It includes some simple syntax highlighting for common file formats;
This can be improved if desired (cue Google).
There is a swag of shortcuts to make editing easier, but the simple ones are as follows;
- CTRL-x - Exit the editor. If we are in the middle of editing a file we will be asked if we want to save our work
- CTRL-r - Read a file into our current working file. This enables us to add text from another file while working from within a new file.
- CTRL-k - Cut text.
- CTRL-u - Uncut (or Paste) text.
- CTRL-o - Save file name and continue working.
- CTRL-t - Check the spelling of our text.
- CTRL-w - Search the text.
- CTRL-a - Go to the beginning of the current working line.
- CTRL-e - Go to the end of the current working line.
- CTRL-g - Get help with nano.
Linux Commands
Executing Commands in Linux
A command is an instruction given by a user telling the computer to carry out an action. This could be to run a single program or a group of linked programs. Commands are typically initiated by typing them in at the command line (in a terminal) and then pressing the ENTER key, which passes them to the shell.
A terminal refers to a wrapper program which runs a shell. This used to mean a physical device consisting of little more than a monitor and keyboard. As Unix/Linux systems advanced the terminal concept was abstracted into software. Now we have programs such as LXTerminal (on the Raspberry Pi) which will launch a window in a Graphical User Interface (GUI) which will run a shell into which you can enter commands. Alternatively we can dispense with the GUI all together and simply start at the command line when we boot up.
The shell is a program which actually processes commands and returns output. Every Linux operating system has at least one shell, and most have several. The default shell on most Linux systems is bash.
The Commands
Commands on Linux operating systems are either built-in or external commands. Built-in commands are part of the shell. External commands are either executables (programs written in a programming language and then compiled into an executable binary) or shell scripts.
A command consists of a command name usually followed by one or more sequences of characters that include options and/or arguments. Each of these strings is separated by white space. The general syntax for commands is;
commandname [options] [arguments]
The square brackets indicate that the enclosed items are optional. Commands typically have a few options and utilise arguments. However, there are some commands that do not accept arguments, and a few with no options.
As an example we can run the ls command with no options or arguments as follows;
The ls command will list the contents of a directory and in this case the command and the output would be expected to look something like the following;
Options
An option (also referred to as a switch or a flag) is a single-letter code, or sometimes a single word or set of words, that modifies the behaviour of a command. When multiple single-letter options are used, all the letters are placed adjacent to each other (not separated by spaces) and can be in any order. The set of options must usually be preceded by a single hyphen, again with no intervening space.
So again using ls if we introduce the option -l we can show the total files in the directory and subdirectories, the names of the files in the current directory, their permissions, the number of subdirectories in directories listed, the size of the file, and the date of last modification.
The command we execute therefore looks like this;
And so the command (with the -l option) and the output would look like the following;
26
drwxr-xr-x 2 pi pi 4096 Feb 20 08:07 Desktop
drwxrwxr-x 2 pi pi 4096 Jan 27 08:34 python_games
Here we can see quite a radical change in the formatting and content of the returned information.
Arguments
An argument (also called a command line argument) is a file name or other data that is provided to a command in order for the command to use it as an input.
Using ls again we can specify that we wish to list the contents of the python_games directory (which we could see when we ran ls) by using the name of the directory as the argument as follows;
The command (with the python_games argument) and the output would look like the following (actually I removed quite a few files to make it a bit more readable);
Putting it all together
And as our final example we can combine our command (ls) with both an option (-l) and an argument (python_games) as follows;
Hopefully by this stage, the output shouldn’t come as too much surprise, although again I have pruned some of the files for readabilities sake;
1800
-rw-rw-r-- 1 pi pi 9731 Jan 27 08:34 4row_arrow.png
-rw-rw-r-- 1 pi pi 7463 Jan 27 08:34 4row_black.png
-rw-rw-r-- 1 pi pi 8666 Jan 27 08:34 4row_board.png
-rw-rw-r-- 1 pi pi 18933 Jan 27 08:34 4row_computerwinner.png
-rw-rw-r-- 1 pi pi 25412 Jan 27 08:34 4row_humanwinner.png
-rw-rw-r-- 1 pi pi 8562 Jan 27 08:34 4row_red.png
-rw-rw-r-- 1 pi pi 14661 Jan 27 08:34 tetrisc.mid
-rw-rw-r-- 1 pi pi 15759 Jan 27 08:34 tetrominoforidiots.py
-rw-rw-r-- 1 pi pi 18679 Jan 27 08:34 tetromino.py
-rw-rw-r-- 1 pi pi 9771 Jan 27 08:34 Tree_Short.png
-rw-rw-r-- 1 pi pi 11546 Jan 27 08:34 Tree_Tall.png
-rw-rw-r-- 1 pi pi 10378 Jan 27 08:34 Tree_Ugly.png
-rw-rw-r-- 1 pi pi 8443 Jan 27 08:34 Wall_Block_Tall.png
-rw-rw-r-- 1 pi pi 6011 Jan 27 08:34 Wood_Block_Tall.png
-rw-rw-r-- 1 pi pi 8118 Jan 27 08:34 wormy.py
apt-get
The apt-get command is a program, that is used with Debian based Linux distributions to install, remove or upgrade software packages. It’s a vital tool for installing and managing software and should be used on a regular basis to ensure that software is up to date and security patching requirements are met.
There are a plethora of uses for apt-get, but we will consider the basics that will allow us to get by. These will include;
- Updating the database of available applications (
apt-get update) - Upgrading the applications on the system (
apt-get upgrade) - Installing an application (
apt-get install *package-name*) - Un-installing an application (
apt-get remove *package-name*)
The apt-get command
The apt part of apt-get stands for ‘advanced packaging tool’. The program is a process for managing software packages installed on Linux machines, or more specifically Debian based Linux machines (Since those based on ‘redhat’ typically use their rpm (red hat package management (or more lately the recursively named ‘rpm package management’) system). As Raspbian is based on Debian, so the examples we will be using are based on apt-get.
APT simplifies the process of managing software on Unix-like computer systems by automating the retrieval, configuration and installation of software packages. This was historically a process best described as ‘dependency hell’ where the requirements for different packages could mean a manual installation of a simple software application could lead a user into a sink-hole of despair.
In common apt-get usage we will be prefixing the command with sudo to give ourselves the appropriate permissions;
apt-get update
This will resynchronize our local list of packages files, updating information about new and recently changed packages. If an apt-get upgrade (see below) is planned, an apt-get update should always be performed first.
Once the command is executed, the computer will delve into the internet to source the lists of current packages and download them so that we will see a list of software sources similar to the following appear;
[490 B]
Get:2 http://archive.raspberrypi.org wheezy Release.gpg [473 B]
Hit http://raspberrypi.collabora.com wheezy Release
Get:3 http://mirrordirector.raspbian.org wheezy Release [14.4 kB]
Get:4 http://archive.raspberrypi.org wheezy Release [17.6 kB]
Hit http://raspberrypi.collabora.com wheezy/rpi armhf Packages
Get:5 http://mirrordirector.raspbian.org wheezy/main armhf Packages [6,904 kB]
Get:6 http://archive.raspberrypi.org wheezy/main armhf Packages [130 kB]
Ign http://raspberrypi.collabora.com wheezy/rpi Translation-en
Ign http://mirrordirector.raspbian.org wheezy/contrib Translation-en
Ign http://mirrordirector.raspbian.org wheezy/main Translation-en
Ign http://mirrordirector.raspbian.org wheezy/non-free Translation-en
Ign http://mirrordirector.raspbian.org wheezy/rpi Translation-en
Fetched 7,140 kB in 35s (200 kB/s)
Reading package lists... Done
apt-get upgrade
The apt-get upgrade command will install the newest versions of all packages currently installed on the system. If a package is currently installed and a new version is available, it will be retrieved and upgraded. Any new versions of current packages that cannot be upgraded without changing the install status of another package will be left as they are.
As mentioned above, an apt-get update should always be performed first so that apt-get upgrade knows which new versions of packages are available.
Once the command is executed, the computer will consider its installed applications against the databases list of the most up to date packages and it will prompt us with a message that will let us know how many packages are available for upgrade, how much data will need to be downloaded and what impact this will have on our local storage. At this point we get to decide whether or not we want to continue;
6 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.
Need to get 10.7 MB of archives.
After this operation, 556 kB disk space will be freed.
Do you want to continue [Y/n]?
Once we say yes (‘Y’) the upgrade kicks off and we will see a list of the packages as they are downloaded unpacked and installed (what follows is an edited example);
continue [Y/n]? y
Get:1 http://archive.raspberrypi.org/debian/wheezy/main libsdl1.2debian
armhf 1.2.15-5+rpi1 [205 kB]
Get:2 http://archive.raspberrypi.org/debian/wheezy/main raspi-config all
20150131-5 [13.3 kB]
Get:3 http://mirrordirector.raspbian.org/raspbian/ wheezy/main libsqlite3-0
armhf 3.7.13-1+deb7u2 [414 kB]
Fetched 10.7 MB in 31s (343 kB/s)
Preconfiguring packages ...
(Reading database ... 80703 files and directories currently installed.)
Preparing to replace cups-common 1.5.3-5+deb7u5
(using .../cups-common_1.5.3-5+deb7u6_all.deb) ...
Unpacking replacement cups-common ...
Preparing to replace cups-bsd 1.5.3-5+deb7u5
(using .../cups-bsd_1.5.3-5+deb7u6_armhf.deb) ...
Unpacking replacement cups-bsd ...
Preparing to replace php5-gd 5.4.39-0+deb7u2
(using .../php5-gd_5.4.41-0+deb7u1_armhf.deb) ...
Unpacking replacement php5-gd ...
Processing triggers for man-db ...
Setting up libssl1.0.0:armhf (1.0.1e-2+rvt+deb7u17) ...
Setting up libsqlite3-0:armhf (3.7.13-1+deb7u2) ...
Setting up cups-common (1.5.3-5+deb7u6) ...
Setting up cups-client (1.5.3-5+deb7u6) ...
There can often be alerts as the process identifies different issues that it thinks the system might strike (different aliases, runtime levels or missing fully qualified domain names). This is not necessarily a sign of problems so much as an indication that the process had to take certain configurations into account when upgrading and these are worth noting. Whenever there is any doubt about what has occurred, Google will be your friend :-).
apt-get install
The apt-get install command installs or upgrades one (or more) packages. All additional (dependency) packages required will also be retrieved and installed.
If we want to install multiple packages we can simply list each package separated by a space after the command as follows;
apt-get remove
The apt-get remove command removes one (or more) packages.
cd
The cd command is used to move around in the directory structure of the file system (change directory). It is one of the fundamental commands for navigating the Linux directory structure.
cd [options] directory : Used to change the current directory.
For example, when we first log into the Raspberry Pi as the ‘pi’ user we will find ourselves in the /home/pi directory. If we wanted to change into the /home directory (go up a level) we could use the command;
Take some time to get familiar with the concept of moving around the directory structure from the command line as it is an important skill to establish early in Linux.
The cd command
The cd command will be one of the first commands that someone starting with Linux will use. It is used to move around in the directory structure of the file system (hence cd = change directory). It only has two options and these are seldom used. The arguments consist of pointing to the directory that we want to go to and these can be absolute or relative paths.
The cd command can be used without options or arguments. In this case it returns us to our home directory as specified in the /etc/passwd file.
If we cd into any random directory (try cd /var) we can then run cd by itself;
… and in the case of a vanilla installation of Raspbian, we will change to the /home/pi directory;
cd /var
pi@raspberrypi /var $ cd
pi@raspberrypi ~ $ pwd
/home/pi
In the example above, we changed to /var and then ran the cd command by itself and then we ran the pwd command which showed us that the present working directory is /home/pi. This is the Raspbian default home directory for the pi user.
Options
As mentioned, there are only two options available to use with the cd command. This is -P which instructs cd to use the physical directory structure instead of following symbolic links and the -L option which forces symbolic links to be followed.
For those beginning Linux, there is little likelihood of using either of these two options in the immediate future and I suggest that you use your valuable memory to remember other Linux stuff.
Arguments
As mentioned earlier, the default argument (if none is included) is to return to the users home directory as specified in the /etc/passwd file.
When specifying a directory we can do this by absolute or relative addressing. So if we started in the /home/pi directory, we could go the /home directory by executing;
… or using relative addressing and we can use the .. symbols to designate the parent directory;
Once in the /home directory, we can change into the /home/pi/Desktop directory using relative addressing as follows;
We can also use the - argument to navigate to the previous directory we were in.
Examples
Change into the root (/) directory;
Test yourself
- Having just changed from the
/home/pidirectory to the/homedirectory, what are the five variations of using thecdcommand that will take the pi user to the/home/pidirectory - Starting in the
/home/pidirectory and using only relative addressing, usecdto change into the/vardirectory.
chmod
The chmod command allows us to set or modify a file’s permissions. Because Linux is built as a multi-user system there are typically multiple different users with differing permissions for which files they can read / write or execute. chmod allows us to limit access to authorised users to do things like editing web files while general users can only read the files.
-
chmod[options] mode files : Change access permissions of one or more files & directories
For example, the following command (which would most likely be prefixed with sudo) sets the permissions for the /var/www directory so that the user can read from, write to and change into the directory. Group owners can also read from, write to and change into the directory. All others can read from and change into the directory, but they cannot create or delete a file within it;
This might allow normal users to browse web pages on a server, but prevent them from editing those pages (which is probably a good thing).
The chmod command
The chmod command allows us to change the permissions for which user is allowed to do what (read, write or execute) to files and directories. It does this by changing the ‘mode’ (hence chmod = change file mode) of the file where we can make the assumption that ‘mode’ = permissions.
Every file on the computer has an associated set of permissions. Permissions tell the operating system what can be done with that file and by whom. There are three things you can (or can’t) do with a given file:
- read it,
- write (modify) it and
- execute it.
Linux permissions specify what the owning user can do, what the members of the owning group can do and what other users can do with the file. For any given user, we need three bits to specify access permissions: the first to denote read (r) access, the second to denote (w) access and the third to denote execute (x) access.
We also have three levels of ownership: ‘user’, ‘group’ and ‘others’ so we need a triplet (three sets of three) for each, resulting in nine bits.
The following diagram shows how this grouping of permissions can be represented on a Linux system where the user, group and others had full read, write and execute permissions;
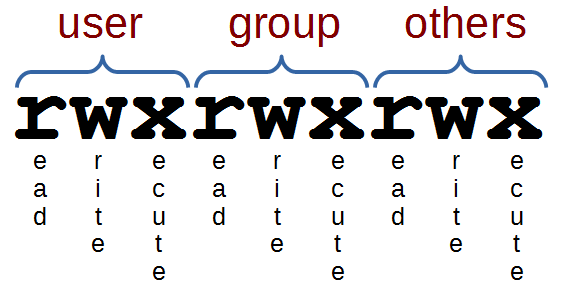
If we had a file with more complex permissions where the user could read, write and execute, the group could read and write, but all other users could only read it would look as follows;

This description of permissions is workable, but we will need to be aware that the permissions are also represented as 3 bit values (where each bit is a ‘1’ or a ‘0’ (where a ‘1’ is yes you can, or ‘0’ is no you can’t)) or as the equivalent octal value.
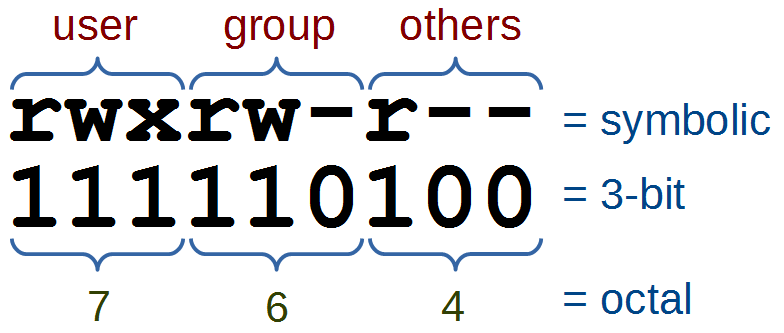
The full range of possible values for these permission combinations is as follows;
Another interesting thing to note is that permissions take a different slant for directories.
- read determines if a user can view the directory’s contents, i.e. execute
lsin it. - write determines if a user can create new files or delete file in the directory. (Note here that this essentially means that a user with write access to a directory can delete files in the directory even if he/she doesn’t have write permissions for the file! So be careful.)
- execute determines if the user can cd into the directory.
We can check the check the permissions of files using the ls -l command which will list files in a long format as follows;
This command will list the details of the file foo.txt that is in the /tmp directory as follows
1 pi pi-group 20 Jul 10 13:14 foo.txt
The permissions on the file, the user and the group owner can be found as follows;

From this information we can see that the file’s user (‘pi’) has permissions to read, write and execute the file. The group owner (‘pi-group’) can read and write to the file and all other users can read the file.
Options
The main option that is worth remembering is the -R option that will Recursively apply permissions on the files in the specified directory and its sub-directories.
The following command will change the permissions for all the files in the /srv/foo directory and in all the directories that are under it;
Arguments
Simplistically (in other words it can be more complicated, but we’re simplifying it) there are two main ways that chmod is used. In either symbolic mode where the permissions are changed using symbols associated with read, write and execute as well as symbols for the user (u), the group owner (g), others (o) and all users (a). Or in numeric mode where we use the octal values for permission combinations.
Symbolic Mode
In symbolic mode we can change the permissions of a file with the following syntax:
-
chmod[who][op][permissions] filename
Where who can be the user (u), the group owner (g) and / or others (o). The operator (op) is either + to add a permission, - to remove a permission or = to explicitly set permissions. The permissions themselves are either readable (r), writeable (w), or executable (x).
For example the following command adds executable permissions (x) to the user (u) for the file /tmp/foo.txt;
This command removes writing (w) and executing (x) permissions from the group owner (g) and all others (o) for the same file;
Note that removing the execute permission from a directory will prevent you from being able to list its contents (although root will override this). If you accidentally remove the execute permission from a directory, you can use the +X argument to instruct chmod to only apply the execute permission to directories.
Numeric Mode
In numeric mode we can explicitly state the permissions using the octal values, so this form of the command is fairly common.
For example, the following command will change the permissions on the file foo.txt so that the user can read, write and execute it, the group owner can read and write it and all others can read it;
Examples
To change the permissions in your home directory to remove reading and executing permissions from the group owner and all other users;
To make a script executable by the user;
Windows marks all files as executable by default. If you copy a file or directory from a Windows system (or even a Windows-formatted disk) to your Linux system, you should ideally strip the unnecessary execute permissions from all copied files unless you specifically need to retain it. Note of course we still need it on all //directories// so that we can access their contents! Here’s how we can achieve this in one command:
This instructs chmod to remove the execute permission for each file and directory, and then immediately set execute again if working on a directory.
chown
The chown command changes the user and/or group ownership of given files. Because Linux is built as a multi-user system there are typically multiple different users (not necessarily actual people, but daemons or other programs who may run as their own user) responsible for maintaining clear permission boundaries that separate services to prevent corruption or maintain security or privacy. This allows us to limit access to authorised users to do things like editing web files.
-
chown[options] newowner files : Change the ownership of one or more files & directories
For example, if we want to make the user www-data the owner of the directory www (in the /var directory) and we want to pass the group ownership of that directory to the group www-data we would run the following command;
There is a good likelihood that we would need to prefixed the command with sudo to run it as root depending on which user we were when we executed it.
The chown command
The chown command changes the user and/or group ownership of given files (hence chown = change owner).
It is used to help specify exactly who or what group can access certain files. There are several different options, but only one that could be deemed important enough to try and remember. There are also a number of different ways to assign ownership depending if we’re trying to assign a single user and / or group permissions. For more information on modifying permissions see chmod.
Options
The main option that is worth remembering is the -R option that will Recursively apply permissions on the files in the specified directory and its sub-directories.
The following command will change the owner to the user ‘apache’ for the /var/www directory and all the directories that are under it;
Arguments
The object that has its ownership changed can be a file or a directory and its contents.
One of the clever things about assigning permissions using chown is the way that user and group ownership can be applied in the same command (if desired).
If only a user name is given, that user is made the owner of each given file, and the files’ group is not changed.
If the owner is followed by a colon and a group name (with no space in between them) the group ownership of the files is changed as well. In the following example the user apache and the group apache-group are given ownership of the files in the /var/www directory;
If a colon but no group name follows the user name, that user is made the owner of the files and the group of the files is changed to that user’s initial login group. So if the apache users initial login group was apache-group then the following command would accomplish the same thing as the previous example;
If the colon and group are given, but the owner is omitted, only the group of the files is changed.
Examples
To change the ownership of the file /home/pi/foo.txt to the UID 3456 and the group ownership to GID 4321.
Test yourself
- What has gone horribly wrong if you execute this command;
- What command would you execute to change the group ownership of the files in the
/tmp/junkdirectory to the groupjunk-owners, but not the directory itself
crontab
The crontab command give the user the ability to schedule tasks to be run at a specific time or with a specific interval. If you want to move beyond using Linux from a graphical user interface, you will most likely want to schedule a task to run at a particular time or interval. Even just learning about it might give you ideas of what you might do.
-
crontab[-u user] [-l | -r | -e] : Schedule a task to run at a particular time or interval
For example, you could schedule a script to run every day to carry our a backup process in the middle of the night. or capture some data every hour to store in a database.
The crontab command
The command crontab is a concatenation of ‘cron table’ because it uses the job scheduler cron to execute tasks which are stored in a ‘table’ of sorts in the users crontab file. cron is named after ‘Khronos’, the Greek personification of time.
While each user who sets up a job to run using the crontab creates a crontab file, the file is not intended to be edited by hand. It is in different locations in different flavour of Linux distributions and the most reliable mechanism for editing it is by running the crontab -e command. Each user has their own crontab file and the root user can edit another users crontab file. This would be the situation where we would use the -u option, but honestly once we get to that stage it can probably be assumed that we know a fair bit about Linux.
There are only three main options that are used with crontab.
Options
The first option that we should examine is the -l option which allows us to list the crontab file;
Once run it will list the contents of the crontab file directly to the screen. The output will look something like;
Here we can see that the main part of the file (in fact everything except the final line) is comments that explain how to include an entry into the crontab file.
The entry in this case is specified to run every 10 minutes and when it does, it will run the PHP script scrape-books.php (we’ll explain how this is encoded later in the examples section).
If we want to remove the current crontab we can use the -r option. Probably not something that we would do an a regular basis, as it would be more likely to be editing the content rather than just removing it wholesale.
Lastly there is the option to edit the crontab file which is initiated using -e. This is the main option that would be used and the one we will cover in detail in the examples below.
Examples
As an example, consider that we wish to run a Python script every day at 6am. The following command will let us edit the crontab;
Once run it will open the crontab in the default editor on your system (most likely ‘vi’, ‘vim’ or ‘nano’). The file will look as follows;
As stated earlier, the default file obviously includes some explanation of how to format an entry in the crontab. In our case we wish to add in an entry that tells the script to start at 6 hours and 0 minutes each day. The crontab accepts six pieces of information that will allow that action to be performed. each of those pieces is separated by a space.
- A number (or range of numbers), m, that represents the minute of the hour (valid values 0-59);
- A number (or range of numbers), h, that represents the hour of the day (valid values 0-23);
- A number (or range of numbers), dom, that represents the day of the month (valid values 0-31);
- A number (or list, or range), or name (or list of names), mon, that represents the month of the year (valid values 1-12 or Jan-Dec);
- A number (or list, or range), or name (or list of names), dow, that represents the day of the week (valid values 0-6 or Sun-Sat); and
- command, which is the command to be run, exactly as it would appear on the command line.
The layout is therefore as follows;
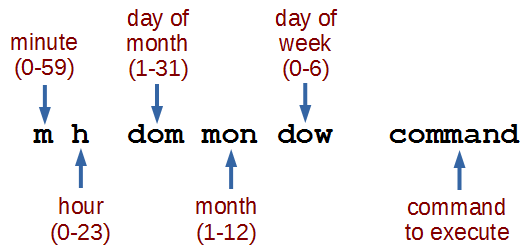
Assuming that we want to run a Python script called ‘m_temp.py` which was in the ‘pi’ home directory the line that we would want to add would be as follows;
0 6 * * * /usr/bin/python /home/pi/m_temp.py
So at minute 0, hour 6, every day of the month (where the asterisk denotes ‘everything’), every month, every day of the week we run the command /usr/bin/python /home/pi/m_temp.py (which, if we were at the command line in the pi home directory we would run as python m_temp.py, but since we can’t guarantee where we will be when running the script, we are supplying the full path to the python command and the m_temp.py script.
If we wanted to run the command twice a day (6am and 6pm (1800hrs)) we can supply a comma separated value in the hours (h) field as follows;
0 6,18 * * * /usr/bin/python /home/pi/m_temp.py
If we wanted to run the command at 6am but only on weekdays (Monday through Friday) we can supply a range in the dow field as follows (remembering that 0 = Sunday);
0 6 * * 1-5 /usr/bin/python /home/pi/m_temp.py
If we want to run the same command every 2 hours we can use the */2 notation, so that our line in the crontab would look like the following;
0 */2 * * * /usr/bin/python /home/pi/m_temp.py
It’s important to note that we need to include the 0 at the start (instead of the *) so that it doesn’t run every minute every 2 hours (every minute in other words)
Test yourself
- How could you set up a schedule job in crontab that ran every second?
- Create a crontab line to run a command on the 20th of July every year at 2 minutes past midnight.
ls
The ls command lists the contents of a directory and can show the properties of those objects it lists. It is one of the fundamental commands for knowing what files are where and the properties of those files.
-
ls[options] directory : List the files in a particular directory
For example: If we execute the ls command with the -l option to show the properties of the listings in long format and with the argument /var so that it lists the content of the /var directory…
… we should see the following;
102440
drwxr-xr-x 2 root root 4096 Mar 7 06:25 backups
drwxr-xr-x 12 root root 4096 Feb 20 08:33 cache
drwxr-xr-x 43 root root 4096 Feb 20 08:33 lib
drwxrwsr-x 2 root uucp 4096 Jan 11 00:02 local
lrwxrwxrwx 1 root root 9 Feb 15 11:23 lock -> /run/lock
drwxr-xr-x 11 root root 4096 Jul 7 06:25 log
drwxrwsr-x 2 root mail 4096 Feb 15 11:23 mail
drwxr-xr-x 2 root root 4096 Feb 15 11:23 opt
lrwxrwxrwx 1 root root 4 Feb 15 11:23 run -> /run
drwxr-xr-x 4 root root 4096 Feb 15 11:26 spool
-rw------- 1 root root 104857600 Feb 16 14:03 swap
drwxrwxrwt 2 root root 4096 Jan 11 00:02 tmp
drwxrwxr-x 2 www-data www-data 4096 Feb 20 08:21 www
The ls command
The ls command will be one of the first commands that someone starting with Linux will use. It is used to list the contents of a directory (hence ls = list). It has a large number of options for displaying listings and their properties in different ways. The arguments used are normally the name of the directory or file that we want to show the contents of.
By default the ls command will show the contents of the current directory that the user is in and just the names of the files that it sees in the directory. So if we execute the ls command on its own from the pi users home directory (where we would be after booting up the Raspberry Pi), this is the command we would use;
… and we should see the following;
This shows two directories (Desktop and python_games) that are in pi’s home directory, but there are no details about the directories themselves. To get more information we need to include some options.
Options
There are a very large number of options available to use with the ls command. For a full listing type man ls on the command line. Some of the most commonly used are;
-
-lgives us a long listing (as explained above) -
-ashows us aLL the files in the directory, including hidden files -
-sshows us the size of the files (in blocks, not bytes) -
-hshows the size in “human readable format” (ie: 4K, 16M, 1G etc). (must be used in conjunction with the -s option). -
-Ssorts by file Size -
-tsorts by modification time -
-rreverses order while sorting
A useful combination of options could be a long listing (-l) that shows all (-a) the files with the file size being reported in human readable (-h) block size (-s).
… will produce something like the following;
4.0K drwxr-xr-x 13 pi pi 4.0K May 7 11:46 .
4.0K drwxr-xr-x 3 root root 4.0K May 7 10:20 ..
4.0K -rw-r--r-- 1 pi pi 69 May 7 11:46 .asoundrc
4.0K -rw------- 1 pi pi 854 Jul 8 12:55 .bash_history
4.0K -rw-r--r-- 1 pi pi 3.2K May 7 10:20 .bashrc
4.0K drwxr-xr-x 4 pi pi 4.0K May 7 11:46 .cache
4.0K drwxr-xr-x 7 pi pi 4.0K May 7 11:46 .config
4.0K drwxr-xr-x 2 pi pi 4.0K May 7 11:46 Desktop
4.0K drwxr-xr-x 2 pi pi 4.0K May 7 11:46 .fontconfig
4.0K drwxr-xr-x 2 pi pi 4.0K May 7 11:46 .gstreamer-0.10
4.0K drwx------ 3 pi pi 4.0K May 7 11:46 .local
4.0K -rw-r--r-- 1 pi pi 675 May 7 10:20 .profile
4.0K drwxrwxr-x 2 pi pi 4.0K Jan 27 21:34 python_games
4.0K drwxr-xr-x 3 pi pi 4.0K May 7 11:46 .themes
Arguments
The default argument (if none is included) is to list the contents of the directory that the user is currently in. Otherwise we can specify the directory to list. This might seem like a simple task, but there are a few tricks that can make using ls really versatile.
The simplest example of using a specific directory for an argument is to specify the location with the full address. For example, if we wanted to list the contents of the /var directory (and it doesn’t matter which directory we run this command from) we simply type;
… will produce the following;
local lock log mail opt run spool swap tmp www
We can also use some of the relative addressing characters to shortcut our listing. We can list the home directory by using the tilde (ls ~) and the parent directory by using two full stops (ls ..).
The asterisk (*) can be used as a wildcard to list files with similar names. E.g. to list all the png file in a directory we can use ls *.png.
If we just want to know the details of a specific file we can use its name explicitly. For example if we wanted to know the details of the swap file in /var we would use the following command;
… which will produce the following;
1 root root 104857600 May 7 11:29 /var/swap
Examples
List all the configuration (.conf) files in the /etc directory;
… which will produce the following;
ping
The ping command allows us to check the network connection between the local computer and a remote server. It does this by sending a request to the remote server to reply to a message (kind of like a read-request in email). This allows us to test network connectivity to the remote server and to see if the server is operating. The ping command is a simple and commonly used network troubleshooting tool.
-
ping[options] remote server : checks the connection to a remote server.
To check the connection to the server at CNN for example we can simple execute the following command (assuming that we have a connection to the internet);
Which will return something like the following;
The first thing to note is that by default the ping command will just keep running. When we want to stop it we need to press CTRL-c to get it to stop.
The information presented is extremely useful and tells us that www.cnn.com’s IP address is 157.166.226.25 and that the time taken for a ping send and return message took about 250 milliseconds.
The ping command
The ping command is a very simple network / connectivity checking tool that is one of the default ‘go-to’ commands for system administrators. You might be wondering about how the name has come about. It is reminiscent of the echo-location technique used by dolphins, whales and bats to send out a sound and to judge their surroundings by the returned echo. In the dramatised world of the submariner, a ping is the sound emitted by a submarine in the same way to judge the distance and direction to an object. It was illustrated to best effect in the book by Tom Clancy and the subsequent movie “The Hunt for Red October” where the submarine commander makes the request for “One Ping Only”.

It works by sending message called an ‘Echo Request’ to a specific network location (which we specify as part of the command). When (or if) the server receives the request it sends an ‘Echo Reply’ to the originator that includes the exact payload received in the request. The command will continue to send and (hopefully) receive these echoes until the command completes its requisit number of attempts or the command is stopped by the user (with a CTRL-c). Once complete, the command summarises the effort.
From the example used above we can see the output as follows;
We can see from the returned pings that the IP address of the server that is designated as ‘www.cnn.com’ is ‘157.166.226.25’ The resolution of the IP address would be made possible by DNS, but using a straight IP address is perfectly fine). The icmp_seq= column tells us the sequence of the returned replies and ttl indicates how many IP routers the packet can go through before being thrown away. The time provides the measured return trip of the request and reply.
The summary at completion tells us how many packets were sent and how many received back. This forms a percentage of lost packets which is established over the specified time. The final line provides a minimum, average maximum and standard deviation from the mean.
Options
There are a few different options for use, but the more useful are as follows;
-
-conly ping the connection a certain number (count) of times -
-ichange the time interval between pings
It’s really useful to have ping running continuously so that we can make changes to networking while watching the results, but it’s also useful to run the command for a limited amount of time. This is where the -c option comes in. This will simply restrict the number of pings that are sent out and will then cease and summarise the effort. This can be used as follows;
Which will return something like the following;
Sometimes it can be convenient to set our own time interval between pings. This can be accomplished with the -i option which will let us vary the repeat time. The default is 1 second, however the value cannot be set below 0.2 seconds without doing so as the superuser. Interestingly there is an option to flood the network with pings (flood mode) to test the network infrastructure. However, this would be something typically left to research carefully when you really need it.
Test yourself
- How does the ping command to a server name know how to return an IP address?
- What does ‘ttl’ stand for?
sudo
The sudo command allows a user to execute a command as the ‘superuser’ (or as another user). It is a vital tool for system administration and management.
-
sudo[options] [command] : Execute a command as the superuser
For example, if we want to update and upgrade our software packages, we will need to do so as the super user. All we need to do is prefix the command apt-get with sudo as follows;
One of the best illustrations of this is via the excellent cartoon work of the xkcd comic strip (Buy his stuff, it’s awesome!).

The sudo command
The sudo command is shorthand for ‘superuser do’.
When we use sudo an authorised user is determined by the contents of the file /etc/sudoers.
As an example of usage we should check out the file /etc/sudoers. If we use the cat command to list the file like so;
We get the following response;
That’s correct, the ‘pi’ user does not have permissions to view the file
Let’s confirm that with ls;
Which will result in the following;
1 root root 696 May 7 10:39 /etc/sudoers
It would appear that only the root user can read the file!
So let’s use sudo to cat](#cat) the file as follows;
That will result in the following output;
There’s a lot of information in the file, but there, right at the bottom is the line that determines the privileges for the ‘pi’ user;
We can break down what each section means;
pi
pi ALL=(ALL) NOPASSWD: ALL
The pi portion is the user that this particular rule will apply to.
ALL
pi ALL=(ALL) NOPASSWD: ALL
The first ALL portion tells us that the rule applies to all hosts.
ALL
pi ALL=(ALL) NOPASSWD: ALL
The second ALL tells us that the user ‘pi’ can run commands as all users and all groups.
NOPASSWD
pi ALL=(ALL) NOPASSWD: ALL
The NOPASSWD tells us that the user ‘pi’ won’t be asked for their password when executing a command with sudo.
All
pi ALL=(ALL) NOPASSWD: ALL`
The last ALL tells us that the rules on the line apply to all commands.
Under normal situations the use of sudo would require a user to be authorised and then enter their password. By default the Raspbian operating system has the ‘pi’ user configured in the /etc/sudoers file to avoid entering the password every time.
If your curious about what privileges (if any) a user has, we can execute sudo with the -l option to list them;
This will result in output that looks similar to the following;
for pi on this host:
env_reset, mail_badpass,
secure_path=/usr/local/sbin\:/usr/local/bin\:/usr/sbin\:/usr/bin\:/sbin\:/bin
User pi may run the following commands on this host:
(ALL : ALL) ALL
(ALL) NOPASSWD: ALL
The ‘sudoers’ file
As mentioned above, the file that determines permissions for users is /etc/sudoers. DO NOT EDIT THIS BY HAND. Use the visudo command to edit. Of course you will be required to run the command using sudo;
sudo vs su
There is a degree of confusion about the roles of the sudo command vs the su command. While both can be used to gain root privileges, the su command actually switches the user to another user, while sudo only runs the specified command with different privileges. While there will be a degree of debate about their use, it is widely agreed that for simple on-off elevation, sudo is ideal.
Test yourself
- Write an entry for the
sudoersfile that provides sudo priviledges to a user for only thecatcommand. - Under what circumstances can you edit the
sudoersfile with a standard text editor.
Directory Structure Cheat Sheet
-
/: The ‘root’ directory which contains all other files and directories -
/bin: Common commands / programs, shared by all users -
/boot: Contains the files needed to successfully start the computer during the boot process -
/dev: Holds device files that represent physical and ‘logical’ devices -
/etc: Contains configuration files that control the operation of programs -
/etc/cron.d: One of the directories that allow programs to be run on a regular schedule -
/etc/rc?.d: Directories containing files that control the mode of operation of a computer -
/home: A directory that holds subdirectories for each user to store user specific files -
/lib: Contains shared library files and kernel modules -
/lost+found: Will hold recoverable data in the event of an an improper shut-down -
/media: Used to temporarily mount removable devices -
/mnt: A mount point for filesystems or temporary mount point for system administrators -
/opt: Contains third party or additional software that is not part of the default installation -
/proc: Holds files that contain information about running processes and system resources -
/root: The home directory of the System Administrator, or the ‘root’ user -
/sbin: Contains binary executables / commands used by the system administrator -
/srv: Provides a consistent location for storing data for specific services -
/tmp: A temporary location for storing files or data -
/usr: Is the directory where user programs and data are stored and shared -
/usr/bin: Contains binary executable files for users -
/usr/lib: Holds shared library files to support executables in/usr/binand/usr/sbin -
/usr/local: Contains users programs that are installed locally from source code -
/usr/sbin: The directory for non-essential system administration binary executables -
/var: Holds variable data files which are expected to grow under normal circumstances -
/var/lib: Contains dynamic state information that programs modify while they run -
/var/log: Stores log files from a range of programs and services -
/var/spool: Contains files that are held (spooled) for later processing -
/var/tmp: A temporary store for data that needs to be held between reboots (unlike/tmp)
Static IP Address
Enabling remote access can be a really useful thing. To do so we will want to assign our Raspberry Pi a static IP address.
An Internet Protocol address (IP address) is a numerical label assigned to each device (e.g., computer, printer) participating in a computer network that uses the Internet Protocol for communication. Think of it like your home address. It contains all the information to allow someone to send you mail. Likewise an IP address has all the information required so that information can find it on a network.
There is a strong likelihood that our Raspberry Pi already has an IP address and it should appear a few lines above the ‘login’ prompt when you first boot up;
The My IP address... part should appear just above or around 15 lines above the login line, depending on the version of Raspbian we’re using. In this example the IP address 10.1.1.25 belongs to the Raspberry Pi.
This address will probably be a ‘dynamic’ IP address and could change each time the Pi is booted. For the purposes of using the Raspberry Pi with a degree of certainty when logging in to it remotely it’s easier to set a fixed IP address.
This description of setting up a static IP address makes the assumption that we have a device running on our network that is assigning IP addresses as required. This sounds complicated, but in fact it is a very common service to be running on even a small home network and most likely on an ADSL modem/router or similar. This function is run as a service called DHCP (Dynamic Host Configuration Protocol). You will need to have access to this device for the purposes of knowing what the allowable ranges are for a static IP address.
The Netmask
A common feature for home modems and routers that run DHCP devices is to allow the user to set up the range of allowable network addresses that can exist on the network. At a higher level we should be able to set a ‘netmask’ which will do the job for us. A netmask looks similar to an IP address, but it allows you to specify the range of addresses for ‘hosts’ (in our case computers) that can be connected to the network.
A very common netmask (in a domestic situation) is 255.255.255.0 which means that the network in question can have any one of the combinations where the final number in the IP address varies. In other words with a netmask of 255.255.255.0, the IP addresses available for devices on the network ‘10.1.1.x’ range from 10.1.1.0 to 10.1.1.255 or in other words any one of 256 unique addresses.
CIDR Notation
An alternative to specifying a netmask in the format of ‘255.255.255.0’ is to use a system called Classless Inter-Domain Routing, or CIDR. The idea is to add a specification in the IP address itself that indicates the number of significant bits that make up the netmask.
For example, we could designate the IP address 10.1.1.17 as associated with the netmask 255.255.255.0 by using the CIDR notation of 10.1.1.17/24. This means that the first 24 bits of the IP address given are considered significant for the network routing.
Using CIDR notation allows us to do some very clever things to organise our network, but at the same time it can have the effect of confusing people by introducing a pretty complex topic when all they want to do is get their network going :-). So for the sake of this explanation we can assume that if we wanted to specify an IP address and a netmask, it could be accomplished by either specifying each separately (IP address = 10.1.1.17 and netmask = 255.255.255.0) or in CIDR format (10.1.1.1/24)
Distinguish Dynamic from Static
The other service that our DHCP server will allow is the setting of a range of addresses that can be assigned dynamically. In other words we will be able to declare that the range from 10.1.1.20 to 10.1.1.255 can be dynamically assigned which leaves 10.1.1.0 to 10.1.1.19 which can be set as static addresses.
You might also be able to reserve an IP address on your modem / router. To do this you will need to know what the MAC (or hardware address) of the Raspberry Pi is. To find the hardware address on the Raspberry Pi type;
This will produce an output which will look a little like the following;
The figures 00:08:C7:1B:8C:02 are the Hardware or MAC address.
Because there are a huge range of different DHCP servers being run on different home networks, I will have to leave you with those descriptions and the advice to consult your devices manual to help you find an IP address that can be assigned as a static address. Make sure that the assigned number has not already been taken by another device. In a perfect World we would hold a list of any devices which have static addresses so that our Pi’s address does not clash with any other device.
For the sake of the explanation here we will assume that the address 10.1.1.120 is available.
Default Gateway
Before we start configuring we will need to find out what the default gateway is for our network. A default gateway is an IP address that a device (typically a router) will use when it is asked to go to an address that it doesn’t immediately recognise. This would most commonly occur when a computer on a home network wants to contact a computer on the Internet. The default gateway is therefore typically the address of the modem / router on your home network.
We can check to find out what our default gateway is from Windows by going to the command prompt (Start > Accessories > Command Prompt) and typing;
This should present a range of information including a section that looks a little like the following;
The default router gateway is therefore ‘10.1.1.1’.
Lets edit the dhcpcd.conf file
On the Raspberry Pi at the command line we are going to start up a text editor and edit the file that holds the configuration details for the network connections.
The file is /etc/dhcpcd.conf. That is to say it’s the dhcpcd.conf file which is in the etc directory which is in the root (/) directory.
To edit this file we are going to type in the following command;
The nano file editor will start and show the contents of the dhcpcd.conf file which should look a little like the following;
for dhcpcd.
# See dhcpcd.conf(5) for details.
# Allow users of this group to interact with dhcpcd via the control socket.
#controlgroup wheel
# Inform the DHCP server of our hostname for DDNS.
hostname
# Use the hardware address of the interface for the Client ID.
clientid
# or
# Use the same DUID + IAID as set in DHCPv6 for DHCPv4 ClientID per RFC4361.
#duid
# Persist interface configuration when dhcpcd exits.
persistent
# Rapid commit support.
# Safe to enable by default because it requires the equivalent option set
# on the server to actually work.
option rapid_commit
# A list of options to request from the DHCP server.
option domain_name_servers, domain_name, domain_search, host_name
option classless_static_routes
# Most distributions have NTP support.
option ntp_servers
# Respect the network MTU. This is applied to DHCP routes.
option interface_mtu
# A ServerID is required by RFC2131.
require dhcp_server_identifier
# Generate Stable Private IPv6 Addresses instead of hardware based ones
slaac private
# Example static IP configuration:
#interface eth0
#static ip_address=192.168.0.10/24
#static ip6_address=fd51:42f8:caae:d92e::ff/64
#static routers=192.168.0.1
#static domain_name_servers=192.168.0.1 8.8.8.8 fd51:42f8:caae:d92e::1
# It is possible to fall back to a static IP if DHCP fails:
# define static profile
#profile static_eth0
#static ip_address=192.168.1.23/24
#static routers=192.168.1.1
#static domain_name_servers=192.168.1.1
# fallback to static profile on eth0
#interface eth0
#fallback static_eth0
The file actually contains some commented out sections that provide guidance on entering the correct configuration.
We are going to add the information that tells the network interface to use eth0 at our static address that we decided on earlier (10.1.1.120) along with information on the netmask to use (in CIDR format) and the default gateway of our router. To do this we will add the following lines to the end of the information in the dhcpcd.conf file;
Here we can see the IP address and netmask (static ip_address=10.1.1.120/24), the gateway address for our router (static routers=10.1.1.1) and the address where the computer can also find DNS information (static domain_name_servers=10.1.1.1).
Once you have finished press ctrl-x to tell nano you’re finished and it will prompt you to confirm saving the file. Check over your changes and then press ‘y’ to save the file (if it’s correct). It will then prompt you for the file-name to save the file as. Press return to accept the default of the current name and you’re done!
To allow the changes to become operative we can type in;
This will reboot the Raspberry Pi and we should see the (by now familiar) scroll of text and when it finishes rebooting you should see;
Which tells us that the changes have been successful (bearing in mind that the IP address above should be the one you have chosen, not necessarily the one we have been using as an example).